本文主要是介绍AGI技术与原理浅析:曙光还是迷失?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:回顾以往博客文章,最近一次更新在2020-07,内容以机器学习、深度学习、CV、Slam为主,顺带夹杂个人感悟。笔者并非算法科班出身,本科学制药、研究生学金融,最原始的算法积累都来源于网络,当时更新博客的缘由无非是“取自网络、用于网络”。自2022年12月ChatGPT横空出世,毅然投入“AGI”大军,对大语言、多模态、RAG、Agent多有涉猎,并希望通过继续更新博客,影响更多同好共同奔赴“AGI 终局”。本篇为新时期第一篇,相当于是AGI系列文章的综述了,后面会不定期更新,欢迎大家共同研究、讨论、进步,本人微信号(wuyang9647),人多后再拉群。
背景
2012年,后来的计算机图灵奖(名人堂级)得主Hinton和他的学生们(包括未来OpenAI的灵魂Ilya)做出了一项令业界震惊的工作,他们推出的神经网络AlexNet对图像的识别准确率第一次达到了人类的水平,远远超出之前的结果,这个结果推动了业界对深度学习追捧的十年,也诞生了很多人工智能独角兽公司,在中国就有商汤、旷世、依图、云从四小龙,都是以图像识别为主业方向。由于这项技术商业变现的局限性,并没有超级公司真正诞生出来(自动驾驶原本是可能方向,但自动驾驶除了依赖图像识别,也依赖即时决策)。商业上对AI的渴求,在巨头公司中诞生了小度、天猫精灵、Siri、Cortana等AI助理产品,大家使用后发现,这些助理达不到实际用户的需求,被戏称为"人工智障",大家对AI颇为失望,AI逐渐被冷落,进入惨淡发展期。
2022年,ChatGPT横空出世。它良好的交互体验让大家眼前一亮,用户感觉是在跟真正的人对话了,远远超出之前"人工智障"的最高水平,第一次达到了图灵测试水准。
随着大模型技术的迅猛发展,AGI(通用人工智能)的讨论再次成为热点。大模型的崛起让我们看到了AGI的曙光,仿佛触手可及。国际上,OpenAI引领潮流,谷歌、微软等巨头纷纷跟进,推动AI在搜索、PC、手机等领域的变革,为AGI发展注入强大动力。国内方面,科技巨头与新创企业并驾齐驱,智谱、MoonShot等提出独特见解与解决方案,刘知远教授的大规模预训练方向更是奠定坚实基础。在此背景下,我们需重新审视AGI,深入了解技术原理,关注前沿动态,正视不足与局限,以更好地利用AI技术并洞悉AGI发展方向。
一、何为AGI
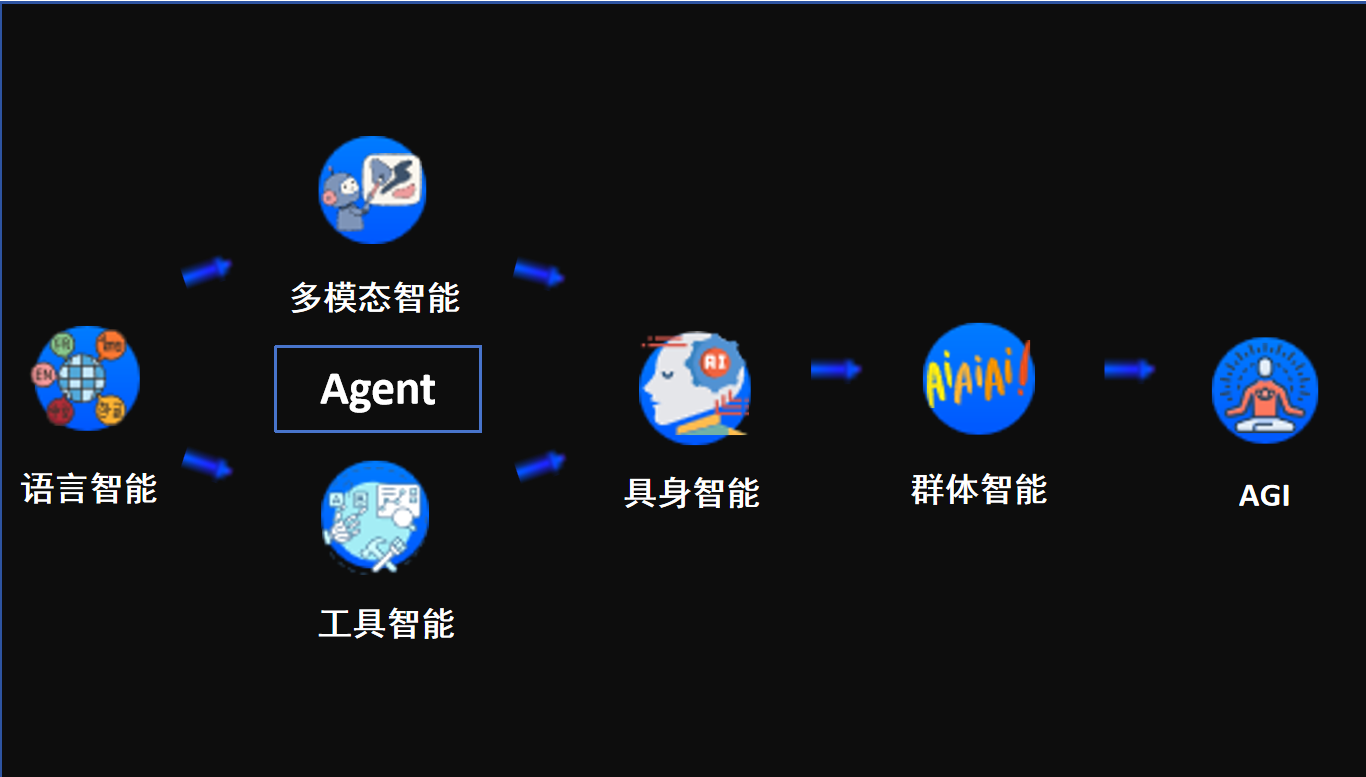
