blobs专题
sklearn学习笔记(1)--make_blobs
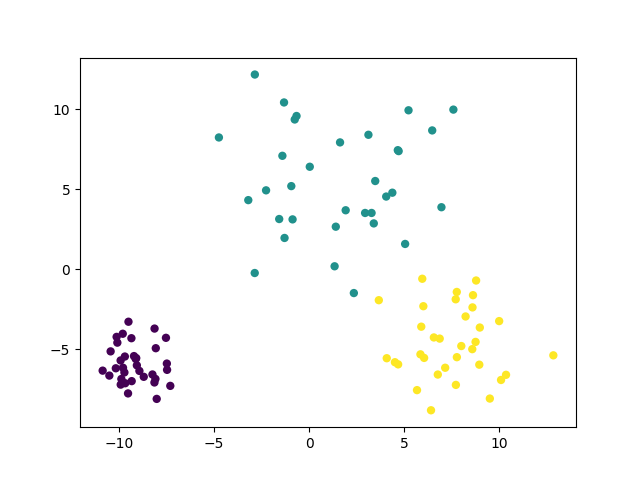
make_blobs聚类数据生成器简介 scikit中的make_blobs方法常被用来生成聚类算法的测试数据,直观地说,make_blobs会根据用户指定的特征数量、中心点数量、范围等来生成几类数据,这些数据可用于测试聚类算法的效果。 make_blobs方法: sklearn.datasets.make_blobs(n_samples=100, n_features=2,cente

NEXUS 3.X 通过BLOBS全量或部分 备份和迁移
说明:这里的E:\nexus-3.15.0-01-win64\nexus-3.15.0-01\是我安装NEXUS的位置,更换为相应的安装目录即可 步骤一、在迁出机器,备份databases 1、在管理界面System-Tasks界面,点击“Create task” 2、选择Admin-Export databases for backup 3、填写好名称,保存路径,Task frequ
Python-sklearn.datasets-make_blobs
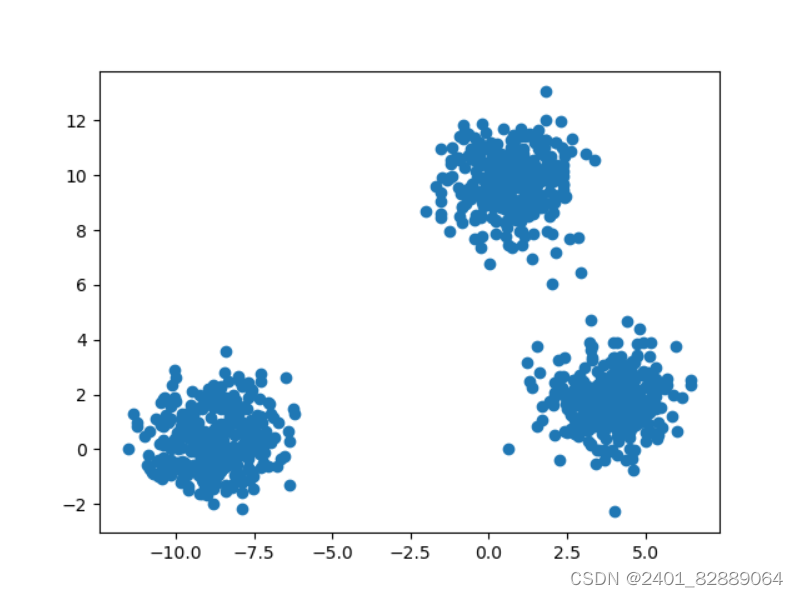
sklearn.datasets.make_blobs()函数形参详解 """@Title: datasets for regression@Time: 2024/3/5@Author: Michael Jie"""from sklearn import datasetsimport matplotlib.pyplot as plt# 产生服从正态分布的聚类数据x, y,

sklearn.datasets.make_blobs的使用
sklearn中的make_blobs模块用于为聚类生成一些带标签的数据 sklearn.datasets.make_blobs(n_samples=100, n_features=2, centers=None, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=None) 参数解释: n_sampl
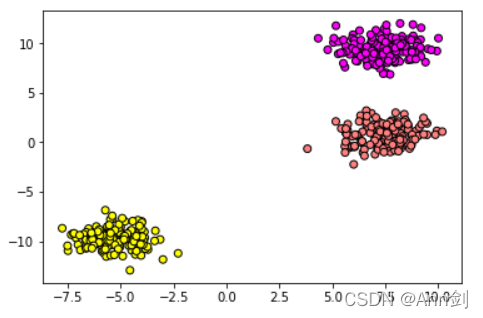
【Python】data=make_blobs(n_samples=500,centers=5,random_state=4)
Python语句解释: data=make_blobs(n_samples=500,centers=5,random_state=4)X,y=data#将生成的数据集进行可视化plt.scatter(X[:,0],X[:,1],c=y,cmap=plt.cm.spring,edgecolor='k')#camp也就是colormap,可以理解为接受一个数值,输出一个指定的颜色的字典pl