blip专题

技术前沿 |【大模型BLIP-2的多模态训练】
大模型BLIP-2的多模态训练 一、引言二、BLIP-2模型概述三、多模态训练成本问题四、冻结预训练好的视觉语言模型参数的优势五、冻结预训练好的视觉语言模型参数的方法 一、引言 随着人工智能技术的飞速发展,大型多模态模型如BLIP-2在多个领域取得了显著的成果。然而,其高昂的训练成本成为了制约其广泛应用的一大难题。为了降低训练成本,本文提出了冻结预训练好的视觉语言模型参数的策
BLIP和BLIP2 论文讲解
文章目录 BLIPIntroductionMethod模型架构预训练目标字幕和过滤(Capfilt) BLIP2IntroductionMethod模型结构Q-Former预训练第一阶段Q-Former预训练第二阶段 BLIP 论文: 《BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-L
BLIP-2论文精读
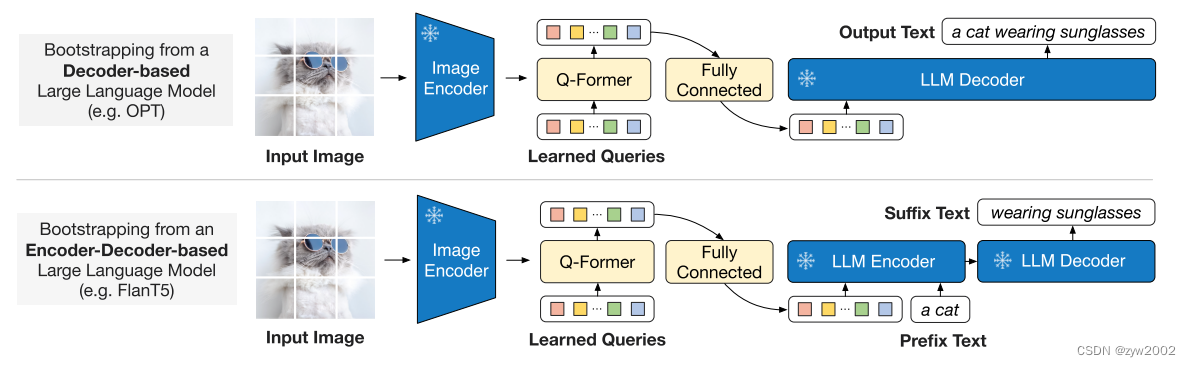
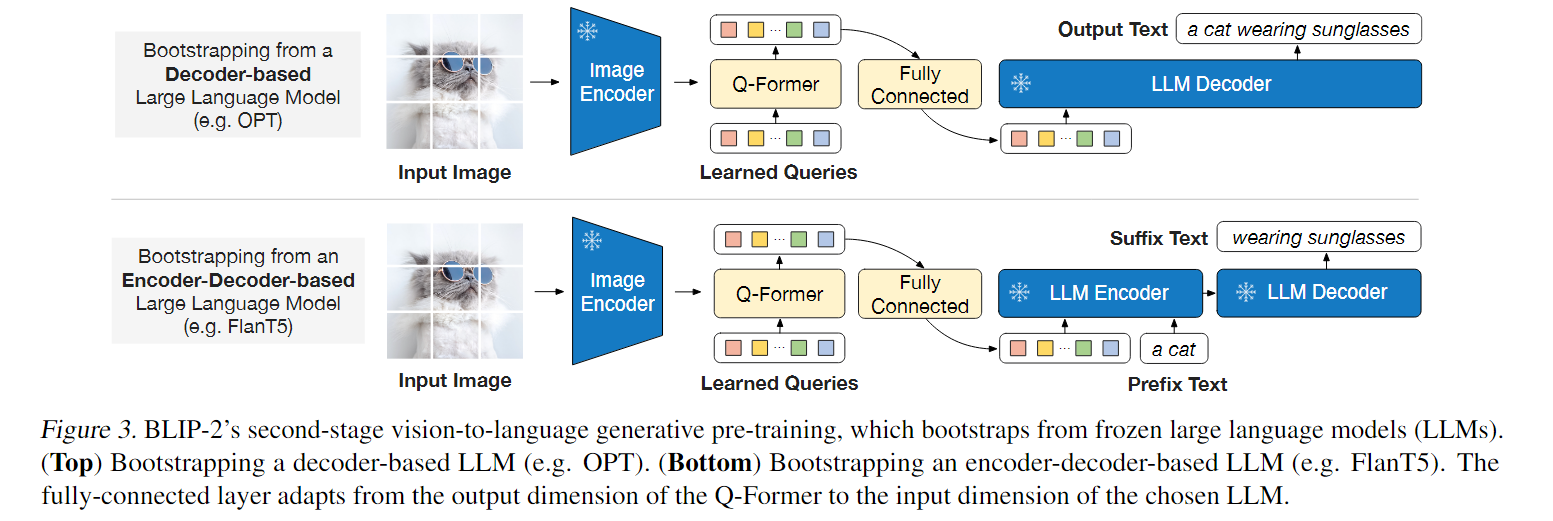
概述 由于大规模模型的端到端训练,视觉和语言预训练的成本越来越高,BLIP-2是一种通用且高效的预训练策略,可以从现成的冻结的预训练图像编码器和冻结的大型语言模型引导视觉语言预训练。 模型主体框架 BLIP-2采用了一个轻量级的查询转换器Q-Former弥补了模态上的差距。该转换器分两个阶段进行预训练:第一个阶段从冻结的图像编码器中引导视觉语言表示学习;第二个阶段从一个冻结的语言模型中引
多模态视觉语言模型:BLIP和BLIP2
