本文主要是介绍第四章:NumPy基础Day6-7,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明:本文章为Python数据处理学习日志,记录内容为实现书本内容时遇到的错误以及一些与书本不一致的地方,一些简单操作则不再赘述。日志主要内容来自书本《利用Python进行数据分析》,Wes McKinney著,机械工业出版社。
1、ndarray
ndarray介绍
ndarray的说明:
Class docstring:
ndarray(shape, dtype=float, buffer=None, offset=0,strides=None, order=None)
An array object represents a multidimensional, homogeneous array of fixed-size items. An associated data-type object describes the format of each element in the array (its byte-order, how many bytes it occupies in memory, whether it is an integer, a floating point number, or something else, etc.)
Arrays should be constructed using
array,zerosorempty(refer to the See Also section below). The parameters given here refer to a low-level method (ndarray(...)) for instantiating an array.
参数介绍:
Parameters
shape : tuple of ints
Shape of created array.dtype : data-type, optional
Any object that can be interpreted as a numpy data type.buffer : object exposing buffer interface, optional
Used to fill the array with data.offset : int, optional
Offset of array data in buffer.strides : tuple of ints, optional
Strides of data in memory.order : {‘C’, ‘F’}, optional
Row-major (C-style) or column-major (Fortran-style) order.
属性:
Attributes
T : ndarray
Transpose of the array.data : buffer
The array’s elements, in memory.dtype : dtype object
Describes the format of the elements in the array.flags : dict
Dictionary containing information related to memory use, e.g.,’C_CONTIGUOUS’, ‘OWNDATA’, ‘WRITEABLE’, etc.flat : numpy.flatiter object
Flattened version of the array as an iterator. The iterator allows assignments, e.g.,x.flat = 3(Seendarray.flatfor
assignment examples; TODO).imag : ndarray
Imaginary part of the array.real : ndarray
Real part of the array.size : int
Number of elements in the array.itemsize : int
The memory use of each array element in bytes.nbytes : int
The total number of bytes required to store the array data, i.e.,itemsize * size.ndim : int
The array’s number of dimensions.shape : tuple of ints
Shape of the array.strides : tuple of ints
The step-size required to move from one element to the next in memory. For example, a contiguous(3, 4)array of typeint16in C-order has strides(8, 2). This implies that to move from element to element in memory requires jumps of 2 bytes.To move from row-to-row, one needs to jump 8 bytes at a time(2 * 4).ctypes : ctypes object
Class containing properties of the array needed for interaction with ctypes.base : ndarray
If the array is a view into another array, that array is itsbase(unless that array is also a view). Thebasearray is where
the array data is actually stored.
书本注
P87 astype函数
转化为int则会报错:
num_strings = np.array(['1.25','-9.6','42'],dtype = np.string_)num_strings.dtype
Out[40]: dtype('S4')num_strings.astype(float64)
Out[41]: array([ 1.25, -9.6 , 42. ])num_strings.astype(int)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-42-6d0676c88a7e> in <module>()
----> 1 num_strings.astype(int)ValueError: invalid literal for int() with base 10: '1.25' P89视图与copy
用“=”定义新的数组,改变其一,另一个都会随之变化:
