本文主要是介绍C++编译和内存细节,可能存在的隐患,面试题03,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 11. C++编译过程
- 11.1. #include<file.h> vs #include"file.h"
- 11.2. 声明 vs 定义
- 11.3. extern “C” 的作用
- 11.4. typedef vs #define
- 12. const vs #define
- 12.1. 全局const vs 局部const
- 13. C++内存分区
- 13.1. 什么是内存泄漏?如何检测内存泄漏?
- 13.2. 大项目如何调试死锁?
- 13.3. volatile关键字作用
- 13.4. 栈溢出的原因及解决
- 14. C++变量作用域
- 14.1. 常量 vs 全局变量 vs 静态变量
- 15. C++类型转换
- 16. 函数指针
- 17. 悬空指针 vs 野指针
- 18. 为什么使用空指针,建议使用nullptr而不是NULL?
11. C++编译过程
- 预处理:处理以#开头的预处理指令,比如#include和#define等。
- 编译:将预处理后的源文件转汇编代码。
- 汇编:将汇编代码转机器指令,生成目标文件。
- 链接:将目标文件与相应的库文件进行链接,生成可执行文件。
11.1. #include<file.h> vs #include"file.h"
- 相同:都是预处理指令,用于包含头文件。
- 区别
- 使用<> 包含标准库的头文件,从标准库路径寻找。
- 使用 “” 包含用于自定义的头文件,从当前工作路径寻找。
11.2. 声明 vs 定义
- 声明是告诉编译器函数或类的存在,但不提供具体实现;或者变量存在,但不分配内存空间。如变量声明 extern int x; 只是告诉编译器变量的类型和名称。
- 定义是对函数或类的具体实现;对变量分配内存空间并赋初值。
11.3. extern “C” 的作用
- 由于C++支持函数重载,就是函数在编译期间,链接符号的时候,会在符号后追加一些特殊标识,而C不支持函数重载。使用extern “C” 可以告诉编译器将函数声明按照C语言的链接规范处理,这样可以使C++函数在C环境调用时正确链接到对应的函数,即是为了解决函数符号名的问题。
11.4. typedef vs #define
- 相同:都可以创建类型别名,代码如下。
typedef (int*) p1;
#define p2 int*
-
区别
- 处理阶段:
- #define在预处理阶段进行替换,如 p2 a,b; 等同于 int* a, b;
- typedef 在编译阶段进行替换,如 p1 a,b; 等同于 int* a;int* b;
- 类型安全:
- #define只是简单的字符串替换,不进行类型检查,存在隐患。
- typedef 它是给已有类型取别名,在编译时进行类型检查。
- 作用域:
- #define是在整个文件作用域。
- typedef是在当前文件作用域。
- 处理阶段:
12. const vs #define
- 相同:都可以定义常量,代码如下。
#define MAX_SIZE 100
const int value = 50;-
区别
- 处理阶段:
- #define在预处理阶段进行替换。
- const在编译阶段确定其值。
- 类型安全:
- #define只是简单的字符串替换,不进行类型检查,存在隐患。
- const有数据类型,在编译时进行类型检查。
- 存储方式:
- #define有多少次替换,在内存中有多少个拷贝。
- const定义的常量会分配内存空间,且在程序运行过程中内存只有一个拷贝。
- 调试信息:
- #define只是替换,不会产生调试信息。
- const被视为变量,可以产生调试信息。如下图。

- 另外,#define可以定义简单的函数,而const不可以定义函数。
- 处理阶段:
12.1. 全局const vs 局部const
- 全局const存储在常量区,无法通过指针修改。
- 局部const存储在栈区,是一个“假”常量,始终是一个变量,只是编译时进行语法检查,发现代码有对const修饰的变量修改时则报错。本质上时可以修改的,利用指针获取变量地址,强制将const属性修饰去掉,就可以修改对应内容,【注意】 会造成未定义行为。代码如下。
void print(const int& a)
{cout << a << endl;
}int main() {const int num = 50; //局部constint* p = const_cast<int*>(&num); //使用const_cast<>强制将const属性去掉*p = 20; //通过指针修改内容print(num);return 0;
}
- 程序执行结果,如下图。

- 分析:当print()函数的参数是引用或指针时,会传入修改后的const内容,而不会因为编译器的优化,即常量折叠,在编译时就替换。这是不当的操作。
13. C++内存分区
- 堆:用于动态分配内存,使用new或malloc手动分配,使用delete或free手动释放,注意内存泄漏的问题。
- 栈:存储局部变量和函数调用的控制信息,如返回地址、参数、局部变量等,由系统自动分配和释放。
- 全局区:存放全局变量、静态变量,程序结束后由系统释放。
- 常量区:存放字符串常量等,程序结束后由系统释放。
- 代码区:存放程序的二进制代码。
13.1. 什么是内存泄漏?如何检测内存泄漏?