清华刘知远教授定义的“AGI具象化实现路径”
强人工智能(Strong AI)或通用人工智能(Artificial General Intelligence,简称AGI),是指那些拥有与人类相似甚至超越人类智能水平的人工智能系统。这类AI系统能够全方位地模拟和展现正常人类的智能行为,不仅限于逻辑推理、情感理解,还包括知识获取与自我意识等多个层面。其核心在于深度整合了人类的意识、感性、知识及自觉等特征,使机器具备了更为全面、灵活且自主性强的智能能力。这种智能新形态不仅极大地推动了人工智能领域的发展,更深刻地改变了我们对“智能”这一概念的认知和定义。
二、技术井喷
1、语言智能
最新大语言模型清单
不可否认,人类智能与我们的语言紧密相连。原因在于,抽象是构建逻辑的关键基石,而逻辑则是智能得以形成和发展的基础。语言,作为对世界的一种抽象描述方式,正是通过这套逻辑体系来支撑我们的智能。从更宏观的角度来看,抽象、逻辑、推理与预测这四个环节紧密相连,共同构成了智能的基石。人脑的抽象能力主要基于对概念的语言表达,因此,语言在智能的形成与发展中扮演着至关重要的角色。
值得注意的是,这里所提到的“逻辑”,特指人脑通过抽象能力捕捉到的事物内在规律。这种逻辑依赖于我们的抽象能力才能得以显现。与此同时,客观逻辑则代表了事物之间所固有的联系,这些联系作为一种客观存在,可以被我们抽象成为逻辑形式。
2、多模态智能
- VisualGLM-6B
- 地址:https://github.com/THUDM/VisualGLM-6B
- 简介:一个开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;
- CogVLM
- 地址:https://github.com/THUDM/CogVLM
- 简介:一个强大的开源视觉语言模型(VLM)。
- VisCPM
- 地址:https://github.com/OpenBMB/VisCPM
- 简介:一个开源的多模态大模型系列,支持中英双语的多模态对话能力(VisCPM-Chat模型)和文到图生成能力(VisCPM-Paint模型)。
- Visual-Chinese-LLaMA-Alpaca
- 地址:GitHub - airaria/Visual-Chinese-LLaMA-Alpaca: 多模态中文LLaMA&Alpaca大语言模型(VisualCLA)
- 简介:基于中文LLaMA&Alpaca大模型项目开发的多模态中文大模型。VisualCLA在中文LLaMA/Alpaca模型上增加了图像编码等模块,使LLaMA模型可以接收视觉信息。