arr = np.arange(10)arr
Out[78]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])arr1 = arrarr1
Out[80]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])arr1[3:5]=233arr1
Out[82]: array([ 0, 1, 2, 233, 233, 5, 6, 7, 8, 9])arr
Out[83]: array([ 0, 1, 2, 233, 233, 5, 6, 7, 8, 9])arr[3:5]=0arr
Out[98]: array([0, 1, 2, 0, 0, 5, 6, 7, 8, 9])arr1
Out[99]: array([0, 1, 2, 0, 0, 5, 6, 7, 8, 9])若不想这样,可以用copy()函数得到副本而非视图:
arr = np.arange(10)arr1 = arr.copy()arr
Out[103]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])arr1
Out[104]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])arr1[5:8] = 233arr1
Out[106]: array([ 0, 1, 2, 3, 4, 233, 233, 233, 8, 9])arr
Out[107]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])arr[1:3] = 666arr
Out[109]: array([ 0, 666, 666, 3, 4, 5, 6, 7, 8, 9])arr1
Out[110]: array([ 0, 1, 2, 3, 4, 233, 233, 233, 8, 9])P90三维array
arr3d = np.array([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])存储方式如下图:
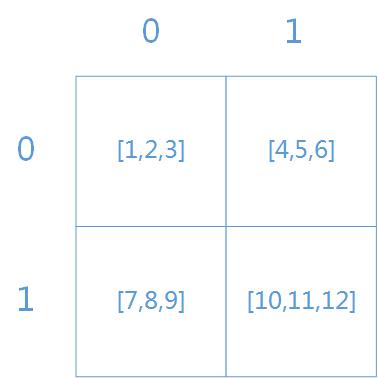
参考上图,则容易理解以下操作结果:
arr3d[0]
Out[15]:
array([[1, 2, 3],[4, 5, 6]])arr3d[0,0]
Out[16]: array([1, 2, 3])arr3d[:,:1]
Out[17]:
array([[[1, 2, 3]],[[7, 8, 9]]])arr3d[:,:1,1:]
Out[18]:
array([[[2, 3]],[[8, 9]]])P93二维array的切片
尽管选取的元素是一样的,但格式上是有差别的:
arr2d[2,:].shape
Out[20]: (3L,)arr2d[2:,:].shape
Out[21]: (1L, 3L)arr2d[2,:]
Out[22]: array([7, 8, 9])arr2d[2:,:]
Out[23]: array([[7, 8, 9]]) #这里多一层[]P93布尔型索引
注意维度:
data[names == 'Bob'] #选中为True的行
Out[40]:
array([[ 0.50050011, 0.29686535, -0.28906449, 2.01808417],
[ 1.11494101, 0.16982801, 0.71012665, 0.27181318]])data[names == 'Bob',3] #此时的3为列
Out[41]: array([ 2.01808417, 0.27181318])data[names == 'Bob'][1] #此时1为行
Out[43]: array([ 1.11494101, 0.16982801, 0.71012665, 0.27181318])data[names == 'Bob'][1,2] #此时1为行,2为列
Out[44]: 0.71012664552279547P94选择除“Bob”以外的值
负号(-)用于逻辑计算是deprecated,建议使用“~”:
data[-(names == 'Bob')]
-c:1: DeprecationWarning: numpy boolean negative, the `-` operator, is deprecated, use the `~` operator or the logical_not function instead.
Out[45]:
array([[ 0.14050569, 0.3441191 , -1.33003662, 0.42766074],[-0.45652879, -1.51870623, -2.45291715, 0.86532186],[ 0.775377 , -0.73127956, 0.02678242, -0.73168782],[ 0.80537817, -1.1611737 , 1.31483485, 1.79852968],[-0.07039251, 0.1692129 , -1.7043453 , 0.03626713]])data[~(names == 'Bob')]
Out[46]:
array([[ 0.14050569, 0.3441191 , -1.33003662, 0.42766074],[-0.45652879, -1.51870623, -2.45291715, 0.86532186],[ 0.775377 , -0.73127956, 0.02678242, -0.73168782],[ 0.80537817, -1.1611737 , 1.31483485, 1.79852968],[-0.07039251, 0.1692129 , -1.7043453 , 0.03626713]])P95花式索引
索引并不是按值来索引,而是按行。即[4,3,0,6]为行,而并非值,书上例子易误解:
for i in range(8):arr[i]=i*iarr
Out[67]:
array([[ 0., 0., 0., 0.],[ 1., 1., 1., 1.],[ 4., 4., 4., 4.],[ 9., 9., 9., 9.],[ 16., 16., 16., 16.],[ 25., 25., 25., 25.],[ 36., 36., 36., 36.],[ 49., 49., 49., 49.]])arr[[4,3,2,6]]
Out[68]:
array([[ 16., 16., 16., 16.],[ 9., 9., 9., 9.],[ 4., 4., 4., 4.],[ 36., 36., 36., 36.]])arr[[-3,-1,-7]]
Out[69]:
array([[ 25., 25., 25., 25.],[ 49., 49., 49., 49.],[ 1., 1., 1., 1.]])2、通用函数
实际上是对数组的每一个元素进行运算,用通用函数会方便许多,完全不用写任何循环!!!