- 动态分配内存,使用后未释放,导致一直占据该内存,即内存泄漏。
- 在main()的return 0前,使用CRT库检查内存泄漏,然后观察输出的调试窗口。如果有动态分配的内存没有释放,就会输出相应的内存泄漏信息。但如果没有释放的内存是对象内存,这时候还需要在return 0处设置断点并进行调试,通过反汇编分析,借助内存窗口和寄存器窗口,观察析构函数是否正确释放对象内存,来作进一步判断。
13.2. 大项目如何调试死锁?
- 获取程序dump文件,使用WinDbg工具打开并分析线程,检查线程是否挂起,然后根据线程的堆栈信息找到每个线程的入口点,进行动态分析以确定死锁原因。
13.3. volatile关键字作用
- voletile修饰的变量,会从内存中重新装载内容,而不是直接从寄存器中拷贝内容。为了解决变量在共享环境下容易出现读取错误的问题。
13.4. 栈溢出的原因及解决
- 原因
- 函数调用层次过深,每调用一次,函数的参数、局部变量等信息就压一次栈。
- 函数的局部变量体积过大。
- 解决
- 使用堆内存,如把数组改成数组指针,然后动态分配内存。
- 可以把局部变量改成静态局部变量,相当于作用域在函数内的全局变量。
14. C++变量作用域
- 全局变量属于进程作用域,在整个进程中都可以访问到。
- 静态变量属于文件作用域,在当前源码文件内可以访问到。
- 局部变量属于函数作用域,在函数内可以访问到。
- 在’{ }'语句块内定义的变量属于块作用域,只能在该块内访问。
14.1. 常量 vs 全局变量 vs 静态变量
- 相同:程序执行前就存在了,即在编译期就已经确定了地址。通过立即数访问。
- 区别:作用域和内存分配
- 常量
- 全局常量,存放在常量区(只读数据段),整个文件内都可以访问到。
- 局部常量,存放在栈区,在函数内可以访问到。
- 全局变量,存放在全局区(可读写数据段),整个文件内都可以访问到。
- 静态变量
- 全局静态变量,存放在全局区(可读写数据段),当前文件内可以访问到。
- 局部静态变量,存放在全局区(可读写数据段),在函数内可以访问到。
- 常量
15. C++类型转换
- 隐式类型转换由编译器自动完成
- char,short——>int——>unsigned——>long——>double
- float ——>double
- 显式类型转换手工强制完成
- 使用()。
- 标准转型操作符,能够避免许多任意转型引起的潜在错误。
- 四种标准转型操作符,示例如下。
- const_cast:去除或添加const、volatile属性。
int num = 42;
const int* p = const_cast<const int*>(&num); //添加const修饰
- static_cast:用于常规类型转换,如数值之间的转换、指针或引用之间的转换。
double d = 3.14;
int i = static_cast<int>(d); //将double转int
- dynamic_cast:用于多态对象(即存在虚函数的对象)间类型转换,将基类指针或引用转换为子类指针或引用,从而访问子类特有的成员函数。【注意】 引用转型失败会抛异常”bad_cast“;指针转型失败会返回一个空指针,如果漏写检查代码(assert/if语句)会导致安全隐患。
class Draw
{
public:virtual ~Draw(){}virtual void drawLen() = 0;
};class Circle : public Draw
{
private:double radius; public:Circle(double r) : radius(r){}~Circle() { printf("%s%f\n", "Delete circle with radius ",radius); }void getDescription() { printf("%s%f\n", "Circle with radius ",radius);}void drawLen() { printf("%s%f\n", "Circle with len ", 2 * 3.14 * radius); }
};int main()
