bitsandbytes专题

flux bitsandbytes bnb量化;diffusers 15G显卡加载使用
使用bitsandbytes进行bnb量化 在线参考: https://colab.research.google.com/gist/sayakpaul/4af4d6642bd86921cdc31e5568b545e1/scratchpad.ipynb 安装包 !pip install -U accelerate transformers bitsandbytes !pip install g

bitsandbytes使用错误:CUDA Setup failed despite GPU being available
参考:https://huggingface.co/docs/bitsandbytes/main/en/installation 报错信息 ======================

windows上运行bitsandbytes报错
(大语言模型) transformers 目前支持两种量化方式:bitsandbytes 和 autogptq 一、报错信息 bin C:\Users\win10\anaconda3\envs\qlora\Lib\site-packages\bitsandbytes\libbitsandbytes_cpu.soFalseC:\Users\win10\anaconda3\envs\qlo
启动百川大模型错误解决:ModuleNotFoundError: No module named ‘bitsandbytes‘
1.错误信息 Traceback (most recent call last):File "/root/.cache/huggingface/modules/transformers_modules/Baichuan2-13B-Chat-lora23/modeling_baichuan.py", line 735, in quantizefrom .quantizer import quant
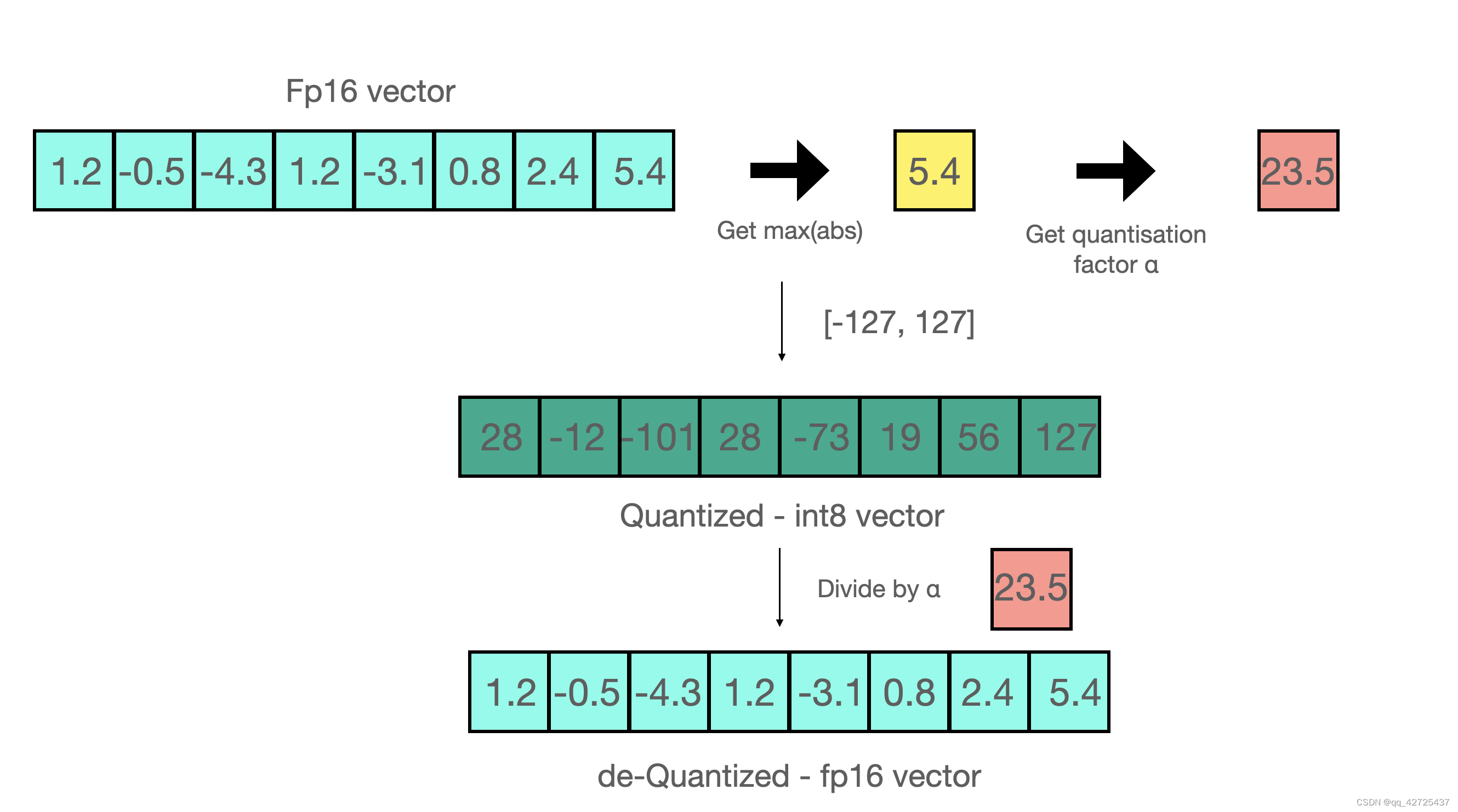
【hugging face】bitsandbytes中8 bit量化的理解
8 位量化使数十亿参数规模的模型能够适应更小的硬件,而不会降低性能。 8 位量化的工作原理如下: 1.从输入隐藏状态中按列提取较大值(离群值)。 2.对 FP16 中的离群值和 int8 中的非离群值执行矩阵乘法。 3.改变非异常值结果以将值拉回到 FP16,并将它们添加到 FP16 中的异常值结果中。 因此,本质上,我们执行矩阵乘法以节省精度,然后将非异常值结果拉回到 FP16,而非异
Windows 安装 flash-attention 和 bitsandbytes
首先保证cuda版本为12.1,torch版本为2.1.0及以上,python版本3.10以上 从此处下载最新版的whl,https://github.com/jllllll/bitsandbytes-windows-webui/releases/tag/wheels,通过whl来安装bitsandbytes 从此处下载最新版的whl, https://github.com/bdashore
用 bitsandbytes、4 比特量化和 QLoRA 打造亲民的 LLM
众所周知,LLM 规模庞大,如果在也能消费类硬件中运行或训练它们将是其亲民化的巨大进步。我们之前撰写的 LLM.int8 博文 展示了我们是如何将 LLM.int8 论文 中的技术通过 bitsandbytes 库集成到 transformers 中的。在此基础上,我们不断努力以不断降低大模型的准入门槛。在此过程中,我们决定再次与 bitsandbytes 联手,支持用户以 4 比特精度运行任何