3、利用数组进行数据处理
示例实现结果图:
函数说明
mean()函数(其他如sum均类似,不赘述)
Signature:
mean(a, axis=None, dtype=None, out=None, keepdims=False)
Docstring:
Compute the arithmetic mean along the specified axis.Returns the average of the array elements. The average is taken over the flattened array by default, otherwise over the specified axis.
float64intermediate and return values are used for integer inputs.Parameters:
a : array_like
Array containing numbers whose mean is desired. Ifais not an array, a conversion is attempted.
axis : None or int or tuple of ints, optional
Axis or axes along which the means are computed. The default is to compute the mean of the flattened array. If this is a tuple of ints, a mean is performed over multiple axes,instead of a single axis or all the axes as before.
dtype : data-type, optional
Type to use in computing the mean. For integer inputs, the default isfloat64; for floating point inputs, it is the same as the input dtype.
out : ndarray, optional
Alternate output array in which to place the result. The default isNone; if provided, it must have the same shape as the expected output, but the type will be cast if necessary.Seedoc.ufuncsfor details.
keepdims : bool, optional
If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the originalarr.Returns
m : ndarray, see dtype parameter above
Ifout=None, returns a new array containing the mean values, otherwise a reference to the output array is returned.
书本注
P103逻辑运算
分别实现三种方法,第三个表达式似乎有点问题。第三种方法同样因为版本问题,有些符号需要更改,如求反改“-”为“~”,亦或改“-”为“^”(这里实际上并不是求亦或,而是表达式出了问题):
cond1 = array([True,True,False,False])cond2 = array([True,False,True,False])result1=[]for i in range(4):if cond1[i] and cond2[i]:result1.append(0)elif cond1[i]:result1.append(1)elif cond2[i]:result1.append(2)else:result1.append(3)result1
Out[179]: [0, 1, 2, 3]result2 = np.where(cond1&cond2,0,np.where(cond1,1,np.where(cond2,2,3)))result2
Out[181]: array([0, 1, 2, 3])result3 = 1*(cond1-cond2)+2*(cond2& -cond1)+3* -(cond1|cond2)
-c:1: DeprecationWarning: numpy boolean subtract, the `-` operator, is deprecated, use the bitwise_xor, the `^` operator, or the logical_xor function instead.
