本文主要是介绍【Text2SQL 经典模型】X-SQL,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:X-SQL: reinforce schema representation with context
⭐⭐⭐⭐
Microsoft, arXiv:1908.08113
X-SQL 与 SQLova 类似,使用 BERT style 的 PLM 来获得 representation,只是融合 NL question 和 table schema 的信息的方式不太一样,也就是在利用 BERT-style 得到的 representation 后进一步的加工方式不一样。
X-SQL 先由 BERT-style PLM 生成 question 和 schema 的 representation,然后对 schema representation 做上下文信息的进一步加强,再交由 6 个 sub-task 分别构建出 SQL 的一部分,最终得到完整的 SQL。
一、X-SQL
整个架构包含三层:sequence encoder、context enhancing schema encoder 和 output layer。
1.1 Sequence Encoder:得到 PLM 的 representation
将 question 和 table headers 拼装成下面的形式(与 SQLova 的类似):

- 有一个特殊的空 column 被附加到每个 table schema 最后,也就是实际最后一个 column 后面会在加一个
[EMPTY] - 将
[CLS]重命名为[CTX],用来强调这里是捕获上下文信息,而非用于下游任务的 representation - SQLova 中的 segment embeddings 被替换为 type embeddings,这是我们为四种 types 学习的 embeddings:question、categorial column、numerical column 和 special empty column
另外,这里的 PLM 不是使用 BERT-Large 初始化的,而是使用 MT-DNN 初始化的,它与 BERT 架构相同,只是在多个 GLUE 任务上做过训练,从而能够得到更好的用于下游任务的 representation。
经过这一层,我们为 question 和 table schema 的每个 token 都利用 BERT-style PLM 生成一个 hidden state。
1.2 Context Enhanced Schema Encoder:加强 schema representation
在上一层 seq encoder 中,我们为 question 和 table headers 的每个 token 都得到一个 hidden state vector,在这一层,我们的 context enchanced schema encoder 通过用 h [ C T X ] h_{[CTX]} h[CTX] 来加强前面 encoder 的输出,从而得到每个 column 的一个新的 representation h C i h_{C_i} hCi,它代表 column i 的新 representation。
论文认为,尽管 BERT style 的 sequence encoder 在它的 output 中也捕捉到了一定的 context,但是这种 context influence 受限于 self-attention 的机制(它倾向于关注某个特定 region 从而缺少全局信息),所以这里使用带有全局信息的 [CTX] 的 hidden state 来加强 representation。
这里的具体做法就是,将 column i 的所有 token 的 hidden state 和 h [ C T X ] h_{[CTX]} h[CTX] 一起输入到一个 Attention 层中,得到加强后的新的 column i i i 的 representation:
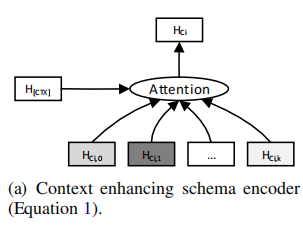
经过这一层 encoder,我们得到了上下文增强的 schema representation,也就是每个 column 的新 representation。
这一步的做法也体现出 X-SQL 与 SQLova 的区别,这一层的 “context enchanced schema encoder” 和 SQLova 中引入的 column-attention 机制都是为了相同的目标:更好地对齐 question 和 table schema,但两者的实现思路却不同:
- column-attention 通过将 column 作为条件来改变 question 的编码
- context enchanced schema encoder 认为 BERT-style 的 encoder 已经足够好了,只是基于此并试图使用
[CTX]中捕获的全局上下文信息来得到一个更好的 representation。
1.3 Output Layer:完成各 sub-task 生成 SQL
这一层借助 sequence encoder 输出的 hidden states 和 context enchanced schema encoder 输出的 h C 1 h_{C_1} hC1、 h C 2 h_{C_2} hC2、…、 h [ E M P T Y ] h_{[EMPTY]} h[EMPTY] 来生成 SQL。这里的思路也是基于 SQL sketch 并填充 slots。
这一步的任务被分解成了 6 个子任务,每个子任务预测最终 SQL 程序的一部分。
1.3.1 用来修正 schema representation 的 sub-network
首先,这里引入了一个 sub-network 用来调整 schema representation with context,具体来说,就是分别对 H [ C T X ] H_{[CTX]} H[CTX] 和 H C i H_{C_i} HCi 做一个仿射变换,再加起来经过一个 LayerNorm 得到 r C i r_{C_i} rCi(column i 一个修正后的 representation),图示如下:

公式如下:
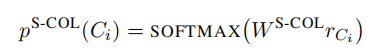
注意,这个 sub-network 在每个 sub-task 中都是独立训练的,也就是每个 sub-task 得到的 r C i r_{C_i} rCi 是不同的,这也体现了这个 sub-network 就是针对一个具体 task 来修正 schema representation。
之后,各个 sub-task 就可以基于我们之前得到的 vectors 和 r C i r_{C_i} rCi 来做了。
1.3.2 sub-task 1:S-COL
S-COL 任务是预测 SELECT 语句中的 columns,这其实就是计算各个 columns 的一个概率,计算方式如下:
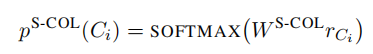
可以看到,这里只使用了 r C i r_{C_i} rCi,另外的 W W W 是一个可训练参数。
1.3.3 sub-task 2:S-AGG
直觉来说,aggregator 的选择会依赖所选中的 column 的类型,比如 aggregator MIN 只能被用于数字类型的 column。为了实现这个直觉,这个 task 在做 aggregator 分类时,会利用到 column type 的 embedding:
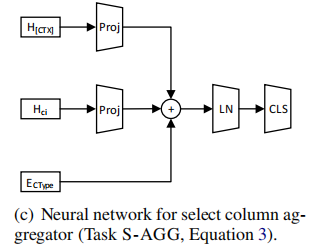
具体公式可以参考原论文
1.3.4 其他 sub-task
其他 sub-task 共同确定出 WHERE 部分,这里可以具体参考原论文,整体思路是差不多的。
二、总结
通过以上改进,X-SQL 在表现 WikiSQL 上的表现提升到 90% 以上,超过了 SQLova:
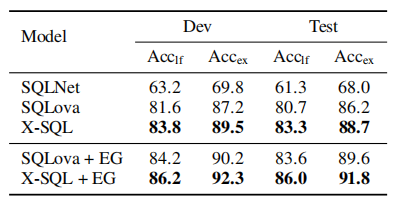
本文对 BERT-style 生成的 representation 的进一步的加工利用值得研究学习。
这篇关于【Text2SQL 经典模型】X-SQL的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





