本文主要是介绍MAIA:多模态自动化可解释智能体的突破,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着人工智能技术的飞速发展,深度学习模型在图像识别、自然语言处理等领域取得了显著成就。然而,这些模型的“黑箱”特性使得其决策过程难以理解,限制了它们的应用范围和可靠性。为了解决这一问题,研究者们提出了多种模型可解释性方法,旨在提高模型的透明度和可信度。
MAIA(Multimodal Automated Interpretability Agent)是一种创新的系统,由一组预训练的神经模型构成,它们协同工作以执行诸如特征解释和故障模式发现等任务。MAIA的核心是一个多模态预训练模型,它不仅能够处理图像,还能够理解和生成自然语言,这使得它能够以更加直观和灵活的方式与人类研究人员互动。
MAIA的框架和工具
MAIA的设计是围绕一个先进的多模态预训练模型构建的,这个模型被称为GPT-4V视觉-语言模型(VLM)。这个模型不仅能够理解和生成自然语言,还能够直接处理和分析图像内容。这种能力使得MAIA能够执行复杂的任务,比如自动化地设计和执行实验来解释深度学习模型的行为。VLM作为MAIA的智能核心,使得代理能够理解复杂的视觉概念,并将这些概念与语言描述关联起来,从而提供更深入的模型解释。
MAIA的架构通过一个精心设计的API实现,这个API提供了两个主要的组件:System类和Tools类。System类的核心功能是与目标系统进行交互,它允许MAIA访问和操作深度学习模型的特定部分,例如单个神经元或整个网络层。通过这种方式,MAIA能够深入探究模型的内部工作原理,识别关键特征,并解释模型的决策过程。
与System类紧密协作的是Tools类,它为MAIA提供了一系列的工具函数,这些函数支持MAIA执行各种实验和分析。Tools类中的工具使得MAIA能够合成和编辑图像,计算最大化激活示例,以及总结和描述实验结果。这些工具不仅增强了MAIA的实验能力,也使得它能够以更加灵活和创新的方式探索和解释深度学习模型的行为。

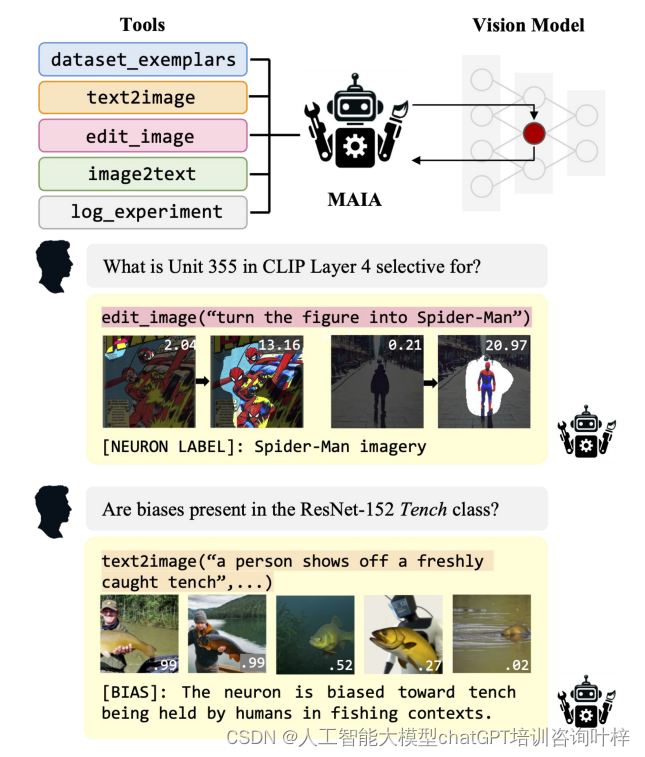
如图2所示,MAIA可以使用text2image函数根据文本提示生成图像,或者使用edit_images函数根据编辑指令修改现有图像。这些工具使得MAIA能够测试模型对特定视觉概念的敏感性,或者检验模型对图像内容变化的反应。
通过System类和Tools类的结合,MAIA展现出了强大的自动化可解释性能力。它能够自动地提出假设,设计实验来测试这些假设,并根据实验结果更新其理解。这种自动化的迭代过程大大加快了模型解释的速度,并减少了对人类研究人员的依赖。MAIA的这种设计不仅提高了可解释性研究的效率,也为理解和改进深度学习模型提供了新的视角和工具。
MAIA的自动化可解释性框架是一个创新的解决方案,它应对了深度学习模型日益增长的复杂性和不透明性。随着AI技术的不断发展,对于能够理解和解释这些强大模型的需求也在增长。MAIA通过提供自动化的解释能力,帮助我们更好地理解和信任AI系统的决策过程,这对于推动AI技术的健康发展和广泛应用至关重要。随着MAIA技术的不断进步和完善,我们期待它在未来能够发挥更大的作用,为AI的可解释性、透明度和可靠性做出更大的贡献。
MAIA的性能评估
MAIA的性能评估是一个多维度的过程,旨在全面检验其在自动化解释深度学习模型方面的能力。评估的首要任务是验证MAIA对单个神经元的描述能力。为了实现这一目标,研究者们设计了一系列实验,其中包括将MAIA生成的描述与人类专家的描述进行比较。这些比较不仅涉及描述的准确性,还包括预测神经元行为的能力。
在这些实验中,MAIA展现出了令人印象深刻的性能。它不仅能够生成与人类专家相匹配的描述,而且在某些情况下,MAIA的描述在预测神经元行为方面甚至超过了人类专家。这一结果表明,MAIA具备了深入理解模型内部工作机制的潜力,并且能够以一种可预测的方式解释模型的行为。
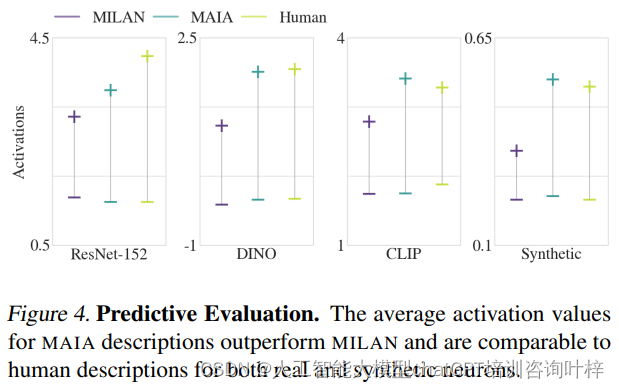
如图4所示,MAIA在预测评估中的表现通过平均激活值进行了量化,这些值显示了MAIA描述的预测性能优于MILAN基线方法,并且与人类描述相当。这一发现证实了MAIA在自动化解释任务中的有效性,尤其是在生成有助于理解模型行为的描述方面。

