bandit专题

Chapter 2 multi-armed Bandit
引用:https://blog.csdn.net/mmc2015/article/details/51247677 https://blog.csdn.net/coffee_cream/article/details/58034628 https://blog.csdn.net/heyc861221/article/details/80129310 The most importa

n-armed bandit _ ucb1 algorithm
前言:家里发生了一些事情,所以又耽搁了一段时间,这周交的report都有点潦草,好在ucb1本身就不是一个很复杂的算法。 参考文献:《Bandit Algorithms for Website Optimization》 This week, I have studied one of the algorithms in the UCB falmily, which is called the

n-armed bandit_Gittins index
The complexity of solving MAB (multi-armed bandit) using Markov decision theory increases exponentially with the number of bandit processes. Instead of solving the n-dimensional MDP with the state-sp


Bandit:一款Python代码安全漏洞检测工具
工具介绍 Bandit这款工具可以用来搜索Python代码中常见的安全问题,在检测过程中,Bandit会对每一份Python代码文件进行处理,并构建AST,然后针对每一个AST节点运行相应的检测插件。完成安全扫描之后,Bandit会直接给用户生成检测报告。 工具安装 Bandit使用PyPI来进行分发,建议广大用户直接使用pip来安装Bandit。 创建虚拟环境(可选):中国菜刀 v
Overthewire wargame-bandit
