本文主要是介绍我给 Scrapy Redis 开源库发的 PR 被合并了,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

这是「进击的Coder」的第 366 篇技术分享
作者:崔庆才
来源:崔庆才丨静觅
“
阅读本文大概需要 6 分钟。
”不知道大家基于 Scrapy-Redis 开发分布式爬虫的时候有没有遇到一个比较尴尬的问题,且听我一一道来。
大家在运行 Scrapy 的的时候肯定见过类似这样输出吧:
2021-03-15 21:52:06 [scrapy.extensions.logstats] INFO: Crawled 33 pages (at 33 pages/min), scraped 172 items (at 172 items/min)
...
这里就是一些统计输出结果对不对,它告诉我们当前这个爬虫的爬取速度和总的爬取情况。
另外在爬取完成之后最后输出的的统计信息是这样的:
{'downloader/request_bytes': 2925,'downloader/request_count': 11,'downloader/request_method_count/GET': 11,'downloader/response_bytes': 23406,'downloader/response_count': 11,'downloader/response_status_count/200': 10,'downloader/response_status_count/404': 1,'elapsed_time_seconds': 3.917599,'finish_reason': 'finished','finish_time': datetime.datetime(2021, 3, 15, 14, 1, 36, 275427),'item_scraped_count': 100,'log_count/DEBUG': 111,'log_count/INFO': 10,'memusage/max': 55242752,'memusage/startup': 55242752,'request_depth_max': 9,'response_received_count': 11,'robotstxt/request_count': 1,'robotstxt/response_count': 1,'robotstxt/response_status_count/404': 1,'scheduler/dequeued': 10,'scheduler/dequeued/memory': 10,'scheduler/enqueued': 10,'scheduler/enqueued/memory': 10,'start_time': datetime.datetime(2021, 3, 15, 14, 1, 32, 357828)}
2021-03-15 22:01:36 [scrapy.core.engine] INFO: Spider closed (finished)
然而这个信息,当我们使用基于 Scrapy-Redis 来实现的时候,你会发现每个爬虫都在做自己的统计,比如其中一个 Spider 机器性能和网络比较好,爬取速度快,那么它的统计结果就更高,表现不太好的 Spider 它的统计结果就差一些。这些 Spider 的统计信息都是独立的互不影响的,数据也各不相同。
这是个麻烦事啊,统计信息不同步而且很分散,我想知道总共爬取了多少条数据也不知道,那怎么办呢?另外我还想对这些统计数据做数据分析和报表,根本不知道咋合并统计。
所以,我在想,如果这个统计信息也能基于 Redis 实现多爬虫同步不就好了吗?
实现
统计信息首先应该怎么写呢,先查下官方文档,找到这个:https://docs.scrapy.org/en/latest/topics/stats.html
这里介绍了一个 Stats Collection,官方介绍如下:
“Scrapy provides a convenient facility for collecting stats in the form of key/values, where values are often counters. The facility is called the Stats Collector, and can be accessed through the
statsattribute of the Crawler API, as illustrated by the examples in the Common Stats Collector uses p below.However, the Stats Collector is always available, so you can always import it in your module and use its API (to increment or set new stat keys), regardless of whether the stats collection is enabled or not. If it’s disabled, the API will still work but it won’t collect anything. This is aimed at simplifying the stats collector usage: you should spend no more than one line of code for collecting stats in your spider, Scrapy extension, or whatever code you’re using the Stats Collector from.
Another feature of the Stats Collector is that it’s very efficient (when enabled) and extremely efficient (almost unnoticeable) when disabled.
The Stats Collector keeps a stats table per open spider which is automatically opened when the spider is opened, and closed when the spider is closed.