除了单个神经元的描述任务,MAIA还被赋予了自动化执行更高层次模型解释任务的能力。例如,它能够识别和去除模型中的偶然特征,这些特征可能会导致模型在现实世界的应用中表现不佳。如图8所示,MAIA通过生成不同背景的图像来测试模型对特定背景类型的依赖性,从而识别出与狗品种无关的背景特征,这是去除错误特征的关键步骤。
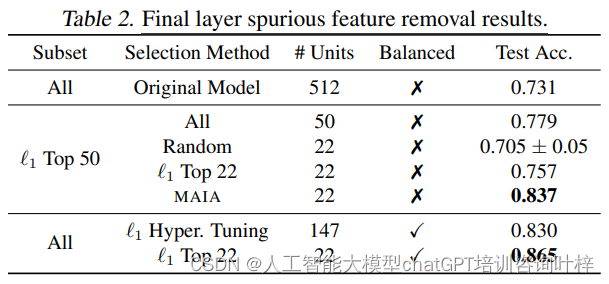
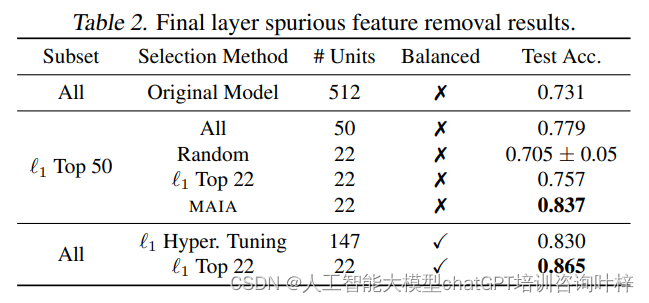
MAIA在去除错误特征任务中的实验结果展示了不同方法在处理最终网络层时,对模型性能的影响。Table 2比较了原始模型和经过不同技术处理后的模型在平衡测试集上的准确率。
Table 2的结果表明,MAIA在去除错误特征的任务上表现出色,其自动化选择的神经元能够显著提高模型在分布变化下的鲁棒性。此外,这些结果也显示了MAIA与当前最先进的技术相比具有竞争力,甚至在某些情况下更为优秀。这些发现强调了MAIA作为一个自动化可解释性代理,在提高深度学习模型的可解释性和鲁棒性方面的潜力。