文章目录 Bandit**Level 0->Level 1****Level 1-> Level 2****Level 2->Level 3****Level 3-> Level 4****Level 4->Level 5****Level 6 -> level 7**Level 7-> Level 8Level 8 -> Level 9Level 9-> Level 10Level 10-
Bandit 一种Python代码安全漏洞检测工具
工具介绍 Bandit这款工具可以用来搜索Python代码中常见的安全问题,在检测过程中,Bandit会对每一份Python代码文件进行处理,并构建AST,然后针对每一个AST节点运行相应的检测插件。完成安全扫描之后,Bandit会直接给用户生成检测报告。 工具安装 Bandit使用PyPI来进行分发,建议广大用户直接使用pip来安装Bandit。 创建虚拟环境(可选): virtua
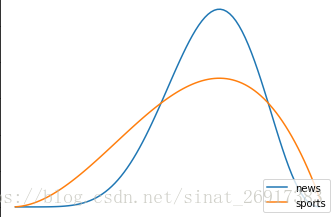
推荐系统︱基于bandit的主题冷启动在线学习策略
推荐系统里面有两个经典问题:EE问题和冷启动问题。 什么是EE问题?又叫exploit-explore问题。exploit就是:对用户比较确定的兴趣,当然要利用开采迎合,好比说已经挣到的钱,当然要花;explore就是:光对着用户已知的兴趣使用,用户很快会腻,所以要不断探索用户新的兴趣才行,这就好比虽然有一点钱可以花了,但是还得继续搬砖挣钱,不然花完了就得喝西北风。 除了bandit算法
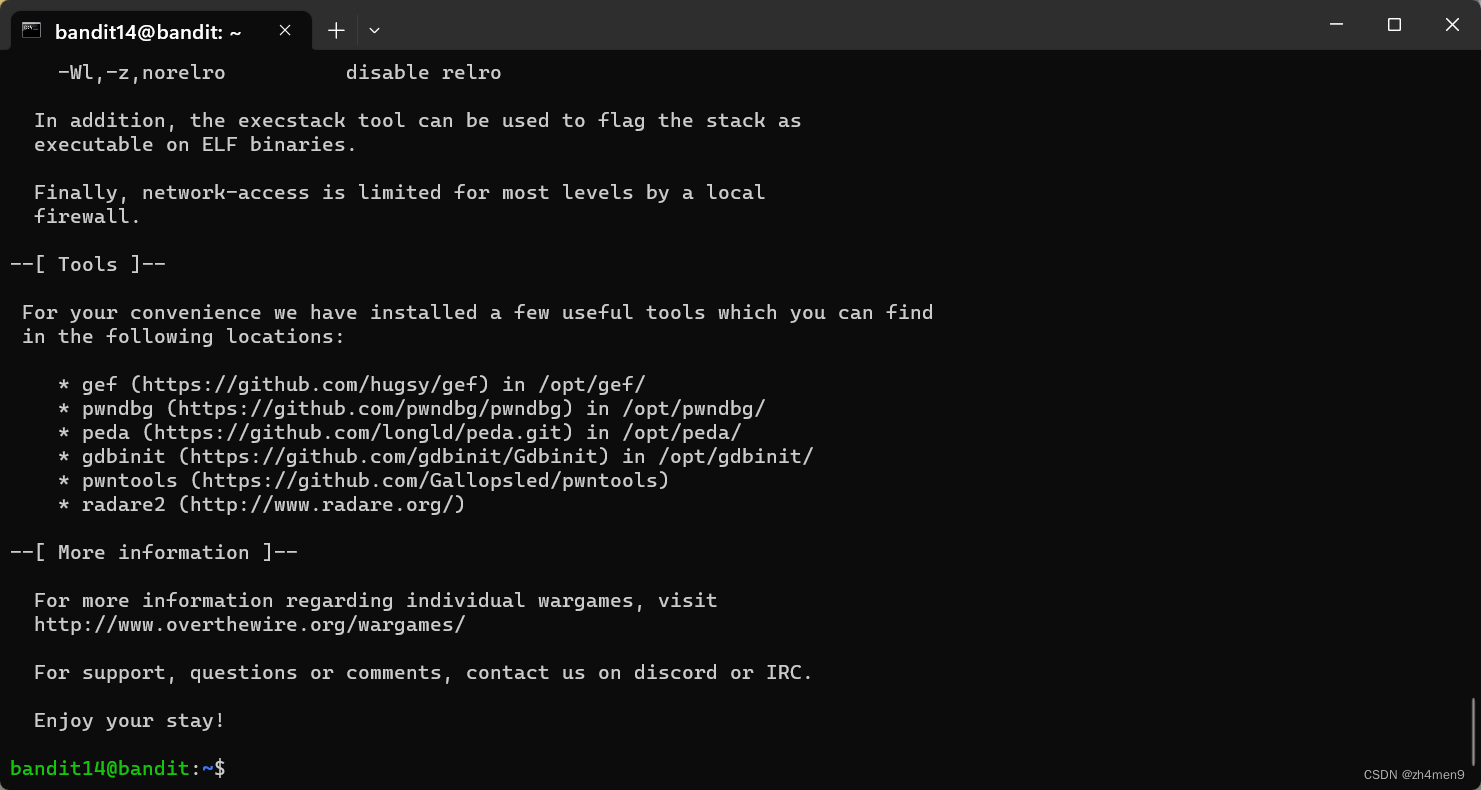
孩子还是有一颗网安梦——Bandit通关教程:Level 13 → Level 14
🕵️♂️ 专栏《解密游戏-Bandit》 🌐 游戏官网: Bandit游戏 🎮 游戏简介: Bandit游戏专为网络安全初学者设计,通过一系列级别挑战玩家,从Level0开始,逐步学习基础命令行和安全概念。玩家需通过阅读信息、使用命令和解决问题来完成每个级别。在不清楚时建议查阅手册、使用内建命令或搜索引擎,旨在培养初学者的基本技能。 📖 博客说明: 本系列博客记录个人通关教程,一起探索

