本文主要是介绍分布式文件系统.get(V2)No.106,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2018年9月28号,我估计会记得很久这一天,因为那天刚刚好是我来西厂的一周年,那天刚刚好是农历生日,刚刚好那天晚上我挖了一个大坑,跟遣怀师兄和小美姐姐一起填坑到深夜,真是难忘的一天。。。。。
过去的这一年,估计是毕业这几年来比较艰难的一年,毕竟到了新环境,新地方,附近全都是优秀的人,第一次接触互联网产品,第一次接触零售这个行业。但幸运的是我慢慢上手了,以至于很多人其实都不相信其实我仅仅来了一年。来到这里其实我第一个能说上的,就是Owner感,也不知道是为啥,从毕业开始无论做哪个项目,我都没把它们看成是工作,我都把它们看成自己的崽,都是看着它一步一个跟头成长起来的。
看着它不进步了,会想着去找人想办法帮它成长一把。
看着它踩坑了,会想着拉它一把。
看着它走路不稳,会想着怎么帮它健壮一下自己。
看着它闯祸了,会想着怎么帮它擦一下屁股。
这估计就是最大的收获吧,它的成长就是我的成长。
进入正题吧,今天给你们带来了新一版的分布式文件系统,当然这依然是一个KV形式的纯内存分布式文件系统。能做到什么能力呢?很方便的水平扩容(水平收缩现在还没做),比较基础的负载均衡,比较基础的文件检查,职责分离,能用 ls/put/delete/get 这些基础文件操作。
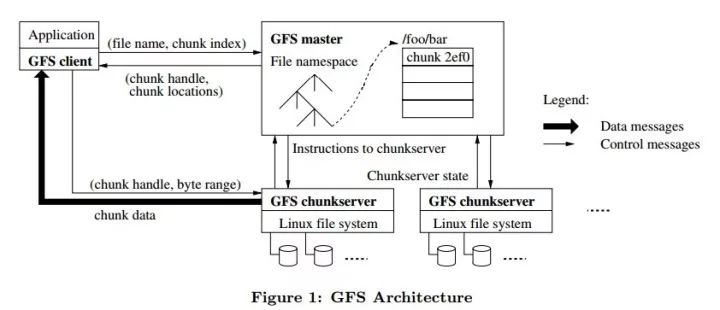
实现的基础论文还是 Google File System,代码都在github上,可以自己下载下来。
https://github.com/CallMeDJ/BigBananaFileSystem.git
现在聊聊怎么启动这套架构。
启动Master
Master 作为整个集群的核心管理单元,需要在第一步骤就起来,Master 承担了文件元数据的管理,ChunkServer的负载均衡,ChunkServer 垃圾回收,ChunkServer 文件检查 等核心能力,是一个一旦不提供服务,整个集群就宕机的存在,当然一般为了稳定会做主备容灾,我在这里没做。
直接跑一下 bfs.server.MasterServer ,启动后MasterServer将会启动一个路径为 rmi://127.0.0.1:8888/master 的 rmi 服务,用来提供给集群中的其他及进行通信。
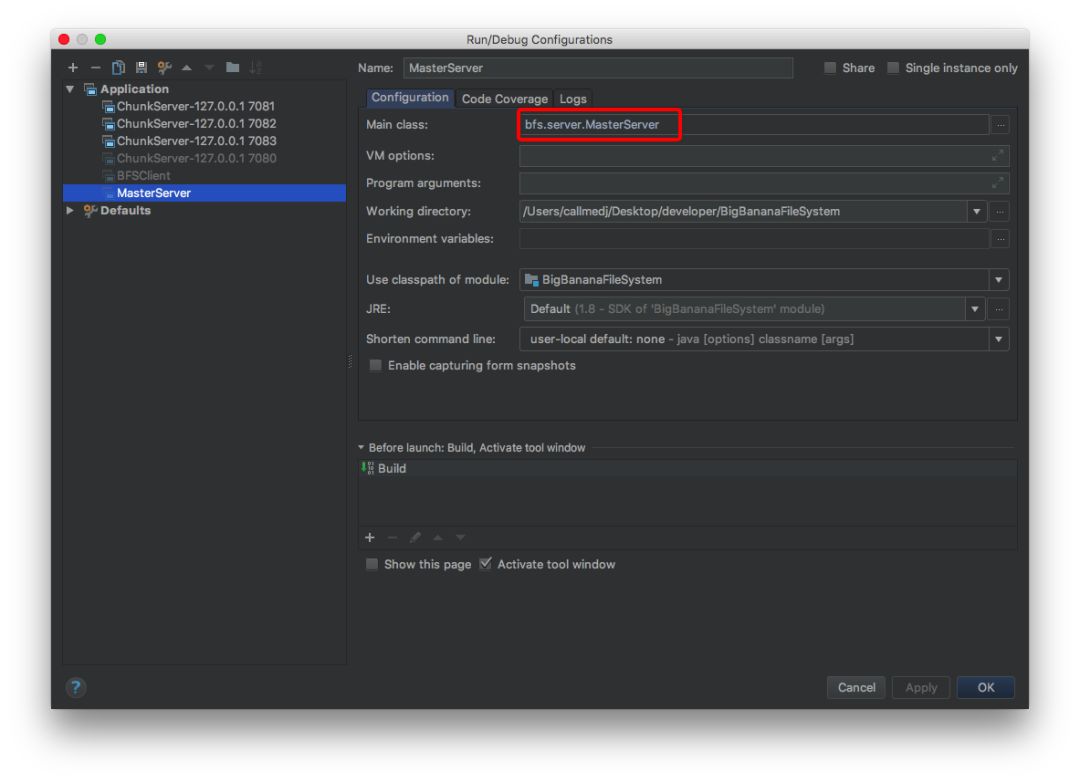
跑完之后我们会看见。

