本文主要是介绍【 PowerJob 的使用 -分布式调度】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PowerJob 的使用
最近项目中使用了PowerJob做任务调度模块,感觉这个框架真香,今天我们就来深入了解一下新一代的定时任务框架——PowerJob!
简介
PowerJob是基于java开发的企业级的分布式任务调度平台,与xxl-job一样,基于web页面实现任务调度配置与记录,使用简单,上手快速,其主要功能特性如下:
- 使用简单:提供前端Web界面,允许开发者可视化地完成调度任务的管理(增、删、改、查)、任务运行状态监控和运行日志查看等功能。
- 定时策略完善:支持 CRON 表达式、固定频率、固定延迟和API四种定时调度策略。
- 执行模式丰富:支持单机、广播、Map、MapReduce 四种执行模式,其中 Map/MapReduce 处理器能使开发者寥寥数行代码便获得集群分布式计算的能力。
- 工作流支持:支持在线配置任务依赖关系(DAG),以可视化的方式对任务进行编排,同时还支持上下游任务间的数据传递,以及多种节点类型(判断节点 & 嵌套工作流节点)。
- 执行器支持广泛:支持 Spring Bean、内置/外置 Java 类,另外可以通过引入官方提供的依赖包,一键集成 Shell、Python、HTTP、SQL 等处理器,应用范围广。
- 运维便捷:支持在线日志功能,执行器产生的日志可以在前端控制台页面实时显示,降低 debug 成本,极大地提高开发效率。
- 依赖精简:最小仅依赖关系型数据库(MySQL/PostgreSQL/Oracle/MS SQLServer…)
- 高可用 & 高性能:调度服务器经过精心设计,一改其他调度框架基于数据库锁的策略,实现了无锁化调度。部署多个调度服务器可以同时实现高可用和性能的提升(支持无限的水平扩展)。
- 故障转移与恢复:任务执行失败后,可根据配置的重试策略完成重试,只要执行器集群有足够的计算节点,任务就能顺利完成。
相对于其他定时任务框架具有无锁化设计,更强悍的性能支撑,我们通过官网的产品对比可以了解详情:
| 项目 | QuartZ | xxl-job | SchedulerX 2.0 | PowerJob |
|---|---|---|---|---|
| 定时类型 | CRON | CRON | CRON、固定频率、固定延迟、OpenAPI | CRON、固定频率、固定延迟、OpenAPI |
| 任务类型 | 内置Java | 内置Java、GLUE Java、Shell、Python等脚本 | 内置Java、外置Java(FatJar)、Shell、Python等脚本 | 内置Java、外置Java(容器)、Shell、Python等脚本 |
