本文主要是介绍GO语言核心30讲 实战与应用 (WaitGroup和Once,context,Pool,Map,字符编码,string包,bytes包),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原站地址:Go语言核心36讲_Golang_Go语言-极客时间
一、sync.WaitGroup和sync.Once
1. sync.WaitGroup 比通道更加适合实现一对多的 goroutine 协作流程。
2. WaitGroup类型有三个指针方法:Wait、Add和Done,以及内部有一个计数器。
(1) Wait方法:阻塞当前的 goroutine,直到计数器归零。
(2) add方法:加减计数器的值。用来记录需要等待的 goroutine 的数量
(3) Done方法:对计数器的值进行减1操作。可以在需要等待的 goroutine 中,通过defer语句调用它。
3. 具体实现代码:
func coordinateWithWaitGroup() {var wg sync.WaitGroup //声明WaitGroup类型,开箱即用wg.Add(2) //设置要等待的goroutine数目,加到计数器里num := int32(0)fmt.Printf("The number: %d [with sync.WaitGroup]\n", num)max := int32(10)go addNum(&num, 3, max, wg.Done) //启用第一个goroutine,结束后调用Done函数对计数器减1go addNum(&num, 4, max, wg.Done) //启用第二个goroutinewg.Wait() //阻塞等待计数器归0
}4. 使用 WaitGroup注意:
(1) 计数器的值不能小于0.虽然是开箱即用,但是必须且尽早地增加其计数器的值。
(2) WaitGroup可以多次使用,但是不能跨周期使用。必须要等这个Wait方法执行结束之后,才能够开始下一个周期。
也就是: wait执行过程中,计数器不能被其他goroutine增加,否则会panic。wait方法和add方法必须放在同一个goroutine 中。
5. sync.Once 类型说明:
(1) 向其输入一个函数参数,然后保证这个函数之后只会被执行一次。
(2) 它的Do方法只接受一个函数参数,且必须是无参数声明和结果声明的函数。
(3) 只执行一次,是针对Once值来说的。所以,有多个只需要执行一次的函数,就应该为它们每一个都分配各自的Once值。
(4) 它内部有一个名叫done的字段,通过原子操作来计数,保证只执行一次。
6. 使用 sync.Once 需要注意的事项:
(1) Do方法只会在参数函数执行结束之后,才把done字段的值变为1。如果并发地调用了Once值的Do方法,会让其中一个发生阻塞。所以:Do方法不能是太耗时的或不会终结的。
(2) 对done字段的赋值1 是在 Once内部用defer语句的方式进行的,不是交给用户操作,所以无论是逻辑错误还是panic都必然赋值1,不能再执行。所以:Do方法不能实现重试机制。
二、context.Context类型
1. Context类型也是一种非常通用的同步工具,它还可以提供一类代表上下文的信息值。
并且这些信息的值是并发安全的,可以被传播给多个 goroutine。
Context还能传达撤销信号。
2. Context类型的值是可以繁衍的,可以通过一个Context值产生出任意个子值。
产生子值时需要输入父值的Context,子值携带父值的数据。
所有的Context值共同构成了代表了上下文全貌的树形结构,树根是一个已经在context包中预定义好的Context值,它是全局唯一的。
3. context包中包含了四个用于产生Context值的函数: (撤销具体意义见下面4)
(1) WithCancel:产生一个可撤销的Context子值,和一个用于触发撤销信号的函数。
(2) WithDeadline:产生会定时撤销的Context子值
(3) WithTimeout:产生会定时撤销的Context子值
(4) WithValue:产生会携带额外数据的Context子值
4. “撤销”一个Context值意味着什么?
Context类型的Done方法会返回一个接收通道,这个接收通道的用途并不是传递元素值,而是让调用方去接收 当前Context值已“撤销”的信号。
一旦Context值被撤销,接收通道就会立即被关闭。对于一个未包含任何元素值的通道来说,它的关闭会使针对它的接收操作结束。
代码示例如下:
func coordinateWithContext() {total := 12var num int32//1. 获得context子值和撤销函数cxt, cancelFunc := context.WithCancel(context.Background()) for i := 1; i <= total; i++ {go addNum(&num, i, func() {if atomic.LoadInt32(&num) == int32(total) {cancelFunc() //2. 全部goroutine运行完毕,执行撤销函数。}})}<-cxt.Done() //3. 撤销函数执行完毕,cxt被撤销,cxt.Done()返回的通道被关闭。//4. 从被关闭的通道做接收操作,代码会解除阻塞,往下执行。fmt.Println("End.")
