本文主要是介绍logger使用,解决中文乱码问题,重复缓存问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目的
在模型训练过程中,想把控制台内容输出的内容缓存起来,以便后期检查使用,就用起了logger。用的时候遇到过中文乱码问题以及重复缓存问题(即后面的logger对象将前面的logger对象缓存内容也缓存下来了)。
解决方法:
- 设置编码格式(encoding=“utf-8”)
- 写了清楚logger对象的函数。
在 Python 中使用 logging 模块时,如果实例化了多个 loggers 并且日志处理器没有被正确地移除,可能会导致日志数据重复。
代码
'''
Descripttion:
Result:
Author: Philo
Date: 2023-10-10 10:04:28
LastEditors: Philo
LastEditTime: 2024-05-15 20:53:44
'''
import logging
import osdef get_logger(log_name, verbosity=1):level_dict = {0: logging.DEBUG, 1: logging.INFO, 2: logging.WARNING} # 创建了一个字典,用于将传入的 verbosity 参数转换为相应的日志记录级别。formatter = logging.Formatter("[%(asctime)s][%(filename)s] %(message)s" # 创建了一个格式化对象,用于指定日志记录的格式,其中包含了记录时间、文件名和消息内容。)logger = logging.getLogger(log_name) # 获取一个 Logger 对象logger.setLevel(level_dict[verbosity]) # 设置记录器的记录级别,根据传入的 verbosity 参数选择相应的记录级别。fh = logging.FileHandler(log_name, "w", encoding="utf-8") # 创建了一个文件处理器对象,用于将日志记录写入到指定的文件中,以追加的方式写入。fh.setFormatter(formatter) # 为文件处理器对象设置了格式化器,指定了写入到文件中的日志记录格式。logger.addHandler(fh) # 将文件处理器对象添加到记录器中,以便将日志记录写入到文件中。return logger # 返回创建的记录器对象,以便在其他地方使用。def clear_loggers():for handler in logging.root.handlers[:]:logging.root.removeHandler(handler)if __name__ == "__main__":# 设置日志文件路径和记录级别log_filename = "example.log"log_verbosity = 1 # 0: DEBUG, 1: INFO, 2: WARNING# 创建记录器logger = get_logger(log_filename)# 记录不同级别的消息logger.debug("这是一条调试信息")logger.info("这是一条普通信息")logger.warning("这是一条警告信息")logger.error("这是一条错误信息")logger.critical("这是一条严重错误信息")clear_loggers()输出结果:

代码训练过程中使用:
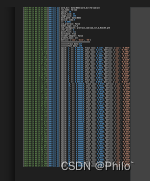
这篇关于logger使用,解决中文乱码问题,重复缓存问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