| 分布式任务 | 无 | 静态分片 | MapReduce 动态分片 | MapReduce 动态分片 |
| 在线任务治理 | 不支持 | 支持 | 支持 | 支持 |
| 日志白屏化 | 不支持 | 支持 | 不支持 | 支持 |
| 调度方式及性能 | 基于数据库锁,有性能瓶颈 | 基于数据库锁,有性能瓶颈 | 不详 | 无锁化设计,性能强劲无上限 |
| 报警监控 | 无 | 邮件 | 短信 | 邮件,提供接口允许开发者扩展 |
| 系统依赖 | 关系型数据库(MySQL、Oracle…) | MySQL | 人民币 | 任意 Spring Data Jpa支持的关系型数据库(MySQL、Oracle…) |
| DAG 工作流 | 不支持 | 不支持 | 支持 | 支持 |
官网文档:http://www.powerjob.tech/
定时任务类型
与传统的定时任务框架对比,powerJob支持更多的定时任务类型:
- API: 通过客户端提供的api接口触发,服务端不会主动调度,适用于与业务服务上下连接或只调度一次的业务场景
- CRON: 通过cron表达式调度,这是多数定时任务框架都支持的
- 固定频率:每隔多少毫秒执行一次。
- 固定延迟:延迟多少毫秒执行一次
- 工作流:配合工作流进行调度,服务端不会主动调度,当工作流节点执行到该任务时运行。
安装
PowerJob支持两种安装方式,一是通过jar包运行,一是通过docker安装
docker的安装较为简单,且官网有详细说明,这里就不单独讲解了,大家可参考官方文档:
- https://www.yuque.com/powerjob/guidence/docker-compose
如何通过jar形式运行的
1、首先我们可以在github上下载源码,可以自己编译打包
- https://github.com/PowerJob/PowerJob
可以在releases中下载指定版本
2、在IDE中打开后,我们 powerjob-server就是我们要的服务端源码,可以直接编译,而 powerjob-worker-samples就是springboot下的使用示例
3、在运行编译服务端之前,我们需要先创建数据库,在指定的数据库下创建即可
CREATE DATABASE IF NOT EXISTS `powerjob-daily` DEFAULT CHARSET utf8mb4
4、然后将 powerjob-server/powerjob-server-starter下的 application-daily.properties配置文件中的数据库配置改成你服务器的
其中daily,pre,product 表示日常、预生产、生产环境下的配置,与我们常见的dev, test, prod类似,可以根据需要进行调整