”
OK,没问题,这个就是一个信息收集器,然后我们可以根据它的一些接口来实现自己的信息收集器。
比如设置统计值:
stats.set_value('hostname', socket.gethostname())
比如增加统计值:
stats.inc_value('custom_count')
另外扒了一下源码,看到了默认的收集器就是 MemoryStatsCollector,就是基于内存的,源码见:https://docs.scrapy.org/en/latest/_modules/scrapy/statscollectors.html#MemoryStatsCollector。因为是基于内存的,所以每个爬虫一定是独立的,所以我只需要把它们的共享队列改成 Redis 就能实现分布式信息收集的同步了。
另外看来这些统计信息,基本上就是表示为 key-value 信息,存到 Redis 最合适的当然是 Hash 了。
OK,说干就干,改写了下 Memory,把存储换成 Redis,其他的实现基本差不多,实现了一个 RedisStatsCollector 如下:
from scrapy.statscollectors import StatsCollector
from .connection import from_settings as redis_from_settings
from .defaults import STATS_KEY, SCHEDULER_PERSISTclass RedisStatsCollector(StatsCollector):"""Stats Collector based on Redis"""def __init__(self, crawler, spider=None):super().__init__(crawler)self.server = redis_from_settings(crawler.settings)self.spider = spiderself.spider_name = spider.name if spider else crawler.spidercls.nameself.stats_key = crawler.settings.get('STATS_KEY', STATS_KEY)self.persist = crawler.settings.get('SCHEDULER_PERSIST', SCHEDULER_PERSIST)def _get_key(self, spider=None):"""Return the hash name of stats"""if spider:self.stats_key % {'spider': spider.name}if self.spider:return self.stats_key % {'spider': self.spider.name}return self.stats_key % {'spider': self.spider_name or 'scrapy'}@classmethoddef from_crawler(cls, crawler):return cls(crawler)def get_value(self, key, default=None, spider=None):"""Return the value of hash stats"""if self.server.hexists(self._get_key(spider), key):return int(self.server.hget(self._get_key(spider), key))else:return defaultdef get_stats(self, spider=None):"""Return the all of the values of hash stats"""return self.server.hgetall(self._get_key(spider))def set_value(self, key, value, spider=None):"""Set the value according to hash key of stats"""self.server.hset(self._get_key(spider), key, value)def set_stats(self, stats, spider=None):"""Set all the hash stats"""self.server.hmset(self._get_key(spider), stats)def inc_value(self, key, count=1, start=0, spider=None):"""Set increment of value according to key"""if not self.server.hexists(self._get_key(spider), key):self.set_value(key, start)self.server.hincrby(self._get_key(spider), key, count)def max_value(self, key, value, spider=None):"""Set