本文主要是介绍销量?模糊销量?精准销量?如何获取淘宝商品销量数据接口,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

淘宝爬虫商品销量数据采集通常涉及以下几个步骤:
1、确定采集目标:需要明确要采集的商品类别、筛选条件(如天猫、价格区间)、销量和金额等数据。例如,如果您想了解“小鱼零食”的销量和金额,您需要设定好价格区间,并统计前10页搜索结果中所有商品的销量和金额。
2、编写爬虫代码:使用Python等编程语言编写爬虫脚本,通过模拟浏览器请求淘宝页面,获取商品信息。这通常涉及到发送HTTP请求、解析HTML页面、提取所需数据等技术。
3、处理反爬虫机制:淘宝网站有一定的反爬虫机制,因此需要在爬虫代码中加入相应的处理措施,如设置合理的请求间隔、使用代理IP、处理cookies等。
4、数据存储与分析:将爬取到的数据存储到数据库或文件中,以便进行后续的数据分析。数据分析可以包括商品标题的文本分析、销量和销售额的统计分析、价格和销量的分布情况分析等。
5、遵守法律法规:在进行数据采集时,必须遵守相关的法律法规和淘宝的使用条款,确保数据的合法合规使用。
6、注意效率与安全:在采集数据时,应注意不要对淘宝服务器造成过大压力,避免频繁请求导致账号被封禁或IP地址被限制访问。
7、数据可视化:为了更好地理解数据,可以使用图表等形式对数据进行可视化展示,如词云图、柱状图、折线图等。
8、持续更新:市场数据是动态变化的,因此可能需要定期更新采集的数据以保持其时效性。
Taobao.item_get获取商品销量数据接口返回值说明
1.请求方式:HTTP POST GET;复制Taobaoapi2014获取APISDK文件。
2、请求URL:注册调用key请求接入api
3、请求参数:num_iid=652874751412&is_promotion=1
参数说明:num_iid:淘宝商品ID
参数说明:sales:淘宝商品销量
4、请求示例
请求示例 url 默认请求参数已经URL编码处理
curl -i "api-gw.xxx.cn/taobao/item_get_sales/?key=<您自己的apiKey>&secret=<您自己的apiSecret>&num_iid=520813250866"
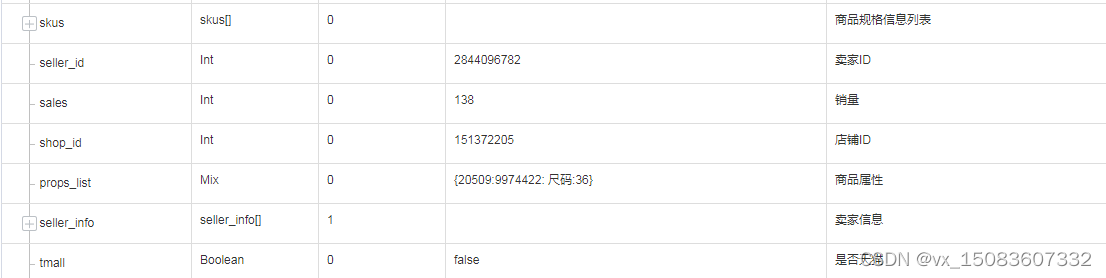
5.返回结果
"seller_id": "2596264565",
"sales": "1",
"shop_id": "127203758",
"props_list": {
"1627207:1347647754": "颜色分类:长方形带开瓶器+送工具刀卡+链子",
"1627207:1347647753": "颜色分类:椭圆形带开瓶器+送工具刀卡+链子",
"1627207:1195392087": "颜色分类:GJ018X钥匙刀+送工具刀卡+链子",
"1627207:1331112595": "颜色分类:超凡大师套餐【送工具卡+链子】",
"1627207:1331112594": "颜色分类:最强王者套餐【送工具卡+链子】",
"1627207:1331264247": "颜色分类:璀璨钻石套餐【送工具卡+链子】"
},
"seller_info": {
"title": "欢乐购客栈",
"shop_name": "欢乐购客栈",
"sid": "127203758",
"zhuy": "//shop127203758.taobao.com",
"level": "12",
"shop_type": "C",
"user_num_id": "2596264565",
"nick": "欢乐购客栈",
"cid": null,
"delivery_score": "4.8 ",
"item_score": "4.8 ",
"score_p": "4.8 "
},
这篇关于销量?模糊销量?精准销量?如何获取淘宝商品销量数据接口的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