oms.env=DAILY
logging.config=classpath:logback-dev.xml####### 外部数据库配置(需要用户更改为自己的数据库配置) #######
spring.datasource.core.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.core.jdbc-url=jdbc:mysql://localhost:3306/powerjob-daily?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
spring.datasource.core.username=root
spring.datasource.core.password=No1Bug2Please3!
spring.datasource.core.hikari.maximum-pool-size=20
spring.datasource.core.hikari.minimum-idle=5####### mongoDB配置,非核心依赖,通过配置 oms.mongodb.enable=false 来关闭 #######
oms.mongodb.enable=true
spring.data.mongodb.uri=mongodb://localhost:27017/powerjob-daily####### 邮件配置(不需要邮件报警可以删除以下配置来避免报错) #######
spring.mail.host=smtp.163.com
spring.mail.username=zqq@163.com
spring.mail.password=GOFZPNARMVKCGONV
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true####### 资源清理配置 #######
oms.instanceinfo.retention=1
oms.container.retention.local=1
oms.container.retention.remote=-1####### 缓存配置 #######
oms.instance.metadata.cache.size=1024####### 用户与权限体系配置 #######
oms.auth.initiliaze.admin.password=powerjob_admin
其中还有邮箱及其他配置,如果有需要也可以调整,服务端的参数配置可参考官网文档。
4、我们先来本地运行启动类PowerJobServerApplication一下试试,启动成功后,访问http://localhost:7700,出现登陆页则说明运行成功
