backpropagation专题
计算图上的微积分:Backpropagation
计算图上的微积分:Backpropagation 引言 Backpropagation (BP) 是使得训练深度模型在计算上可行的关键算法。对现代神经网络,这个算法相较于无脑的实现可以使梯度下降的训练速度提升千万倍。而对于模型的训练来说,这其实是 7 天和 20 万年的天壤之别。 除了在深度学习中的使用,BP 本身在其他的领域中也是一种强大的计算工具,例如从天气预报到分析数值的稳定性——只是

Unsupervised Domain Adaptation by Backpropagation 阅读笔记
链接:Unsupervised Domain Adaptation by Backpropagation笔记

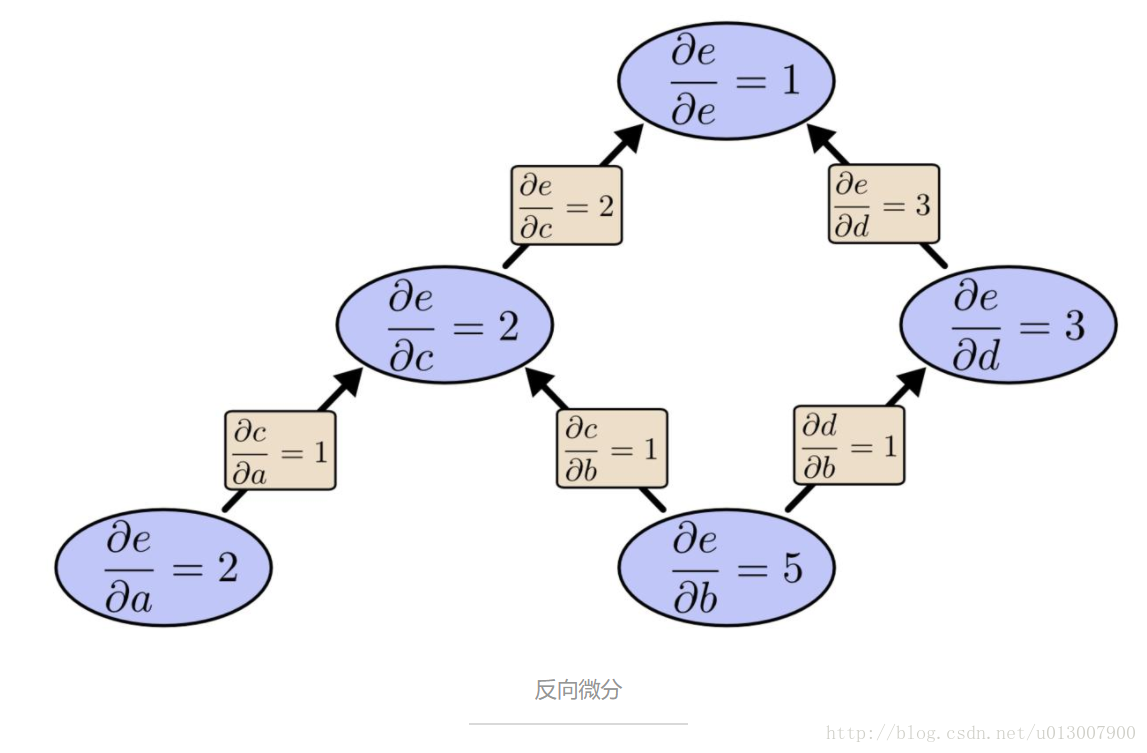
Backpropagation 算法的推导与直观图解
摘要 本文是对 Andrew Ng 在 Coursera 上的机器学习课程中 Backpropagation Algorithm 一小节的延伸。文章分三个部分:第一部分给出一个简单的神经网络模型和 Backpropagation(以下简称 BP)算法的具体流程。第二部分以分别计算第一层和第二层中的第一个参数(parameters,在神经网络中也称之为 weights)的梯度为例来解释 BP 算法
神经网络中的误差反向传播(Backpropagation)方法理解
想象一下,神经网络就像是一个复杂的迷宫,里面有许多交叉路口(神经元),每个路口都有指示牌告诉你往哪个方向走(权重),而你的目标是找到从入口到出口的最佳路径,使得从起点到终点的路程最短或达到某个最优目标。 神经网络简述 神经网络是由许多层神经元组成的,每一层都连接着下一层,就像是一层层的过滤器,每层都在对输入的信息做加工处理。每个神经元都会接收一些输入值,然后根据内部设置的权重(就像是它对每个输

深度学习中的反向传播方法—BackPropagation
最近在看深度学习的东西,一开始看的吴恩达的UFLDL教程,有中文版就直接看了,后来发现有些地方总是不是很明确,又去看英文版,然后又找了些资料看,才发现,中文版的译者在翻译的时候会对省略的公式推导过程进行补充,但是补充的又是错的,难怪觉得有问题。反向传播法其实是神经网络的基础了,但是很多人在学的时候总是会遇到一些问题,或者看到大篇的公式觉得好像很难就退缩了,其实不难,就是一个链式求导法则反复用。如果

unsupervised image segmentation by backpropagation-论文笔记
这是一个有趣的非监督分割方法 代码短小精悍 直接说算法 1.首先对原图进行超像素分割。 2.使用卷积网络进行正向传播。网络输出100channel,输出和输入大小相同。也就是说,每个输入像素对应输出100个像素。这100个channel相当于对每个像素点进行100类的分类。通过这100个channel的输出,我们可以得到每个像素的预测类别。 3.那么我们如何得到每个像素的label
![[机器学习入门] 李宏毅机器学习笔记-8(Backpropagation;反向传播算法)](https://img-blog.csdn.net/20170605235847174?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvc291bG1lZXRsaWFuZw==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
[机器学习入门] 李宏毅机器学习笔记-8(Backpropagation;反向传播算法)
[机器学习入门] 李宏毅机器学习笔记-8(Backpropagation;反向传播算法) PDFVIDEO 当我们要用gradient descent来train一个neural network,要怎么做? Gradient Descent backpropagation就是Gradient Descent。 Chain Rule(连锁法)

机器学习之BP神经网络精讲(Backpropagation Neural Network(附案例代码))
概念 BP神经网络(Backpropagation Neural Network)是一种常见的人工神经网络,它通过反向传播算法来训练网络,调整连接权重以最小化预测输出与实际输出之间的误差。这种网络结构包含输入层、隐藏层和输出层,使用梯度下降算法来优化权重。 结构: BP神经网络(Backpropagation Neural Network)是一种具有多层结构的前馈神经网络,它通过不断地调整权
如何直观地解释 backpropagation 算法
作者:Anonymous 链接:https://www.zhihu.com/question/27239198/answer/89853077 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 BackPropagation算法是多层神经网络的训练中举足轻重的算法。 简单的理解,它的确就是复合函数的链式法则,但其在实际运算中的意义比链式法则要大的多。 要回答题主这个
Resilient Backpropagation
Resilient Propagation (RPROP, 弹性传播) 对不同的问题都能用同一套参数, 而且收敛速度比 Backpropagation 快. 它对权重的修改不是正比于梯度 , 而是由梯度和上一轮梯度的符号决定, 如果两轮梯度符号相同, 修改值就乘以 1.2 (弹性加速), 如果两轮梯度符号相反, 修改值就乘以 -0.5 (弹性减速). Manhattan 相似于 RPROP 但