- LLaSM
- 地址:https://github.com/LinkSoul-AI/LLaSM
- 简介:第一个支持中英文双语语音-文本多模态对话的开源可商用对话模型。
- Qwen-VL
- 地址:https://github.com/QwenLM/Qwen-VL
- 简介:是阿里云研发的大规模视觉语言模型,可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。
多模态大模型部分清单与项目地址
显然,人脑之所以能够处理复杂环境,得益于其多感官支持的多模态输入能力。人类智能正是经过数十年的多模态训练而逐渐形成的。因此,在追求类人智能的道路上,大模型也将从多模态训练中汲取巨大力量。
多模态训练的核心意义在于,它能够从多路信息中提炼出不同维度的结构与关系,进而揭示出丰富多元的逻辑联系。实际上,人类的身体可以被视为一种高效的多模态信息输入设备,这也是具身智能的精髓所在。具体来说,人类智能的形成依赖于对人脑结构的塑造,而这种塑造又离不开对现实世界的精准建模。建模过程则依赖于对多模态信息的有效抽象,最终形成的颅内模型能够提升对未来预测的准确性与精确性,这正是人类智能的基石。
3、工具智能
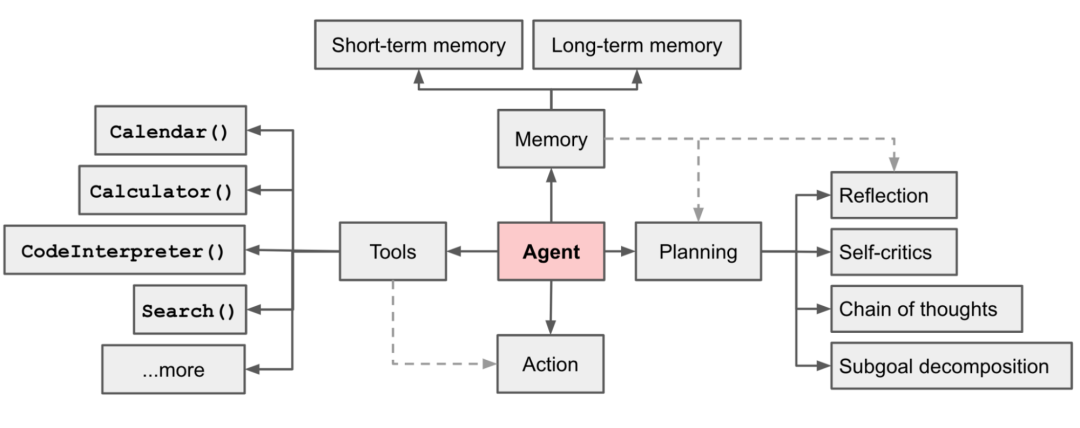
智能体(Agent)经典框架
Agent的核心决策逻辑在于,它能让LLM(大型语言模型)根据不断变化的环境信息,选择执行具体工具或对结果作出判断,进而对环境产生影响。这一过程通过多轮迭代不断重复,直至目标达成。
其决策流程可概括为三个步骤:感知(Perception)、规划(Planning)和行动(Action)。感知是Agent从环境中收集信息并提取相关知识的能力;规划则是Agent为实现某一目标而进行的决策过程;最后,行动则是基于环境和规划作出的具体动作。这三个步骤环环相扣,共同构成了Agent的智能决策体系。
三、大模型三定律
1、Scaling Law

计算量、数据集、参数规模与模型效果的关系
Scaling law的研究深入探讨了模型性能的缩放定律,揭示了模型大小、数据集规模以及训练时所用计算量与交叉熵损失之间的紧密关联。这项研究跨越了七个数量级,通过简单的方程式,我们便能洞察到模型与数据集大小对过拟合现象的潜在影响,以及模型规模如何左右训练速度。这些发现为我们在有限的计算资源下,如何选定最佳的模型训练方案提供了有力的理论支撑。