{Draw* d = new Circle(5); //基类指针指向子类对象d->drawLen();Circle* c = dynamic_cast<Circle*>(d); //将基类指针转子类指针if(c!=nullptr) c->getDescription(); //访问子类特有的成员函数delete d; return 0;
}- reinterpret_cast:对目标的内存二进制位进行低层次的重新解释。如将指针转换为整数、不同类型的指针之间的转换。【注意】 它会忽略指针类型和数据之间的任何差异,存在安全隐患,因此需要谨慎使用。
int num = 20;
double* d = reinterpret_cast<double*>(&num); //将int*转double*
16. 函数指针
- 函数调用是直接调用的;而函数指针是先取出指针的值(函数地址)再调用,是间接调用的。
- 应用场景
- 实现回调函数,比如在图形用户界面中,可以使用函数指针指定按钮点击事件的响应函数。
- 把函数指针当形参传递给某些具有通用功能的模块,并封装成接口来提高代码的灵活性,方便后期维护。
- 可以在排序和搜索算法中,使用函数指针提供自定义的比较逻辑,比如升序、降序,如下。
#include<iostream>
#include<vector>
using namespace std;//定义比较函数指针类型
using CompareFunction = bool(*)(int, int);// 冒泡排序,传入比较函数指针
void bubbleSort(vector<int>& arr, CompareFunction compare) {int n = arr.size();for (int i = 0; i < n - 1; ++i) for (int j = 0; j < n - i - 1; ++j) if (compare(arr[j], arr[j + 1])) swap(arr[j], arr[j + 1]);
}//升序
bool ascending(int a, int b) {return a > b;}// 降序
bool descending(int a, int b) { return a < b;}int main()
{vector<int> numbers = { 5, 2, 8, 1, 4 };// 使用升序cout << "Ascending order:" << std::endl;bubbleSort(numbers, ascending);for (auto && u : numbers) { cout << u << " ";}// 使用降序cout << endl << "Descending order:" <<endl;bubbleSort(numbers, descending);for (auto&& u : numbers) { cout << u << " "; }return 0;
}
- 程序执行结果,如下图。
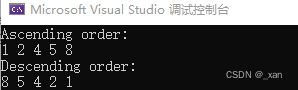
17. 悬空指针 vs 野指针
- 悬空指针:当指向的内存被释放后,指针没有被及时置空。【注意】 访问悬空指针会导致未定义行为,如下。
int* ptr = new int(42);
delete ptr;*ptr = 20; //错误,访问悬空指针会导致未定义行为。
- 野指针:指针没有被初始化。【注意】 野指针的值是不确定的,可能指向任意的内存地址,访问野指针会导致未定义行为,如下。
int* ptr;*ptr = 20; //错误,访问野指针会导致未定义行为。
18. 为什么使用空指针,建议使用nullptr而不是NULL?
- nullptr是空指针常量,可以隐式转换成任意指针类型,但不会自动转换为整数类型;而NULL是宏,整数类型,【注意】 可能会导致类型安全问题,如下。
void f(int a) {cout << "parameter int" << endl;}void f(void* a) { cout << "parameter void*" << endl;}int main() {f(NULL); //调用f(int)f(nullptr); //调用f(void*)return 0;
}这篇关于C++编译和内存细节,可能存在的隐患,面试题03的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





