本文主要是介绍达梦(DM) SQL数据及字符串操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
达梦DM SQL数据及字符串操作
- 数据操作
- 字符串操作
这里继续讲解DM数据库的操作,主要涉及插入、更新、删除操作。
数据操作
插入数据,不指定具体列的话就需要插入除自增列外的其他列,当然自增列也可以直接指定插入
INSERT INTO SYS_USER VALUES(110,'test002','test002','00',null,'13522266688',0,null,'dfhgjhsfjg','12323',0,0,null,null,'test002','2023-10-23 10:11:11',null,null,null);
执行成功后查看数据

插入多行,比如创建测试表
CREATE TABLE testASSELECT user_id,user_name,login_name,phonenumber,dept_idFROM sys_userWHERE 1 = 2;
创建成功后查询可以看到表创建成功,带WHERE 1 = 2条件的话,实测是只创建指定字段表结构,不带WHERE条件的话会携带对应字段的数据
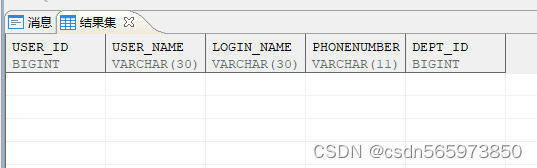
CREATE TABLE test1ASSELECT user_id,user_name,login_name,phonenumber,dept_idFROM sys_user;
执行结果
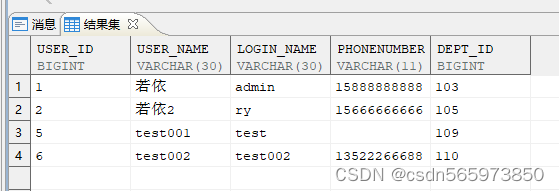
批量插入test表数据
insert into test VALUES (1,'test','test','13511122211',1),(2,'test1','test1','13511122222',1),(3,'test2','test2','13511122233',1);
执行成功后
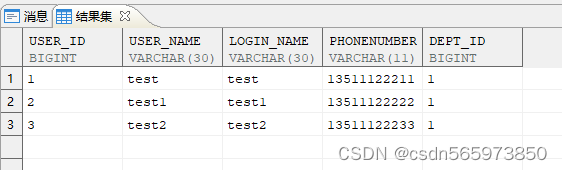
可以按指定列插入行,未指定值的列上若定义了默认值,则插入默认值。没有指定默认值,为 NULL,则插入 NULL 值
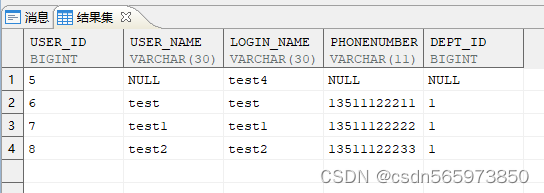
insert into test (user_id,login_name) VALUES (4,'test3'),(5,'test4');
执行结果如图
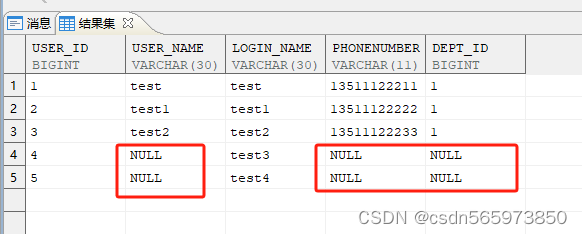
如需快速复制表结构且不需要数据,如需表机构和数据的话 WHERE 1 = 1; 或者不要WHERE条件
CREATE TABLE test2 AS SELECT * FROM test WHERE 1 = 0;
查询表数据库看到
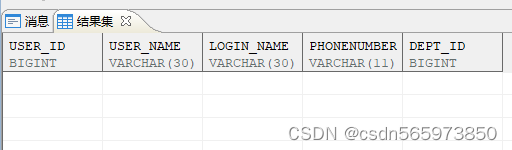
使用 SP_TABLEDEF 过程查看 test2 的结构,所有定义在 test 列上的约束均没有被新表继承。
为表语句添加约束条件
ALTER TABLE test ADD PRIMARY KEY (user_id);
ALTER TABLE test ALTER COLUMN user_name SET DEFAULT 'dm2020';
ALTER TABLE test ALTER COLUMN login_name SET NOT NULL;
ALTER TABLE test ALTER COLUMN phonenumber SET DEFAULT '13511122255';
使用 MERGE INTO 语法可合并 UPDATE 和 INSERT 语句,使用 MERGE 可以实现记录“存在则 update,不存在则 insert”的逻辑。
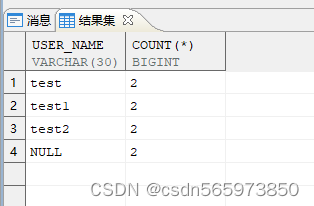
通过 group by + having 子句分组查询的方式,查找员工名称相同的记录
select user_name,count(*) FROM TEST group by USER_NAME HAVING count(*)>1;
查询结果如图
查询重复数据,通过 group by + rowid 的方式,查找员工名称重复的记录
select * from test where ROWID not in (select max(ROWID) from test group by user_name);
查找到重复记录后直接删除