-c:1: DeprecationWarning: numpy boolean negative, the `-` operator, is deprecated, use the `~` operator or the logical_not function instead.result3
Out[184]: array([0, 1, 3, 3])result3 = 1*(cond1^cond2)+2*(cond2&~cond1)+3*~(cond1|cond2)result3
Out[186]: array([0, 1, 3, 3])该逻辑的卡诺图为下图:
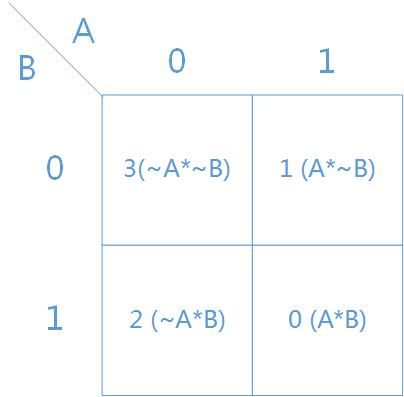
表达式为:
F(AB)=0×AB+1×A¯B+2×AB¯+3×A¯B¯
应将表达式修改为:
result3 = 1*(cond1&~cond2)+2*(cond2&~cond1)+3*~(cond1|cond2)result3
Out[188]: array([0, 1, 2, 3])P104数学和统计方法
在此说明一些mean()的参数axis(其他方法的参数axis均与mean()函数相同):
arr = random.randn(5,4) #Canopy中默认了很多东西,此处可以不加np.arr
Out[214]:
array([[-1.35496721, -0.15978328, 0.38585305, -0.31769088],[ 1.02980411, -0.66722211, 0.7295801 , -1.08059653],[-0.78498058, -1.32036524, 0.96689313, -0.72398153],[ 0.1016877 , 1.3240266 , 1.70886154, -0.60597185],[-1.79229484, -2.20550415, 0.69782981, 0.68054199]])arr.mean(1) #此处的参数1即为axis的值,延axis1计算,故计算结果为每一行的平均值
Out[215]: array([-0.36164708, 0.0028914 , -0.46560855, 0.632151 , -0.6548568 ])arr.mean(0) #此处的参数0也为axis的值,延axis0计算,故计算结果为每一列的平均值
Out[216]: array([-0.56015016, -0.60576964, 0.89780353, -0.40953976])arr.mean(2) #因为arr为二维数组,axis并没有2,故报错
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-217-9e6caf702904> in <module>()
----> 1 arr.mean(2) #因为arr为二维数组,axis并没有2,故报错E:\Enthought\hzk\User\lib\site-packages\numpy\core\_methods.pyc in _mean(a, axis, dtype, out, keepdims)54 arr = asanyarray(a)55
---> 56 rcount = _count_reduce_items(arr, axis)57 # Make this warning show up first58 if rcount == 0:E:\Enthought\hzk\User\lib\site-packages\numpy\core\_methods.pyc in _count_reduce_items(arr, axis)48 items = 149 for ax in axis:
---> 50 items *= arr.shape[ax]51 return items52 IndexError: tuple index out of range arr3d = random.randn(3,3,3)arr3d
Out[219]:
array([[[-0.44556533, 1.38462328, -0.41991462],[-0.94348762, 0.24127859, 0.10032657],[-1.00207669, 0.09779813, 1.39707048]],[[ 1.82511376, 0.21457405, 0.2793703 ],[-2.52457174, -0.48253527, 0.11162123],[ 1.32029231, 1.25795631, -0.86304957]],[[ 1.2496241 , 0.60886197, -0.79459398],[-3.11245287, 1.19690542, 0.59970726],[-0.75850899, 1.11220732, 0.7452851 ]]])arr3d.mean(2) #改为三维数组则不会报错
Out[220]:
array([[ 0.17304778, -0.20062749, 0.16426397],[ 0.77301937, -0.96516193, 0.57173302],[ 0.3546307 , -0.43861339, 0.36632781]])注意:axis参数0,1,指的是延axis0或axis1计算,这一点可以从cumsum()和cumprod()函数中体现出了:
arr = array([[1,2,3],[4,5,6],[7,8,9],[10,11,12]])arr
Out[231]:
array([[ 1, 2, 3],[ 4, 5, 6],[ 7, 8, 9],[10, 11, 12]])arr.cumsum(0)
Out[232]:
array([[ 1, 2, 3],[ 5, 7, 9],[12, 15, 18],[22, 26, 30]])arr.cumsum(1)
Out[233]:
array([[ 1, 3, 6],[ 4, 9, 15],[ 7, 15, 24],[10, 21, 33]])arr.cumprod(0)
Out[234]:
array([[ 1, 2, 3],[ 4, 10, 18],[ 28, 80, 162],[ 280, 880, 1944]])arr.cumprod(1)
Out[235]:
array([[ 1, 2, 6],[ 4, 20, 120],[ 7, 56, 504],[ 10, 110, 1320]])二维数组的axis示意图为:
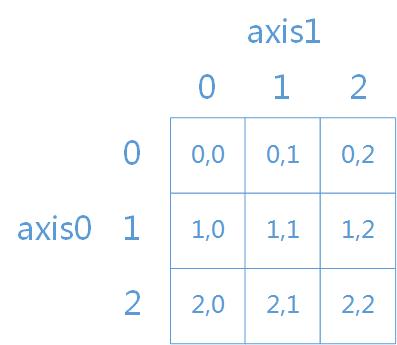
5、用于数组的文件输入输出
存的文件名最好不要带空格“ ”,尽量用下划线“_”代替,不然按Tab键无法自动加载。
6、线性代数
书本注
P110矩阵运算
可能是精度问题,计算 XX−1 并不得单位矩阵 E <script type="math/tex" id="MathJax-Element-3">E</script>:
x = array(randn(5,5),dtype='f')x
Out[328]:
array([[-0.22578056, 0.11948908, -0.34033489, -1.17195463, 0.03571514],[-0.32171333, 0.30542919, -2.02457905, -0.58019698, -0.97900975],[-0.66901571, -1.31925774, -1.30758452, 1.68790388, 0.91629416],[ 1.85947955, 0.29689333, 0.06040272, -0.38136303, 1.94833517],[ 1.61013746, 0.54303652, -1.0496527 , 1.74626613, 0.73138028]], dtype=float32)inv(x)
Out[329]:
array([[-3.83887243, 1.60917497, -0.23554267, 1.54410875, -1.47681177],[ 5.01534271, -2.0442934 , -0.20324162, -1.94631255, 2.45808005],[-0.25406945, -0.28958428, -0.14813125, -0.02293177, -0.12855303],[ 0.56339014, -0.47421208, 0.07606155, -0.51252431, 0.6077475 ],[ 3.0176971 , -1.30811489, 0.27525163, -0.7634539 , 1.15783525]], dtype=float32)dot(x,inv(x))
Out[330]:
array([[ 1.00000000e+00, -1.49011612e-08, 4.65661287e-09,-3.72529030e-09, -8.19563866e-08],[ 2.38418579e-07, 9.99999881e-01, 0.00000000e+00,-5.96046448e-08, 0.00000000e+00],[ 4.76837158e-07, 1.19209290e-07, 1.00000000e+00,5.96046448e-08, 0.00000000e+00],[ 0.00000000e+00, 2.38418579e-07, -5.96046448e-08,1.00000012e+00, -2.38418579e-07],[ -2.38418579e-07, 0.00000000e+00, 0.00000000e+00,0.00000000e+00, 1.00000012e+00]], dtype=float32)7、范例:随机漫步
书本注
P112
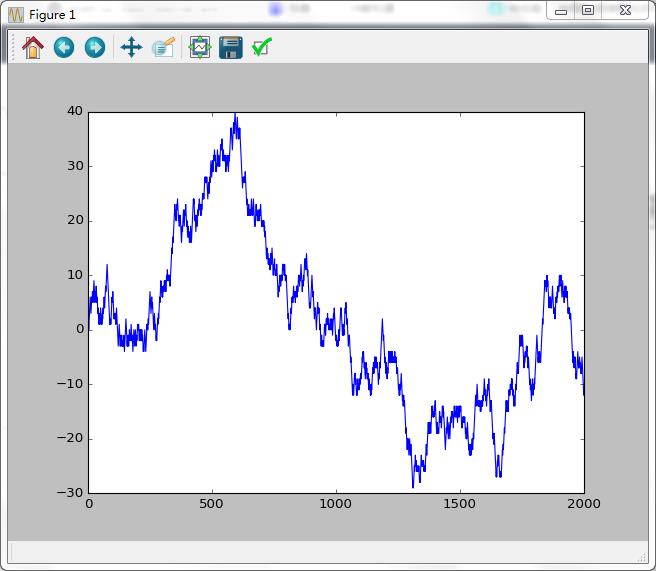
绘图直接用代码:
plot(walk)
Out[351]: [<matplotlib.lines.Line2D at 0x157ae7f0>]结果:
这篇关于第四章:NumPy基础Day6-7的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





