本文主要是介绍爬虫+可视化「奔跑吧」全系列嘉宾名单,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这是「进击的Coder」的第 405 篇技术分享
作者:李运辰
来源:Python研究者
今天给大家带来『奔跑吧』全系列的嘉宾名单爬取和可视化的实现,分析每位嘉宾参加次数(可能有的嘉宾参加过几季),以及统计嘉宾职业类型个数,最后进行可视化展示分析。
1
网页分析
通过网上查询,知道『奔跑吧』到目前为止一共9季,先是奔跑吧兄弟1~4,到后面改名为奔跑吧1~4,以及奔跑吧黄河篇。
对应的网页链接如下:
url_list=['https://baike.baidu.com/item/奔跑吧兄弟第一季#4_2','https://baike.baidu.com/item/奔跑吧兄弟第二季/16414779','https://baike.baidu.com/item/奔跑吧兄弟第三季','https://baike.baidu.com/item/奔跑吧兄弟第四季','https://baike.baidu.com/item/奔跑吧第一季/20433390?fromtitle=奔跑吧第1季&fromid=22645259&fr=aladdin#4_2','https://baike.baidu.com/item/奔跑吧第二季/22421345?fromtitle=奔跑吧第2季&fromid=22645247&fr=aladdin#4_2','https://baike.baidu.com/item/奔跑吧第三季/23284990?fromtitle=奔跑吧第3季&fromid=23285732&fr=aladdin','https://baike.baidu.com/item/奔跑吧第四季/24701671?fromtitle=奔跑吧第4季&fromid=50003758&fr=aladdin','https://baike.baidu.com/item/奔跑吧·黄河篇/53052048'
]
1.分析网页结构
首先以奔跑吧第1季为例去分析网页结构(其他的链接网页结构一样)

咱们主要是爬取嘉宾姓名和明星类型(演员、歌手等)
本来想通过xpath解析网页方式去定位数据,但是发现定位不到,所以就采取了另外一种方式:字符串截取(其实正则re也可以,有很多种方式,只要能够解析出来即可,大家可以自由发挥)


截取前后分别是:分期嘉宾、表演嘉宾
2
获取数据
首先导入相应的库
import requests
from lxml import etree
import json
import time
import openpyxl
将9季的网页链接放到集合中url_list,同时定义name存放嘉宾名字,types是明星类型(歌手、演员等)
### 姓名
name = []
### 明星类型
types = []
url_list=['https://baike.baidu.com/item/奔跑吧兄弟第一季#4_2','https://baike.baidu.com/item/奔跑吧兄弟第二季/16414779','https://baike.baidu.com/item/奔跑吧兄弟第三季','https://baike.baidu.com/item/奔跑吧兄弟第四季','https://baike.baidu.com/item/奔跑吧第一季/20433390?fromtitle=奔跑吧第1季&fromid=22645259&fr=aladdin#4_2','https://baike.baidu.com/item/奔跑吧第二季/22421345?fromtitle=奔跑吧第2季&fromid=22645247&fr=aladdin#4_2','https://baike.baidu.com/item/奔跑吧第三季/23284990?fromtitle=奔跑吧第3季&fromid=23285732&fr=aladdin','https://baike.baidu.com/item/奔跑吧第四季/24701671?fromtitle=奔跑吧第4季&fromid=50003758&fr=aladdin','https://baike.baidu.com/item/奔跑吧·黄河篇/53052048'
]
开始请求数据
### 循环遍历
for u in url_list:url = uprint(url)res = requests.get(url,headers=headers)res.encoding = 'utf-8'text = res.textsp1 = text.split("参与期数")[1].split("表演嘉宾")[0]selector = etree.HTML(sp1)tr_list = selector.xpath('.//tr')tr_list = tr_list[1:]###名字for i in tr_list:#print(i.xpath(".//div[@class='para']/b/a/text()")[0])name.append(i.xpath(".//div[@class='para']/b/a/text()")[0])### 明星类型for i in tr_list:te = i.xpath(".//div[@class='para']/text()")[0]te = te.split(",")[0].replace("(","")#print(te)types.append(te)print(name)
print(types)
print(len(name))
print(len(types))
保存数据(excel)
outwb = openpyxl.Workbook()
outws = outwb.create_sheet(index=0)
outws.cell(row=1, column=1, value="名字")
outws.cell(row=1, column=2, value="明星类型")
for i in range(0,len(name)):outws.cell(row=i+2, column=1, value=str(name[i]))outws.cell(row=i+2, column=2, value=str(types[i]))
outwb_p.save("奔跑吧嘉宾名单-李运辰.xls") # 保存

3
可视化分析
1.统计每一位嘉宾参加次数排名(取前15)
首先读取excel中数据,其中名字(第一列)存放在name变量中,明星类型(第二列)存放在types变量中。
data = pd.read_excel("奔跑吧嘉宾名单-李运辰.xls")
name = data['名字'].tolist()
types = data['明星类型'].tolist()

然后对name,嘉宾名字进行个数(参加过多少次)统计排名(取前15)
# 排序方法
from collections import Counter
# 排序
d = sorted(result.items(), key=lambda x: x[1], reverse=True)
name_key = [d[i][0] for i in range(0,16)]
value = [d[i][1] for i in range(0,16)]
print(name_key)
print(value)