delete from test where ROWID not in (select max(ROWID) from test group by user_name);
执行完再查询发现重复的1 2 3 4 已经删除了
字符串操作
使用函数 regexp_count、regexp_replace 或 translate 统计字符串个数
创建视图
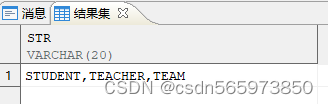
CREATE OR REPLACE VIEW v AS SELECT 'STUDENT,TEACHER,TEAM' AS str FROM DUAL;
select * from V;
看到创建成功的视图
使用函数 regexp_count 统计子串个数
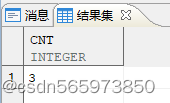
SELECT regexp_count(str,',')+1 as cnt FROM v;
执行结果如图
使用 regexp_replace 迂回求值统计子串个数
SELECT length(regexp_replace(str,'[^,]'))+1 as cnt FROM v;
使用 translate 统计子串个数
SELECT length(translate(str,',' || str,','))+1 AS cnt FROM v;
使用 translate 或者 regexp_replace 在某个字段中去掉不需要的字符,先创建视图
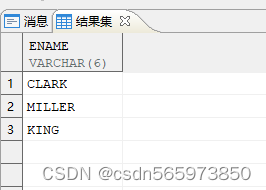
CREATE OR REPLACE VIEW vASSELECT 'CLARK' ename FROM DUALUNION ALLSELECT 'MILLER' FROM DUALUNION ALLSELECT 'KING' FROM DUAL;
创建成功如图
去掉ename中的元音字母
SELECT ename,translate(ename,'1AEIOU','1') stripped1 FROM v;
可以看到元音字母已经去掉了
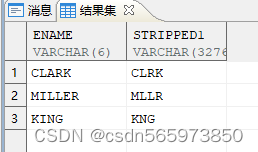
使用正则函数 regexp_replace [] 内列举的字符替换为空
SELECT ename,regexp_replace(ename,'[AEIOU]') AS stripped FROM v;
使用 regexp_replace 正则表达式实现字符串中字符与数字分离,创建测试视图
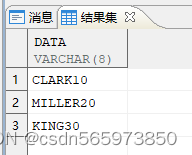
CREATE OR REPLACE VIEW vASSELECT 'CLARK10' data FROM DUALUNION ALLSELECT 'MILLER20' FROM DUALUNION ALLSELECT 'KING30' FROM DUAL;
查询结果如图
使用 regexp_replace 正则表达式
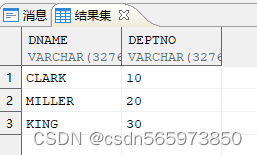
SELECT REGEXP_REPLACE (data, '[0-9]', '') dname,REGEXP_REPLACE (data, '[^0-9]', '') deptnoFROM v;
执行结果如图
使用 regexp_like 实现查询只包含字母或者数字型的数据,创建测试视图
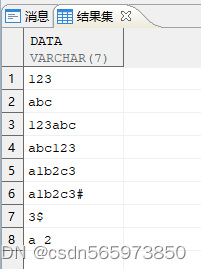
CREATE OR REPLACE VIEW vASSELECT '123' AS data FROM DUALUNION ALLSELECT 'abc' FROM DUALUNION ALLSELECT '123abc' FROM DUALUNION ALLSELECT 'abc123' FROM DUALUNION ALLSELECT 'a1b2c3' FROM DUALUNION ALLSELECT 'a1b2c3#' FROM DUALUNION ALLSELECT '3$' FROM DUALUNION ALLSELECT 'a 2' FROM DUAL;
查询执行结果如图
在上面的语句中,有些数据包含了空格、逗号、$ 等字符。现在要求只返回其中只有字母及数字的行,使用 regexp_like 语句
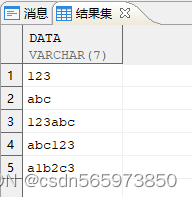
SELECT data FROM v WHERE REGEXP_LIKE (data, '^[0-9a-zA-Z]+$');
查询结果如图
注意下方内容
通过正则表达式或者 translate 函数实现按字符串中的数值排序,创建视图