这些研究成果清晰地表明,只要我们合理地扩大模型规模、扩充数据集并增加计算投入,语言建模的性能就会以平稳且可预测的方式得到显著提升。我们有理由相信,未来更大规模的语言模型将展现出比当前模型更为卓越的性能,并具备更高的样本利用效率。
2、评价比生成容易
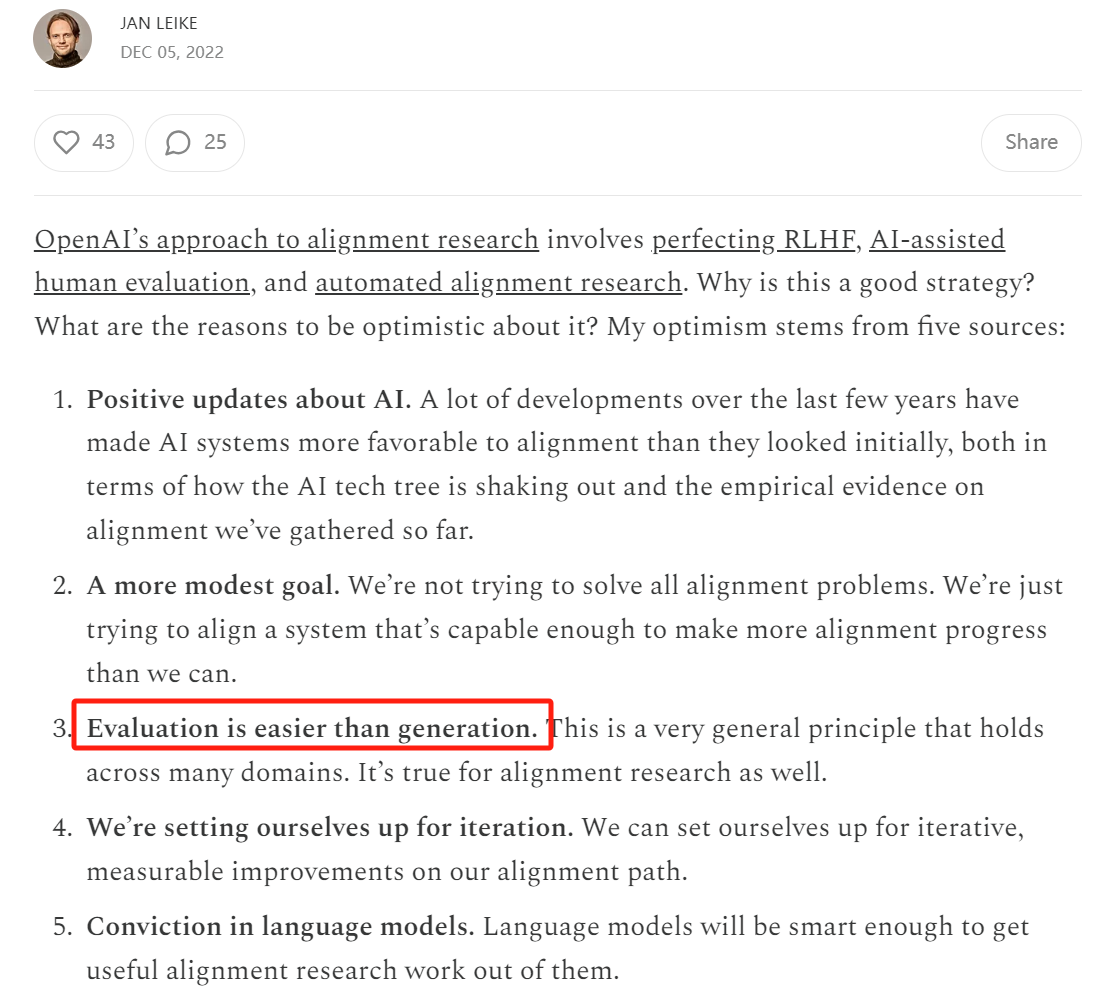
OpenAI 超级对齐团队的主管Jan Leike2022 年发表著名论断:评价比生成更容易
Jan Leike原文:https://aligned.substack.com/p/alignment-optimism ;
评估比生成更容易,这一原则至关重要。它意味着,如果我们把精力集中在评估AI系统的行为上,而不是亲自去完成这些任务(尽管AI的生成能力可能尚不及我们),那么我们的研究进程将大大加速。这一特性构成了递归奖励建模(以及在一定程度上,OpenAI提出的Debate框架)的基石:当评估变得比生成更容易时,AI辅助的人类将在与智能水平相当的AI生成器的竞争中占据优势。基于这一前提,我们可以通过为AI系统执行任务创建评估信号,进而训练AI模型,使其能够应对越来越复杂的任务。尽管递归奖励建模的扩展能力并非无限,但它也无需达到无限扩展。只需确保其能够扩展到足以支持我们监督大量对齐研究的程度即可。
3、相对评价比绝对评价容易

相对评价:弱模型来监督强模型
相对评价比绝对评价更易实施:OpenAI基于“评价比生成更容易”的理念,于2023年底成功发表了超级对齐领域的开创性研究——Weak-to-Strong Generalization。该研究的核心思想是利用弱模型来监督强模型,从而实现强模型性能的显著提升。尽管当前我们尚未实现超人智能,但通过模拟实验,即采用两个相对较弱的模型进行相互监督,实验结果充分证明了这一方法的有效性。这与传统机器学习中强模型监督弱模型的做法形成了鲜明对比,为超级对齐这一AI乃至人类发展的重要课题带来了新的希望。
从哲学角度来看,相对评价相较于绝对评价具有更高的可行性。例如,对于非专业设计师而言,直接评价一个网页设计的好坏可能颇具挑战。然而,当面对两个设计方案时,大多数人都能轻松辨别出哪个更优。同样地,在大模型生成内容的评价中,绝对评分往往受到个人喜好和评分习惯的影响,难以形成统一标准。而相对评分,特别是像Chatbot Arena这样的双盲相对评分机制,则能有效规避这些问题,确保评价的客观性和准确性。
四、前沿摸索
1、原生多模态:Sora

Sora经典示例
OpenAI的ChatGPT与近期的Sora,均基于Transformer架构,在AI界掀起热潮。然而,也有权威声音对这一路线提出质疑,更看好世界模型的发展。那么,在通往AGI的道路上,Transformer与世界模型究竟谁能更胜一筹,引领我们走向终极梦想呢?