进行可视化展示
导入相关的库
### 画图
from pyecharts import options as opts
from pyecharts.globals import ThemeType
from pyecharts.charts import Bar
from pyecharts.charts import Pie
绘图代码
# 链式调用c = (Bar(init_opts=opts.InitOpts( # 初始配置项theme=ThemeType.MACARONS,animation_opts=opts.AnimationOpts(animation_delay=1000, animation_easing="cubicOut" # 初始动画延迟和缓动效果))).add_xaxis(xaxis_data=name_key) # x轴.add_yaxis(series_name="统计每一位嘉宾参加次数排名(取前15)", y_axis=values) # y轴.set_global_opts(title_opts=opts.TitleOpts(title='', subtitle='', # 标题配置和调整位置title_textstyle_opts=opts.TextStyleOpts(font_family='SimHei', font_size=25, font_weight='bold', color='red',), pos_left="90%", pos_top="10",),xaxis_opts=opts.AxisOpts(name='嘉宾', axislabel_opts=opts.LabelOpts(rotate=45)),# 设置x名称和Label rotate解决标签名字过长使用yaxis_opts=opts.AxisOpts(name='次数'),).render("统计每一位嘉宾参加次数排名(取前15).html"))
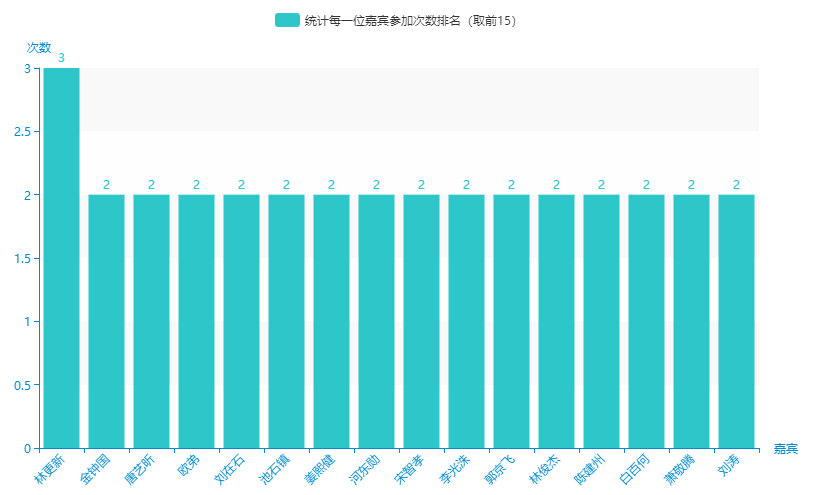
从图中可以看到,参加奔跑吧节目最多的嘉宾是:林更新(3次),其他的最多的次数是两次。
2.嘉宾职业类型统计

从嘉宾(明星)类型中可以大概知道有这么几类(演员、歌手、主持人、模特、主持人、运动员、舞者、制片人、赛车手、经纪人)
开始统计以上这几种职业类型的个数
### 嘉宾职业类型name = ['演员','歌手','主持人','模特','主持人','运动员','舞者','制片人','赛车手','经纪人']### 初始化为0value = [0,0,0,0,0,0,0,0,0,0]for i in types:for j in range(0,len(name)):if name[j] in i:value[j] = value[j] +1print(name)print(value)

开始绘图
pie = Pie("嘉宾职业类型统计",title_pos='center')
pie.add("",name,value,radius=[40, 75],label_text_color=None,is_label_show=True,is_more_utils=True,legend_orient="vertical",legend_pos="left",
)
pie.render(path="嘉宾职业类型统计.html")
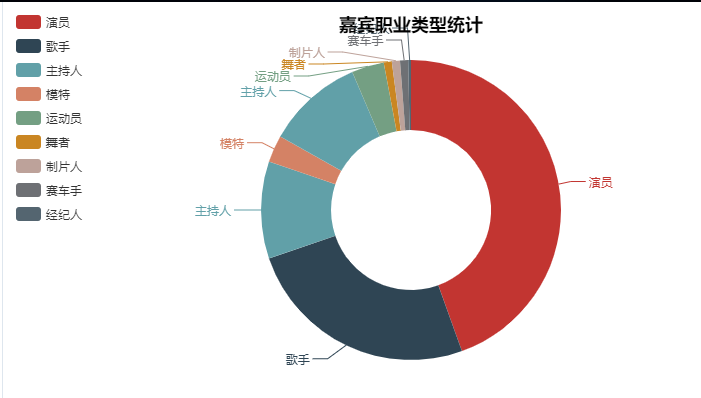
从统计图来看,嘉宾中职业最多的是演员,其次是歌手。
4
小结
今天分析『奔跑吧』全系列的嘉宾名单,分析每位嘉宾参加次数(可能有的嘉宾参加过几季),以及统计嘉宾职业类型个数,最后进行可视化展示分析。

End
「进击的Coder」专属学习群已正式成立,搜索「CQCcqc4」添加崔庆才的个人微信或者扫描下方二维码拉您入群交流学习。

看完记得关注@进击的Coder
及时收看更多好文
↓↓↓
点个在看你最好看
这篇关于爬虫+可视化「奔跑吧」全系列嘉宾名单的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