CREATE OR REPLACE VIEW vASSELECT 'ACCOUNTING 10 NEW YORK' data FROM DUALUNION ALLSELECT 'OPEARTINGS 40 BOSTON' FROM DUALUNION ALLSELECT 'RESEARCH 20 DALLAS' FROM DUALUNION ALLSELECT 'SALES 30 CHICAGO' FROM DUAL;
执行后查询结果如图
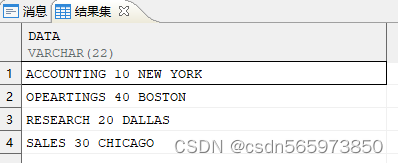
用正则表达式替换非数字字符
SELECT data, TO_NUMBER (REGEXP_REPLACE (data, '[^0-9]', '')) AS deptno FROM V ORDER BY 2;
执行结果如图
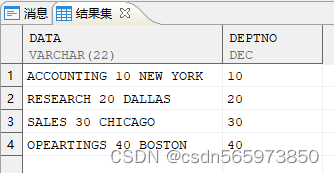
使用 translate 函数,直接替换掉非数字字符
SELECT data,TO_NUMBER (TRANSLATE (data, '0123456789' || data, '0123456789'))AS deptno FROM V ORDER BY 2;
通过 listagg 分析函数实现多行字段的合并显示,创建视图
CREATE OR REPLACE VIEW vASSELECT '10' deptno, 'CLARK' name, '800' sal FROM DUALUNION ALLSELECT '10', 'KING', '900' FROM DUALUNION ALLSELECT '20', 'JAMES', '1000' FROM DUALUNION ALLSELECT '20', 'KATE', '2000' FROM DUALUNION ALLSELECT '30', 'JONES', '1150' FROM DUAL;
执行结果如图
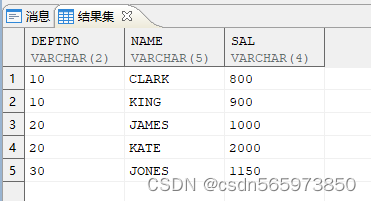
使用 listagg 分析函数实现合并显示
SELECT deptno,SUM (sal) AS total_sal,LISTAGG (name, ',') WITHIN GROUP (ORDER BY name) AS total_name FROM v GROUP BY deptno;
执行结果如图
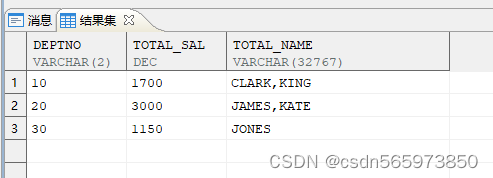
同 sum 一样,listagg 函数也起到汇总结果作用。sum 将数值结果累计求和,而 listagg 是把字符串的结果连在一起。
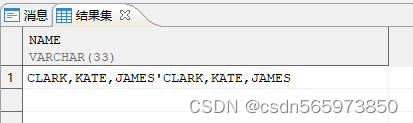
通过 regexp_substr 实现第 n 个子串的分割,创建测试视图
CREATE OR REPLACE VIEW v AS SELECT 'CLARK,KATE,JAMES''CLARK,KATE,JAMES' AS name;
执行结果如图
使用 regexp_substr 分割子串
SELECT REGEXP_SUBSTR (v.name,'[^,]+',1,2) AS 子串 FROM v;
执行结果如图
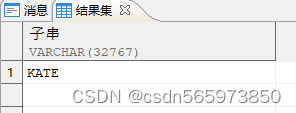
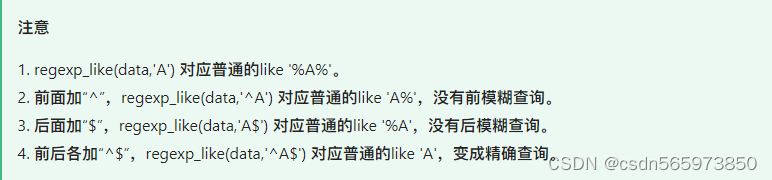
说明:
参数 1:“^”在方括号里表示否的意思,+ 表示匹配 1 次以上。第二个参数表示匹配不包含逗号的多个字符。
参数 2:“1”表示从第一个字符开始。
参数 3:“2”表示第二个能匹配目标的字符串,也就是 KATE。
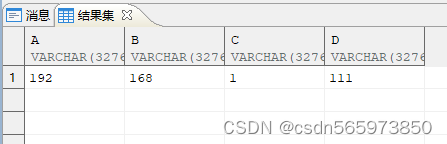
使用 regexp_substr 实现字符串拆分。比如将 IP 地址“192.168.1.111”中的各段取出来
SELECT REGEXP_SUBSTR (v.ip,'[^.]+',1,1)a,REGEXP_SUBSTR (v.ip,'[^.]+',1,2)b,REGEXP_SUBSTR (v.ip,'[^.]+',1,3)c,REGEXP_SUBSTR (v.ip,'[^.]+',1,4)dFROM (SELECT '192.168.1.111' AS ip FROM DUAL) v;
执行结果如图
到这里数据新增,修改,删除的操作以及字符串的相关操作就介绍完了。
这篇关于达梦(DM) SQL数据及字符串操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