1. BLIP BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation BLIP的总体结构如下所示,主要包括三部分: 单模态编码器(Image encoder/Text encoder):分别进行图像和文本编码,文本编码器和BERT一样在输

【论文极速读】 指令微调BLIP:一种对指令微调敏感的Q-Former设计
【论文极速读】 指令微调BLIP:一种对指令微调敏感的Q-Former设计 FesianXu 20240330 at Tencent WeChat search team 前言 之前笔者在[1]中曾经介绍过BLIP2,其采用Q-Former的方式融合了多模态视觉信息和LLM,本文作者想要简单介绍一个在BLIP2的基础上进一步加强了图文指令微调能力的工作——InstructBLIP,希

coca、blip、blip2在image caption中的实验效果对比
coca脚本 # pip install open_clip_torch transformersimport open_clipimport torchfrom PIL import Imagemodel, _, transform = open_clip.create_model_and_transforms(model_name="coca_ViT-L-14",pretrained=
论文阅读——BLIP
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation (1)单模态编码器,它分别对图像和文本进行编码。图像编码器用ViT,并使用附加的 [CLS] 标记来表示全局图像特征。文本编码器与 BERT 相同(Devlin et al., 2
AI绘画原理解析:从CLIP、BLIP到DALLE、DALLE 2、DALLE 3、Stable Diffusion
前言 终于开写本CV多模态系列的核心主题:stable diffusion相关的了,为何执着于想写这个stable diffusion呢,源于三点 去年stable diffusion和midjourney很火的时候,就想写,因为经常被刷屏,但那会时间错不开去年11月底ChatGPT出来后,我今年1月初开始写ChatGPT背后的技术原理,而今年2月份的时候,一读者“天之骄子呃”在我这篇Chat
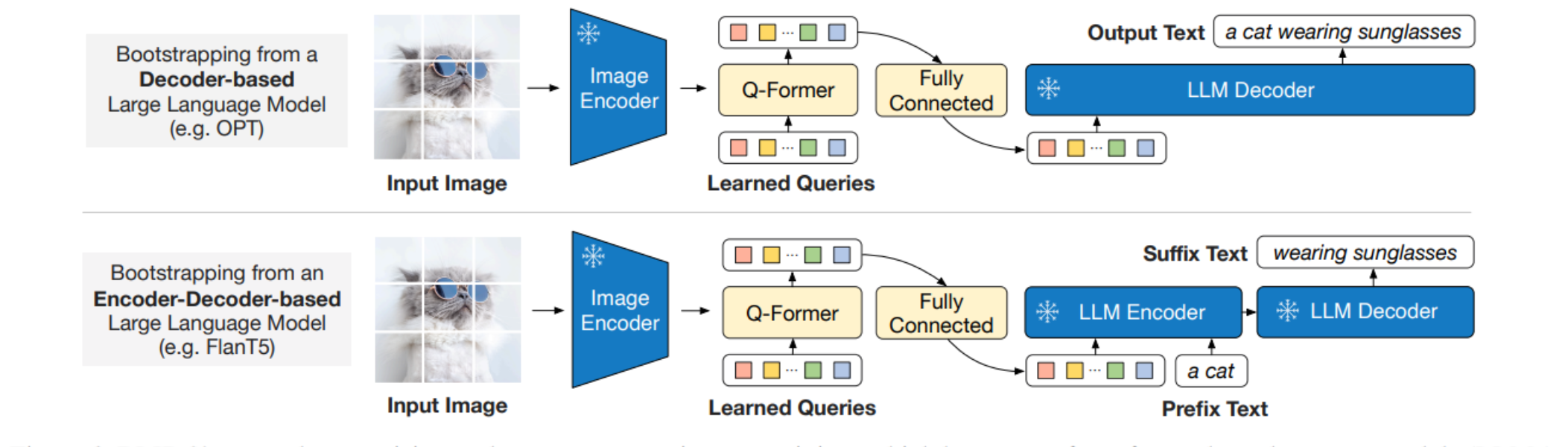
BLIP-2:低计算视觉-语言预训练大模型
BLIP-2 BLIP 对比 BLIP-2BLIPBLIP-2如何在视觉和语言模型之间实现有效的信息交互,同时降低预训练的计算成本?视觉语言表示学习视觉到语言的生成学习模型架构设计 总结主要问题: 如何在计算效率和资源有限的情况下,有效地结合冻结的图像编码器和大型语言模型,来提高在视觉语言任务上的性能?子解法1: 视觉语言表示学习子解法2: 视觉到语言的生成学习子解法3: 模型预训练
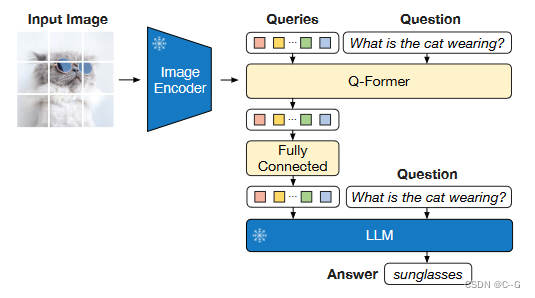
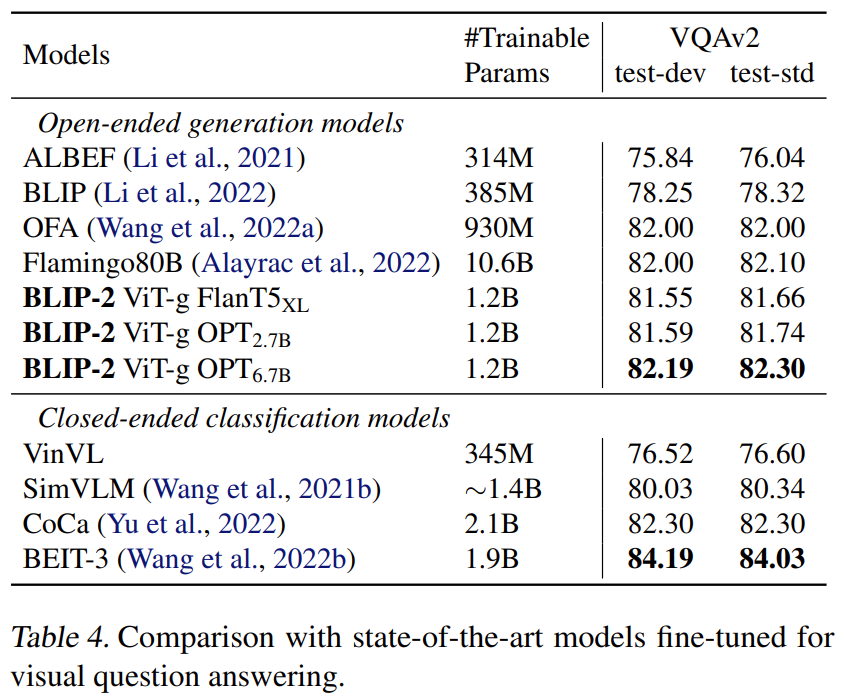
论文阅读——BLIP-2
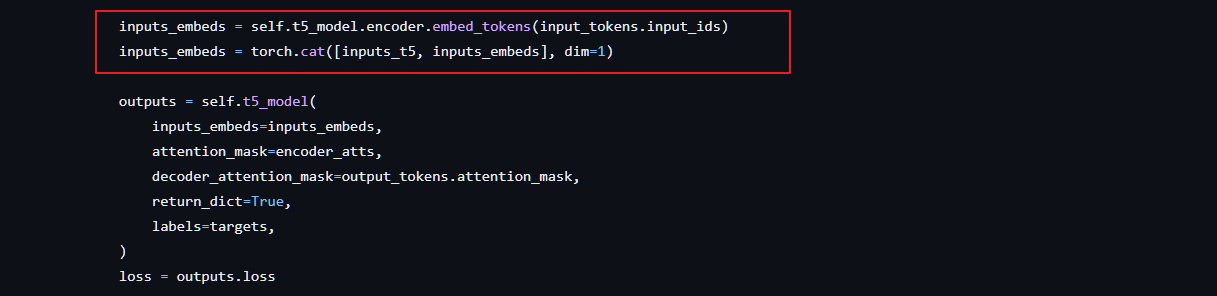