5、启动客户端项目,运行成功后,可以在服务端首页看到机器实例

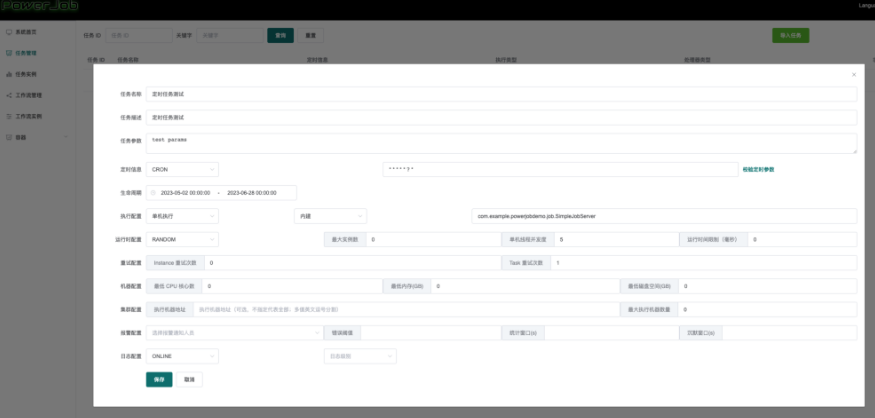
6、服务端任务管理点击新建任务
其中处理器配置是通过书写处理器的全类路径名来声明的,比如我这里是 com.example.powerjobdemo.job.SimpleJobServer
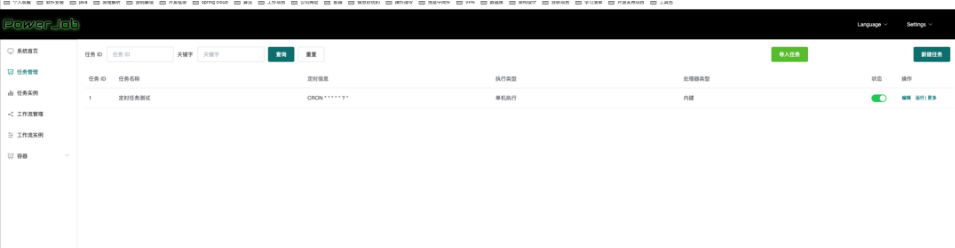
7、创建成功后,可以在列表看到新建的任务
8、打开客户端控制台,也能看到输出的参数和执行打印,说明任务执行成功

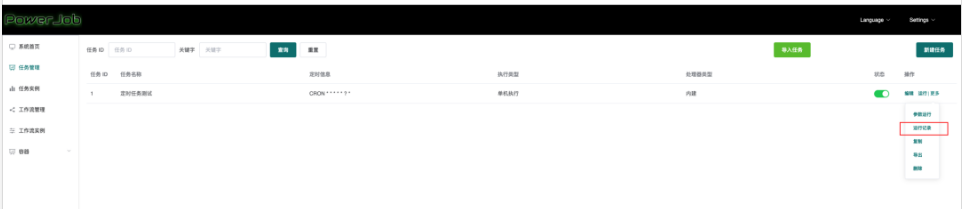
9、同时我们可以在运行记录中看到执行日志
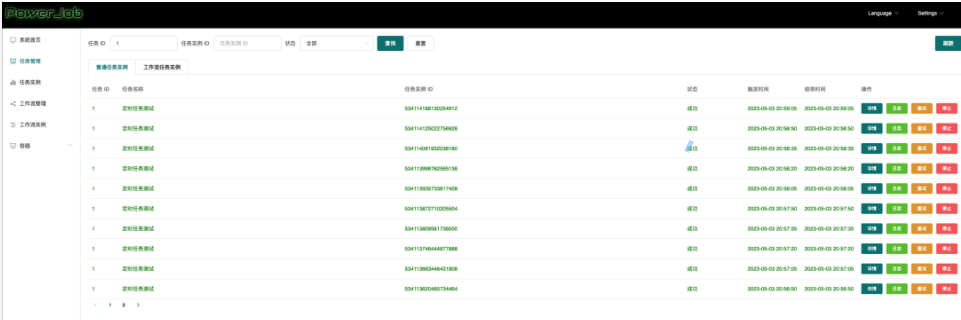
至此,针对powerjob的最简单使用就完成了,接下来我们继续来看关于powjob的配置详解
3. 任务配置参数详解
创建任务时我们可以看到如下图所示的配置:
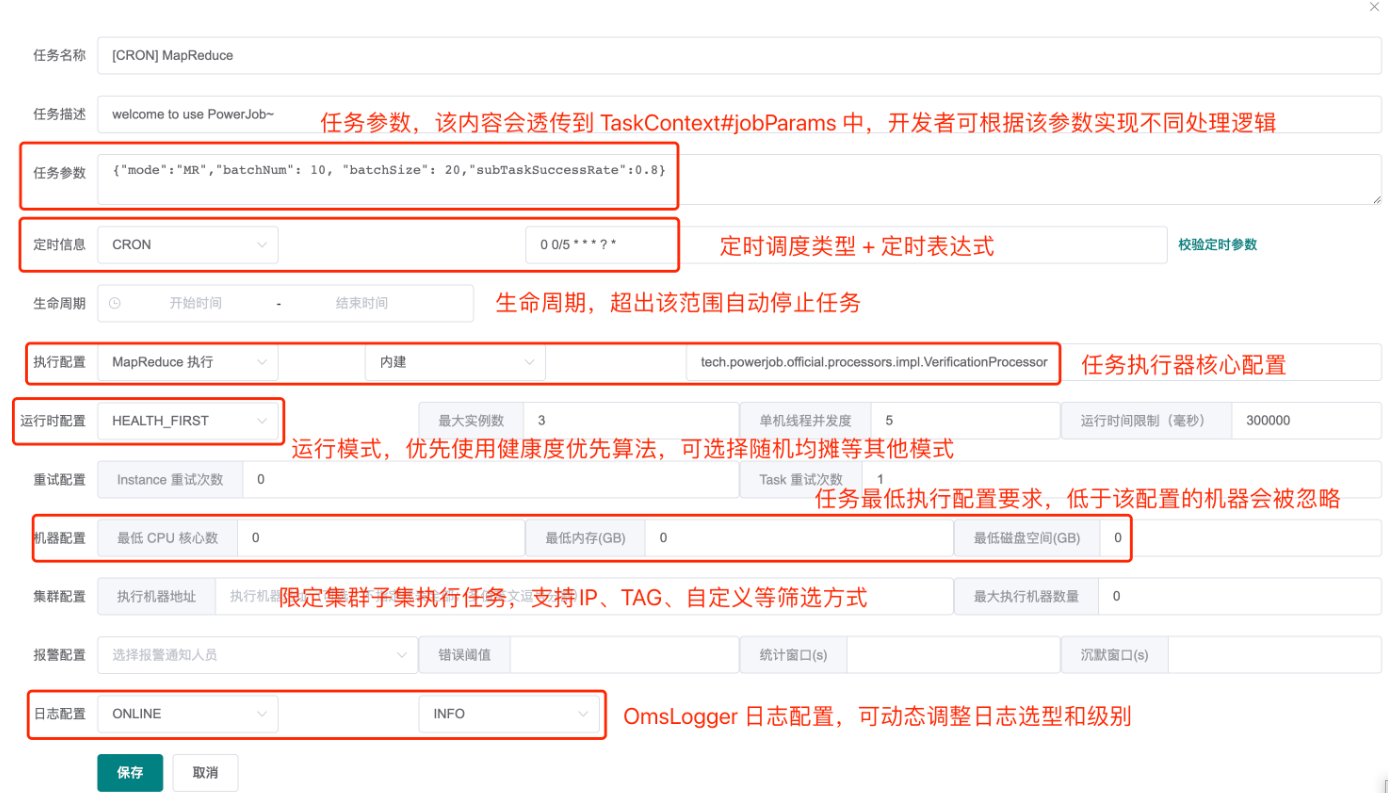
定时信息:
主要选择定时任务类型,支持API, CRON,固定频率、固定延迟、工作流、每日固定间隔等几种定时任务类型。
生命周期:
这是比其他任务框架更便捷的功能,指定了任务的生效周期,如果该任务是预定某时间段内执行的,可以通过该参数配置
执行配置:
- 执行类型支持单机执行、广播执行、Map执行、MapReduce执行
- 单机执行表示只需要有一个节点执行任务即可的场景
- 广播执行表示需要全部节点一同执行的场景,比如清除机器日志、各节点数据统计
- Map与MapReduce执行都是表示分布式、分批执行,用来拆分计算量、耗时较大的任务,区别在于Map执行是一种简单的数据处理逻辑,特点是将输入数据拆分成多个子块,并交给多个分布式节点同时执行,以提高数据处理效率,适用于简单的数据处理场景
- MapReduce执行是一种大数据处理框架,处理逻辑是将复杂的数据处理拆分成Map和Reduce阶段进行处理,通过数据分组计算后合并来提供数据处理效率,更适合复杂的大数据场景
运行时配置:
- 支持
HEALTH_FIRST和RANDOM,即第一个健康节点和随机,用于选择执行处理器节点的策略。 - 最大实例数用于控制处理器节点数量,线程并发度用于控制并发,运行时间限制
更多说明,可在官方文档中查看:
- https://www.yuque.com/powerjob/guidence/ysug7
这篇关于【 PowerJob 的使用 -分布式调度】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