}5. “撤销”的应用场景还包括: HTTP 请求被终止后的响应,SQL 指令被取消后的处理。
6. 当父值context的撤销函数被调用后,Context值会先关闭它内部的接收通道,然后向它所有子值传达撤销信号。
7. WithValue函数在产生含数据的Context值时,需要三个输入参数,即:父值、键和值。
含数据Context值并不是用字典来存储键和值,只是把键和值简单地存储在自己相应的字段中而已。
8. Context类型的Value方法就是被用来获取数据的。
它先判断给定的键,是否与当前值中存储的键相等,如果相等就把返回;否则就到其父值中继续查找。
如果其父值中仍然未存储相等的键,那么就沿着上下文根节点的方向一路查找下去。
9. Context接口没有提供改变数据的方法。只能通过在上下文树中添加含数据的Context值来存储新的数据,以及通过撤销此种值的父值来丢弃掉不需要的数据。
三、临时对象池sync.Pool
1. sync.Pool类型,被称为临时对象池,临时对象。的意思是:不需要持久使用的某一类值。
2. sync.Pool类型只有两个方法——Put和Get。
Get方法会从当前的池中删除掉一个值,然后把这个值作为结果返回。
如果Get方法没能获得值,就会使用New字段创建一个新值。
New字段的实际值需要我们在初始化临时对象池的时候就给定。
3. 为什么说临时对象池中的值会被及时地清理掉?
(1) sync包有一个私有的全局变量,汇总了所有临时对象池,称为池汇总列表。
(2) 临时对象池的Put方法或Get方法,第一次被调用的时候,这个池就会被添加到池汇总列表中。
(3) GO 执行垃圾回收时,会执行池清理函数。函数通过访问池汇总列表,就能访问到被使用过的临时对象池。
(4) 当临时对象没有被其他代码引用时,就会被清理掉。
4. 临时对象池的数据结构如何?
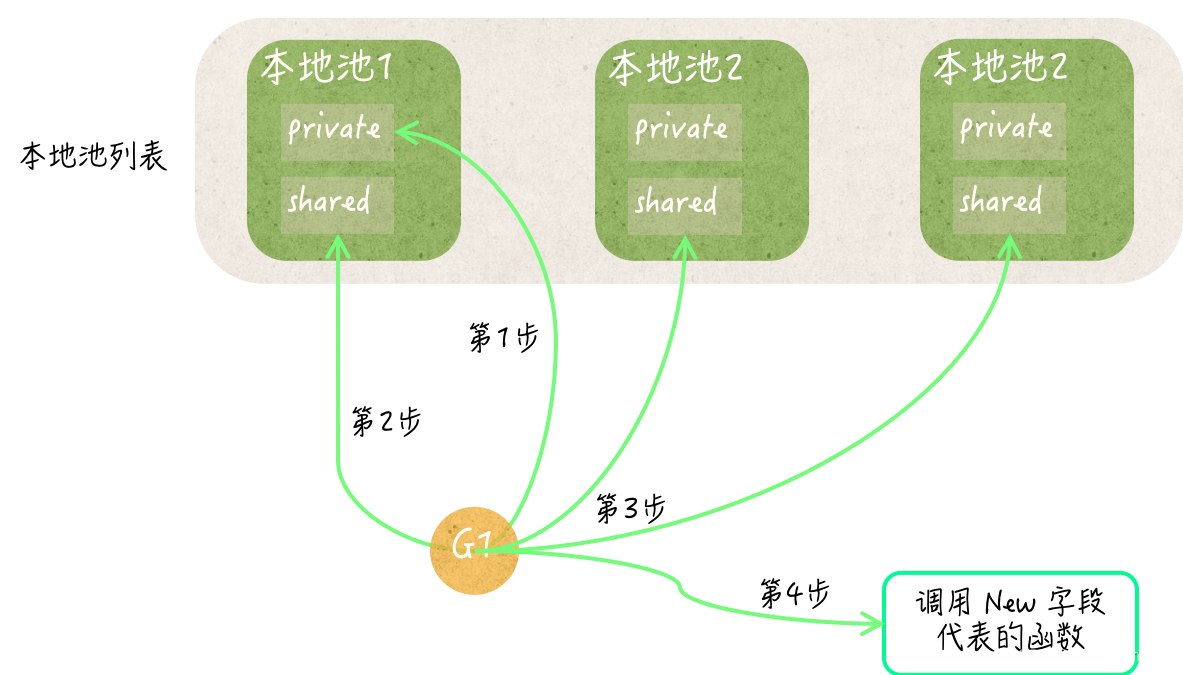
临时对象池是一个多层的数据结构,顶层称为本地池列表,是一个数组。
本地池列表长度与 Go 调度器中的 P 的数量相同,列表每个元素(本地池) 关联一个P。
每个本地池包含三个组建:
(1) 私有临时对象列表:只提供给当前P关联的G访问
(2) 共享临时对象列表:允许其他P关联的G访问
(3) 互斥量 sync.Mutex:被其他P关联的G访问时,这里用于加锁保护。
5. Get方法获取临时对象池的顺序
四、并发安全字典sync.Map
1. sync.Map 与 使用原生map和互斥锁 的方案相比,sync.Map效率更高,因为尽量使用原子操作。
2. 使用原子操作,于是就对 key 有数据类型的要求,不能是函数、字典和切片。
3. sync.Map 的key 类型是键静态类型是interface{},动态类型只有在程序运行时才能够确定。
这就导致键类型有可能不符合要求。所以需要显式地检查键值的实际类型。
4. 可以调用 reflect.TypeOf函数 得到一个键值对应的反射类型值(即:reflect.Type类型的值),然后调用Comparable方法,得到判断结果。
5. 保证并发安全字典中的键和值的类型正确,方案一:
自己重新声明一个结构体类型,把 sync.Map 封装进去,然后声明的方法里写死只接受特定类型的 key 和 value