2、全模态

GPT4o经典示例:看代码 出结果 做分析
GPT-4的经典示例让我们见证了其强大的实力。只需通过电脑桌面版的ChatGPT进行语音交互,无论是询问代码的功能、函数的作用,还是输出代码后的结果解读,例如温度曲线图中的最热月份或是温度单位等,ChatGPT都能对答如流,准确无误。作为首个原生全模态大模型,GPT-4所展现出的能力着实令人瞩目,这也进一步印证了AGI发展的巨大潜力。
3、世界模型

六根手指:图像生成的阿喀琉斯之踵
在图像生成领域,为何模型经常陷入“六根手指”的怪圈,难以精确生成手部图像?这背后的核心问题,在于自回归框架下的模型缺乏对现实世界的常识性理解。
自回归模型通过利用当前的上下文信息来预测下文,当应用于图像生成时,“图像像素”便成为了模型的上下文。这类模型能巧妙地将训练图像转化为一维序列,借助Transformer转换器进行自回归预测,从而捕捉到像素与高级属性(如纹理、语义、尺寸等)间的微妙联系。然而,这种方法的弊端也显而易见。正由于缺乏对现实世界的常识,模型在预测图像像素时常常会做出违背常理的判断,“六根手指”的怪象便是其中的典型例证。这种偏离现实的“幻觉”现象,已成为自回归模型亟待解决的问题。
面对这一困境,LeCun提出了“世界模型”的构想。他主张,AI应当像婴儿一样学习世界的运作方式,以此提升其常识性理解能力。而实现这一构想的关键,便在于他所提出的JEPA(联合嵌入预测架构)。通过JEPA,我们可以利用一系列编码器来捕捉世界状态的抽象表征,并结合多层次的世界模型预测器,来全方位地预测世界的不同状态及其随时间的变化。这种架构有望引领图像生成模型走出“六根手指”的困境,迈向更为精准、真实的生成新境界。
五、局限与希望
1、当前AI落地三原则
在探讨AGI的当前局限时,我们不难发现,大模型技术正逐渐展现出其惊人的潜能与广泛的应用前景。以下三个原则,不仅揭示了大模型的能力边界,可能也为我们指明了AGI未来的发展方向。
- 原则一.将一切文字任务都交给大模型。将提案扩展为方案计划书,将分析总结为结论,精炼润色一段啰嗦的文本,将200字扩展成1w字,将1000字周报缩写为100字,等等,大模型都非常擅长。
- 原则二.将一切跨语言任务都交给大模型。英译汉、汉译英、语音转文本、甚至将自然语言转换为编程语言,大模型在某些任务上已经很擅长,在某些任务上一定会不断更好。
- 原则三.一切跨图文任务都可以交给大模型。让大模型用一段文字描述一张图片,让大模型将一段文字描述转化为一张图片。大模型完成的质量不一定会很高,但一定有可取之处。