嗯,看见这个我们就认为稳了,Master 已经起来了,成功了一半。
启动ChunkServer
GFS中,将每一个文件片段叫为一个 Chunk (GFS会将大文件切分为大小一致的块名为 Chunk),所以我们将存储管理这些 Chunk 的服务器叫 ChunkServer。
我们的启动类路径是 bfs.server.ChunkServer ,这个类启动有三个入参,分别是 (ip,端口,最大容量),这三个入参可以让我们非常方便地启动任意数量的 ChunkServer 进行水平扩容,当然我们项目里建议的最小服务数量是3个,不然所有的文件都会堆积在一个服务里面。
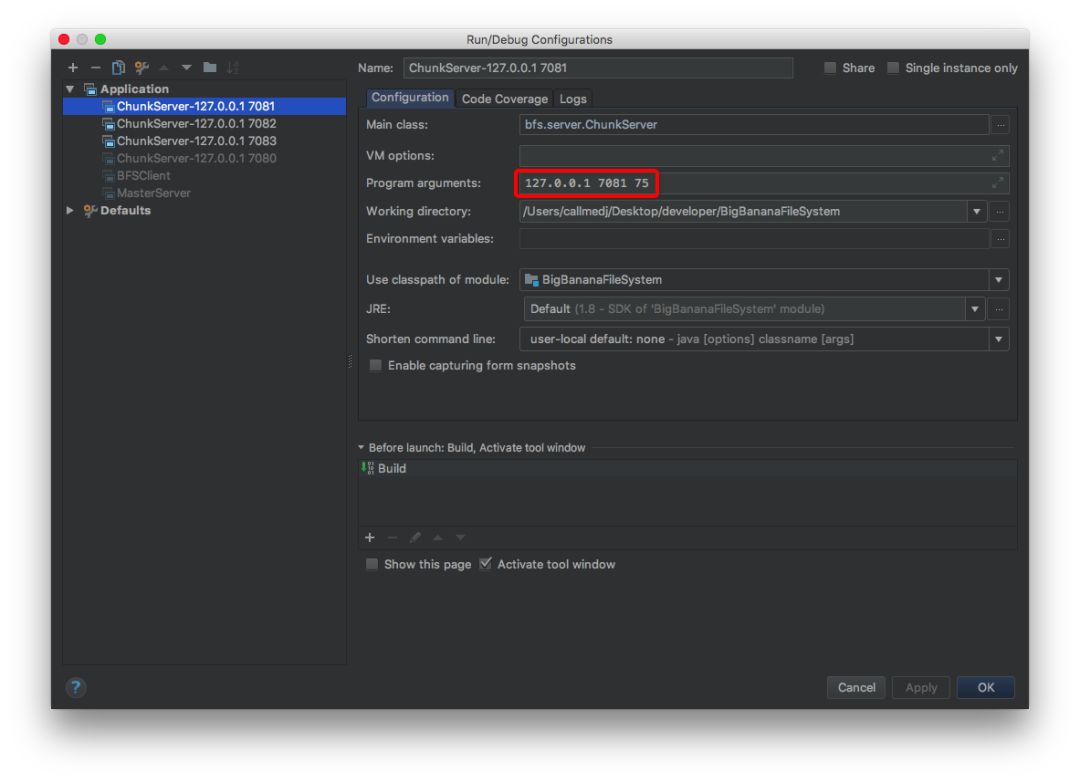
启动成功后,我们会看到,ChunkServer 的console 会提示,ChunkServer 自己提供了一个路径为 rmi://127.0.0.1:7081/chunk_server 的 rmi 服务,而且已经注册到了我们前端提供的master服务上。

这时候我们在master 的console 里面,也能看到我们的ChunkServer 成功注册到 Master 的提示。

扩展ChunkServer
为了实验效果,我们把ChunkServer 扩展到4台,端口和容量分别为 7080(50byte 容量) / 7081(75byte容量) / 7082(100byte容量) / 7083(200byte容量) 。
一个一个启动,全部启动完之后,在 master 上可以看到下面的日志,不需要做其他特别的操作,能看到这些这些代表已经启动并且扩容完成