孩子还是有一颗网安梦——Bandit通关教程:Level 12 → Level 13
🕵️♂️ 专栏《解密游戏-Bandit》 🌐 游戏官网: Bandit游戏 🎮 游戏简介: Bandit游戏专为网络安全初学者设计,通过一系列级别挑战玩家,从Level0开始,逐步学习基础命令行和安全概念。玩家需通过阅读信息、使用命令和解决问题来完成每个级别。在不清楚时建议查阅手册、使用内建命令或搜索引擎,旨在培养初学者的基本技能。 📖 博客说明: 本系列博客记录个人通关教程,一起探索
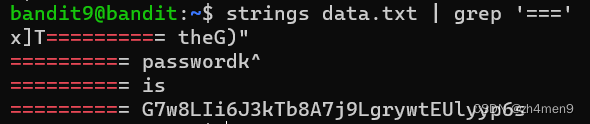
孩子还是有一颗网安梦——Bandit通关教程:Level 9 → Level 10
🕵️♂️ 专栏《解密游戏-Bandit》 🌐 游戏官网: Bandit游戏 🎮 游戏简介: Bandit游戏专为网络安全初学者设计,通过一系列级别挑战玩家,从Level0开始,逐步学习基础命令行和安全概念。玩家需通过阅读信息、使用命令和解决问题来完成每个级别。在不清楚时建议查阅手册、使用内建命令或搜索引擎,旨在培养初学者的基本技能。 📖 博客说明: 本系列博客记录个人通关教程,一起探索
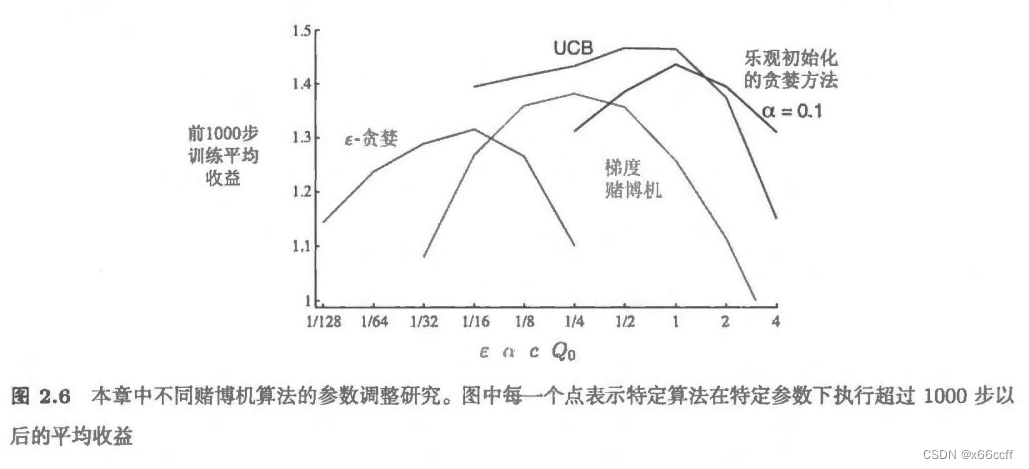
【强化学习-读书笔记】多臂赌博机 Multi-armed bandit
参考 Reinforcement Learning, Second Edition An Introduction By Richard S. Sutton and Andrew G. Barto 强化学习与监督学习 强化学习与其他机器学习方法最大的不同,就在于前者的训练信号是用来评估(而不是指导)给定动作的好坏的。 强化学习:评估性反馈 有监督学习:指导性反馈 价值函数
孩子还是有一颗网安梦——Bandit通关教程:Level 0 → Level 1
🕵️♂️ 专栏《解密游戏-Bandit》 🌐 游戏官网: Bandit游戏 🎮 游戏简介: Bandit游戏专为网络安全初学者设计,通过一系列级别挑战玩家,从Level0开始,逐步学习基础命令行和安全概念。玩家需通过阅读信息、使用命令和解决问题来完成每个级别。在不清楚时建议查阅手册、使用内建命令或搜索引擎,旨在培养初学者的基本技能。 📖 博客说明: 本系列博客记录个人通关教程,一起探索
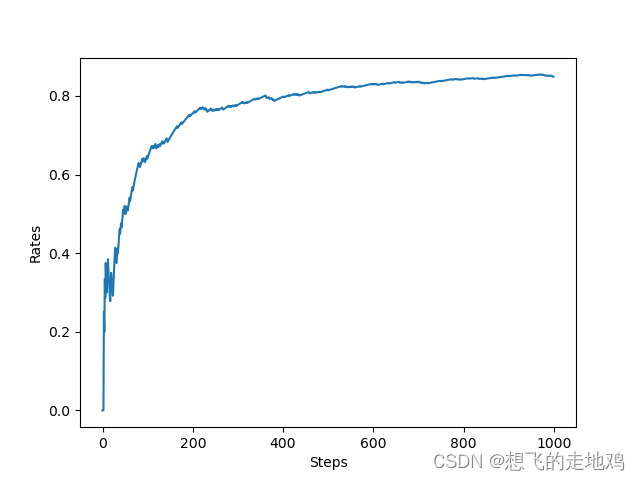
从零开始强化学习一:Bandit Problem
一:强化学习概述 强化学习是一种机器学习方法,旨在让智能体在与环境交互的过程中学会制定最优策略,以达到最大化累积奖励的目标。 在强化学习中,智能体需要学会从环境中感知状态,做出动作,并通过环境返回的奖励信号来更新自己的策略。通常情况下,智能体需要通过不断地尝试和反馈来优化策略,直到最终达到最优策略。 强化学习的关键概念包括: 智能体(Agent):类似动作执行者,游戏玩 环境(Envir