max value between current and new value"""self.set_value(key, max(self.get_value(key, value), value))def min_value(self, key, value, spider=None):"""Set min value between current and new value"""self.set_value(key, min(self.get_value(key, value), value))def clear_stats(self, spider=None):"""Clarn all the hash stats"""self.server.delete(self._get_key(spider))def open_spider(self, spider):"""Set spider to self"""if spider:self.spider = spiderdef close_spider(self, spider, reason):"""Clear spider and clear stats"""self.spider = Noneif not self.persist:self.clear_stats(spider)
OK,我把这个代码放到 Scrapy-Redis 的源码里面,新建了一个 stats.py 的文件夹,然后本地重新安装下 Scrapy-Redis 这个包:
切换到 Scrapy-Redis 源码目录,执行安装命令如下:
pip3 install .
输出结果类似如下:
...
Installing collected packages: scrapy-redisAttempting uninstall: scrapy-redisFound existing installation: scrapy-redis 0.7.0.dev0Uninstalling scrapy-redis-0.7.0.dev0:Successfully uninstalled scrapy-redis-0.7.0.dev0
Successfully installed scrapy-redis-0.7.0.dev0
这样本地就装好最新版的 Scrapy-Redis 了。
然后本地测试下,切到 example-project/example 目录下,添加了一行代码:
STATS_CLASS = "scrapy_redis.stats.RedisStatsCollector"
意思就是信息收集器这个类使用我刚才创建的 RedisStatsCollector,然后运行:
scrapy crawl dmoz
运行起来了,然后我再开另外的命令行运行同样的命令,启动多个爬虫。
这时候我打开 Redis Desktop Manager,就看到了如下的四个键名:

看到了吧,这里多了一个 dmoz:stats,这个就是统计信息,打开之后内容如下:
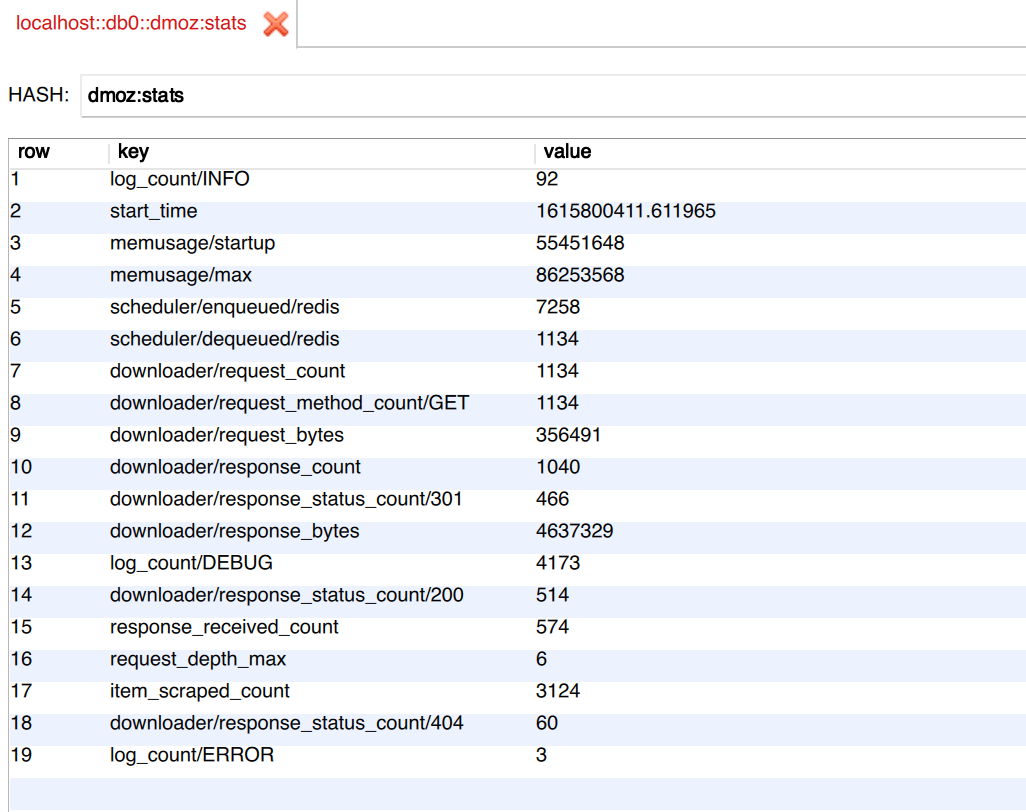
可以看到所有的统计数据就被存到 Redis 了,而且每个 Spider 都会读取和写入,实现了多个 Spider 统计信息的同步。
发 PR
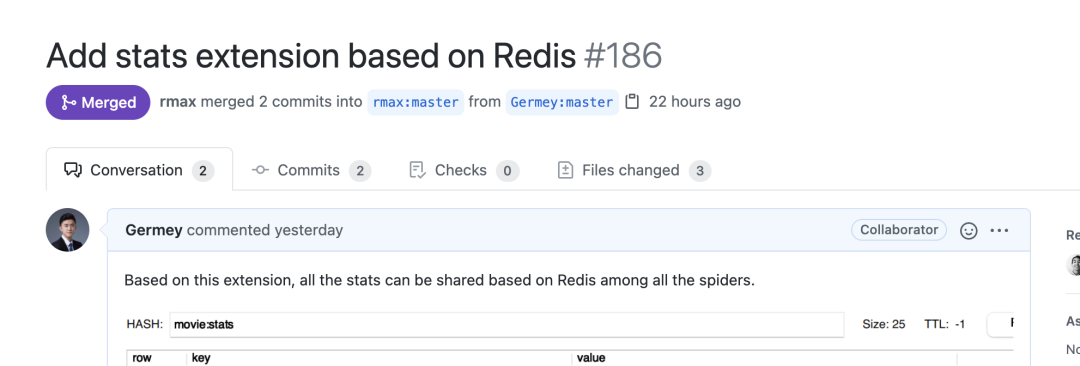
这个 Feature 我后来就给 Scrapy-Redis 的作者发了 PR,https://github.com/rmax/scrapy-redis/pull/186,幸运的是,今天发现已经被 Approve 并 merge 了:
作者 rmax 还说了声 Nice Feature:
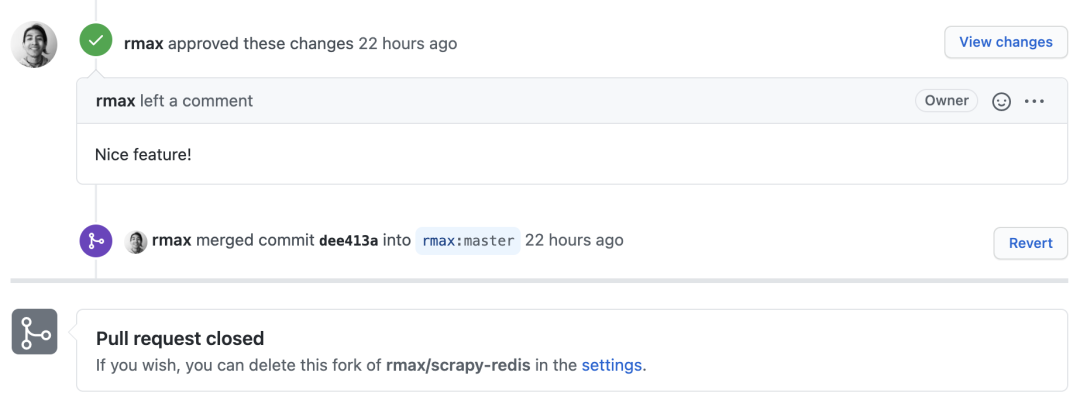
激动!开心!
另外我还和作者联系了下,了解到他现在正在寻找 Scrapy-Redis 这个项目的 maintainer,然后我就跟他说我乐意帮忙维护这个项目,他给我加了一些权限。
后续 Scrapy-Redis 的维护我应该也会参与进来了。比如刚刚我发的 Feature,后续会发新版本的 Scrapy-Redis 的 Release。
这里不得不说一句,Scrapy-Redis 距离上次发新版本已经三年多了,新的改动都在 master,一直没有 release,我给作者提了 Issue 反馈了这个问题不过也一直没有发新版,后续应该我会帮忙发布一个新的 Release,把最新的 Feature 和 Bug Fix 都上了。
如果大家想体验刚才介绍的最新的 Feature 的话,可以直接安装 master 版本,命令如下:
pip3 install git+https://github.com/rmax/scrapy-redis.git
如有问题希望大家及时反馈和提 Issue,感谢支持!
作者:崔庆才
排版:崔庆才
崔庆才丨静觅
隐形字
同名公众号「崔庆才丨静觅」
在这里分享自己的一些经验、想法和见解。



长按识别二维码关注
好文和朋友一起看~
这篇关于我给 Scrapy Redis 开源库发的 PR 被合并了的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