综上所述,三个原则分别对应了归纳与总结(结合RAG工程)、分析与推理(结合Agent工程与Action工具)以及感知与全能(或许是实现AGI的关键路径)。随着技术的不断进步与应用的深入拓展,我们有理由相信,AGI的曙光就在眼前。
2、类人系统

清华刘知远教授“大模型十问”第七问:类人系统构建
人的高级认知能力是否可以让大模型学到?能不能让大模型像人一样完成一些任务?人去完成任务一般会进行几个方面的工作:第一,我们会把这项任务尝试拆分成若干个简单任务,第二,针对这些任务去做一些相关信息的获取,最后我们会进行所谓的高级推理,从而完成更加复杂的任务。
这也是一个非常值得探索的前沿方向,在国际上有WebGPT等方法的尝试已经开始让大模型学会使用搜索引擎等等。我们甚至会问,可不可以让大模型学会像人一样网上冲浪,去有针对性地获取一些相关信息,进而完成任务。
3、希望在前方

Deepmind定义的AGI六阶段
Deepmind Framework的最新论文深入剖析了AGI的进展,并明确提出了六个评估原则,用以衡量AI的能力等级:
● 新兴:此阶段的AI能力相对有限,主要集中在特定的任务范围内。
● 胜任:随着技术的演进,AI的能力逐渐拓宽,能够胜任更为多样化的任务。
● 专家:在这一阶段,AI的能力进一步得到拓展,能够在各项任务中超越大多数人类的表现。
● 天才:AI的能力变得更为广泛且深入,能够在各种任务中展现出优于绝大多数人类的卓越表现。
● 超人:这是AI发展的终极阶段,AI将拥有全面的能力,能够在所有任务上全面超越人类的表现。
透过这六个原则的“镜头”,我们可以清晰地看到,当前我们正处于AGI发展的第1级,即“新兴”阶段。在这一阶段,我们主要关注AI在各个领域中的推理能力、上下文理解能力以及连贯响应生成能力等方面的表现与评估。这些评估不仅有助于我们更全面地了解AI的现状,也为AGI的未来发展指明了方向。
结论
是的,我们既不应将人工智能神化,也不应轻视其潜力。将人脑视为智能演进的终点,无异于将人类置于宇宙中的神圣地位,这显然是出于人类本能的自我中心偏见。
正如风险管理大师纳西姆·塔勒布在《随机漫步的傻瓜》中所言:“傻瓜总认为自己是特别的,而他人都是普通的;智者则认为自己普通,而他人各有特色。”对人工智能的轻视与过度崇拜,同样都是片面且有害的。
这篇关于AGI技术与原理浅析:曙光还是迷失?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