启动 Client
Client 的入口类为 bfs.server.BFSClient ,没有特殊的参数。主要流程是请求master进行数据读取,master 获取数据所有的chunk块的元数据,然后把数据块chunk的位置及 chunkserver 的 ip 和端口给到client,由 client 直接跟 chunkserver 通信进行数据获取。
启动完之后能看到下面的操作提供,则表明client已经启动成功。
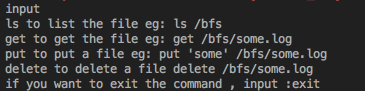
put一大批数据
我们在Client的Console敲命令行可以对文件系统进行基础的操作,比如放置文件 。put mytexstt /tmp/banana/trace2.log 等。
这时候我们可以看到 master 上也有存储成功的消息。
我们敲命令行 ls /tmp/banana ,也可以看到文件列表。
同时我们在各个ChunkServer 也能看到文件存储的md5值,完整容量以及已用容量。
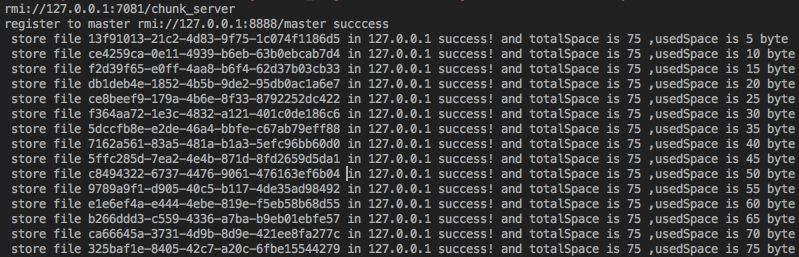
PS:关于这里的负载均衡,大家可以通过对比几个 ChunkServer 的增长速度,增长基本是均衡的,不会堆积在某个机器上,最终所有机器基本都被占满,已占满的机器不会再提供存储服务,除非文件被回收。
删除数据
比如我们想删除 trace10.log,我们可以这样敲命令 。
delete /tmp/banana/trace10.log
这时候Master 会把 trace10.log 文件名变更为 trace10.log.delete ,然后通过垃圾回收机制进行回收,我们可以在 Master 上看到这么两行日志。

第一行是代表文件在逻辑层面已经被删除,第二行代表垃圾回收机制已经把文件从元数据和 ChunkServer 上都进行了物理删除。我们可以从各个 ChunkServer 上看到,被切割的文件块也都被逐一删除,并且空间已经回归。
7080机器

7081机器

7082机器

7083机器

从这里我们可以看到,文件被切割成了两个块,而且复制了三个副本,存储在四台机器上,并且 ChunkServer 对这些文件的实际内容以及组织形式完全无感知。
关于文件检查恢复
机制已经实现了,但目前还没有找到很好的测试方法。基本逻辑就是检查Master上存储的md5跟ChunkServer文件提供的md5进行对比,如果不一致那肯定是文件出现了问题,将会对ChunkServer 上的文件块进行删除,并复制其他 ChunkServer 的合法的文件,如果三份都丢失那文件就真的丢失了。
好了,关于分布式文件系统的操作介绍就都在上面了,现在我们聊聊细节。
关于注册
注册是由 ChunkServer 调用 bfs.service.IMasterService#registerChunkServer 进行服务注册的。
关于Client的命令
命令是通过命令控制中心 bfs.command.CommandCenter#execute 进行命令的解析,分发,调用,返回的,所有支持的命令都实现了bfs.command.Command 接口,并且在初始化的时候注册到控制中心中,控制中心持有了 包括 Master 和 所有 ChunkServer 的懒加载单例模式句柄,可以非常方便地访问到集群所有机器的服务。
关于put
主要实现在 bfs.service.impl.BFSMaster#put ,主要逻辑是
1、先对文件进行切分,产生 Chunk并保存文件的源数据。
2、每一个块获取N个需要的可用服务器,并且对服务器容量进行提前占用,防止文件存储过程中的耗时导致超量存储导致磁盘容量溢出。
3、 对文件进行存储,并且存储Chunk 所在的服务器。
4、对服务器占用进行解除。
这里获取可用服务器实现了针对服务器负荷进行排序,优先获取负荷比较小的机器,当然如果机器数量本来就很小,比如我们这里只有4台,基于文件复制的基础要求(文件副本不能全部存储在同一个机器上),会发现一些负荷比较高的机器也会承担文件存储服务。
关于get
get 实现比较简单,只要一个Chunk一个Chunk进行查找,查找到任何一个可用的服务器就直接拿,然后对结果进行顺序拼装即可。
好了,BFS讲解大概就到这里了BFS系统源码的阅读顺序可以参照这个,主要看一个文件的放置,一个文件的获取,一个文件的删除,这三个看完基本就理解了。
bfs.command.CommandCenter 所有操作的控制封装,是 Client 操作的媒介。
bfs.service.IMasterService Master 提供的所有能力的接口
bfs.service.IChunkServerService ChunkServer 提供的所有能力的接口。
再安利一下 https://github.com/CallMeDJ/BigBananaFileSystem.git
再PS:今天我阳历生日,祝我生日快乐。
这篇关于分布式文件系统.get(V2)No.106的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