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models 1 模型 在预训练视觉模型和预训练大语言模型中间架起了一座桥梁。两阶段训练,视觉文本表示和视觉到语言生成学习。 Q-Former由两个转换器子模块组成,它们共享相同的自注意层:(1)与

多模态论文阅读之BLIP
BLIP泛读 TitleMotivationContributionModel Title BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation Motivation 模型角度:clip albef等要么采用encoder-
多模态论文阅读之BLIP
BLIP泛读 TitleMotivationContributionModel Title BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation Motivation 模型角度:clip albef等要么采用encoder-

CV多模态和AIGC原理解析:从CLIP、BLIP到DALLE 3、Stable Diffusion、MDJ
前言 终于开写本CV多模态系列的核心主题:stable diffusion相关的了,为何执着于想写这个stable diffusion呢,源于三点 去年stable diffusion和midjourney很火的时候,就想写,因为经常被刷屏,但那会时间错不开去年11月底ChatGPT出来后,我今年1月初开始写ChatGPT背后的技术原理,而今年2月份的时候,一读者“天之骄子呃”在我这篇Chat
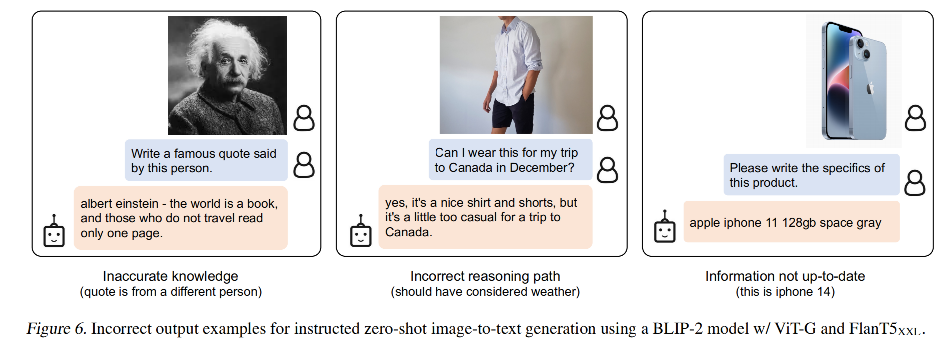
【多模态】6、BLIP-2 | 使用 Q-Former 连接冻结的图像和语言模型 实现高效图文预训练
文章目录 一、背景二、方法2.1 模型结构2.2 从 frozen image encoder 中自主学习 Vision-Language Representation2.3 使用 Frozen LLM 来自主学习 Vision-to-Language 生成2.4 Model pre-training 三、效果四、局限性 论文:BLIP-2: Bootstrapping La
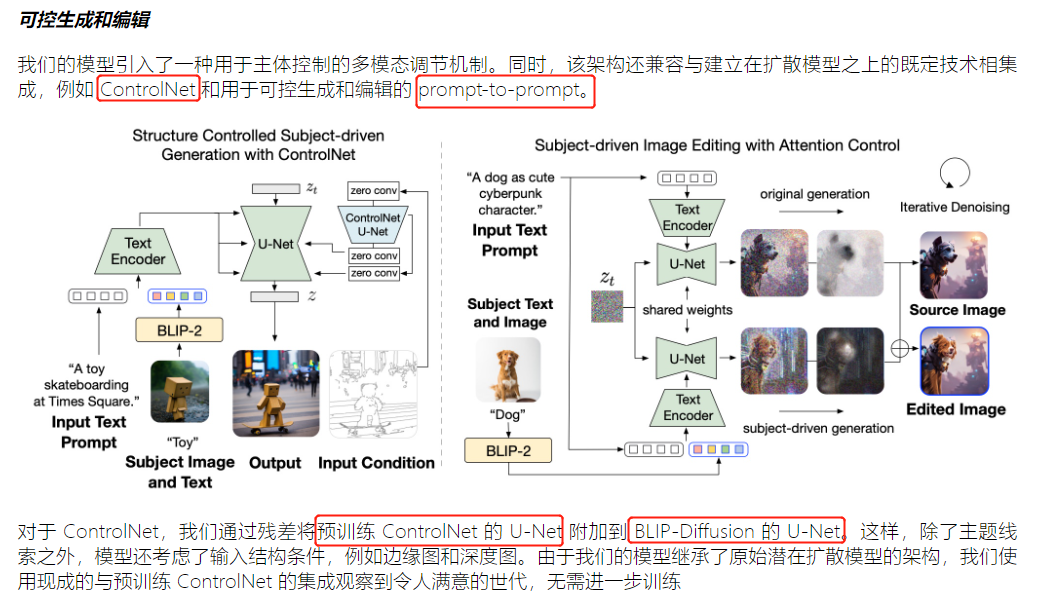
【论文解读系列】Blip-2:引导语言图像预训练具有冻结图像编码器和大型语言模型
Blip-2 BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models BLIP-2:引导语言图像预训练具有冻结图像编码器和大型语言模型 (0) 总结&实测 总结:blip-2 最大的贡献在于,提出了一种新的视觉语言预训练范式,使得视觉语言预训

使用 BLIP-2 零样本“图生文”
本文将介绍来自 Salesforce 研究院的 BLIP-2 模型,它支持一整套最先进的视觉语言模型,且已集成入 🤗 Transformers。我们将向你展示如何将其用于图像字幕生成、有提示图像字幕生成、视觉问答及基于聊天的提示这些应用场景。 BLIP-2 模型文档:https://hf.co/docs/transformers/main/en/model_doc/blip-2 Transfo