MAIA还能够自动检测模型的偏差。如图9所示,MAIA可以生成一系列合成图像,这些图像在视觉上与模型的某个输出类别相关联,但可能在某些方面存在偏差。通过分析模型对这些合成图像的响应,MAIA能够揭示模型在处理这些输入时的偏差,并提供可能的改进方向。
为了进一步探究MAIA的性能,研究者们还开展了工具消融研究。这些研究通过有选择性地移除或替换MAIA API中的特定工具,来评估这些工具对MAIA整体性能的影响。通过这些实验,研究者们发现,当MAIA能够结合使用数据集示例和合成图像进行实验时,它的性能表现最佳。这一发现强调了MAIA工具箱中工具多样性的重要性,以及不同工具之间协同作用对于提高MAIA解释能力的作用。
MAIA的性能评估结果不仅验证了其作为自动化可解释性代理的潜力,也为未来的研究和应用提供了宝贵的见解。随着深度学习模型在社会中扮演越来越重要的角色,对这些模型的深入理解和解释变得尤为关键。MAIA通过提供自动化的解释能力,帮助我们更好地理解和信任AI系统的决策过程,这在推动AI技术的健康发展和广泛应用方面具有重要意义。随着技术的不断进步,我们有理由相信,MAIA将在未来的AI研究和应用中发挥更大的作用,为提高AI的可解释性、透明度和可靠性做出更大的贡献。
MAIA的应用示例
在现实世界的应用中,机器学习模型可能会学习到一些与任务无关的偶然特征,这些特征被称为错误特征。例如,在图像分类任务中,模型可能错误地将图像的背景与目标类别关联起来,而不是目标本身的特征。MAIA可以通过自动化的方式识别和去除这些错误特征,从而提高模型的泛化能力和鲁棒性。
通过使用MAIA,研究人员能够在没有访问未偏差样本或分组注释的情况下,识别并移除这些特征,从而提高模型在面对数据分布变化时的鲁棒性。表格中的“Subset Selection Method”列出了选择神经元子集的方法,“# Units”显示了保留的神经元数量,而“Balanced Test Acc.”则表示在平衡测试集上的测试准确率。这些结果表明,MAIA在选择神经元以提高模型鲁棒性方面与当前的一些方法相当,甚至在某些情况下更为有效。
在进行错误特征去除时,MAIA首先会通过生成或编辑图像来测试特定神经元对不同视觉概念的敏感性。如图8所示,MAIA可能会生成一系列不同背景的图像,以测试模型是否对背景特征过度敏感。通过这种方式,MAIA能够识别出那些对模型决策有负面影响的特征,并提出去除这些特征的建议。

MAIA的另一个重要应用是自动识别模型的偏差。在图像分类等任务中,模型可能会因为训练数据的不平衡或偏差而产生不公平的预测。MAIA可以通过分析模型对特定输入的响应来识别这些偏差。
如图9所示,MAIA可以生成一系列合成图像,这些图像在视觉上与模型的某个输出类别相关联,但可能在某些方面存在偏差(例如,某个类别的图像可能主要包含特定性别或种族的人物)。通过分析模型对这些合成图像的响应,MAIA能够揭示模型在处理这些输入时的偏差,并提供可能的改进方向。

MAIA的应用在很大程度上依赖于其处理和生成图像的能力。无论是在去除错误特征还是识别偏差的过程中,MAIA都能够利用图像来提供直观的证据,支持其解释和建议。例如,MAIA可能会生成一个图像集,其中包含不同变体的图像,以展示模型对特定特征的敏感性。这些图像不仅为MAIA的解释提供了依据,也为人类研究人员提供了直观的理解方式。
通过结合图像和自动化实验,MAIA展示了其在深度学习模型可解释性领域的强大潜力。它不仅能够提供深入的模型分析,还能够以一种易于理解的方式向人类研究人员传达这些分析结果。随着AI技术的不断发展,MAIA及其后续系统将在提高AI透明度和可靠性方面发挥越来越重要的作用。
虽然MAIA仍然需要人类监督来避免常见错误,但其在自动化解释任务方面的表现令人鼓舞,预示着随着技术的进步,可解释性代理将变得越来越有用。
论文链接:https://arxiv.org/abs/2404.14394
项目地址:https://multimodal-interpretability.csail.mit.edu/maia/
这篇关于MAIA:多模态自动化可解释智能体的突破的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