适用场景: 可以完全确定键和值的具体类型。
缺点:对类型限定得比较死。
6. 保证并发安全字典中的键和值的类型正确,方案二:
在方案一的前提下,使用 interface{} 作为 key 和 value 的类型,然后 用 reflect.TypeOf函数做类型判断。
func (cMap *ConcurrentMap) Load(key interface{}) (value interface{}, ok bool) {if reflect.TypeOf(key) != cMap.keyType {return}return cMap.m.Load(key)
}适用场景: 不能确定键和值的具体类型。
缺点:效率相对低。
7. 并发字典是如何避免使用锁的?
(1) 大致上是让读操作尽量使用原子操作,提高读取速度。
(2) 并发字典内部使用了两个原生的map作为存储介质,一个只读map,一个会被修改的脏map。
两个map的数据有差异,在脏map被修改后就不一致了。
(3)读取数据时,先从只读map里读,并使用原子操作的方式读取数据。
读不到数据时,才从脏map里读数据。
(4) 如果频繁从脏map里读数据,那就把脏map变成只读map。然后在下一次写操作时,把只读map复制,生成新的脏map。
(5) 只读map:键值对可改变,但不能增减键。 删除键时,会被标记,而不会直接删除。
脏map:键值对可改变,可以增减。删除键时,直接删除。会在锁保护状态下进行。
五、unicode与字符编码
1. Go 语言的源码文件必须使用 UTF-8 编码格式进行存储
2. string类型的值被转换为[]rune的时候,字符串会被拆分成 Unicode 字符序列。
string转换会被转成怎样的字符序列,就是字符编码。
3. UTF-8 编码方案,用一个字节表示英文,用三个字节表示中文。
4. string类型的值会由若干个 Unicode 字符组成,每个 Unicode 字符由一个rune类型的值来承载。 : []rune
字符在底层都会被转换为 UTF-8 编码值,UTF-8 编码值又以字节序列形式存储:[]byte

5. 使用 for range语句 遍历字符串的时候注意:
(1) for range语句会把被遍历的字符串值拆成一个字节序列,然后再找出这个字节序列包含的Unicode 字符,然后输出 Unicode 字符 rune。
(2) for range 语句输出的两个迭代变量,第一个是索引值。这个索引值不总是循环+1的,如果遇到unicode字符,会+3
str := "Go爱好者"
for i, c := range str {//%q是输出unicode字符rune,%x是输出字节序列fmt.Printf("%d: %q [% x]\n", i, c, []byte(string(c)))
}输出结果:
0: 'G' [47]
1: 'o' [6f]
2: '爱' [e7 88 b1]
5: '好' [e5 a5 bd]
8: '者' [e8 80 85]六、strings包与字符串操作
1. string值在内部持有一个指针值,这个指针值指向一个字节数组。
string值进行拷贝的话,副本也是指向同一个字节数组。
修改string内容的话,其实是修改了这个指针的指向。创建了新的字节数组,原来的字节数组被丢弃不用。当引用不存在之后,会被系统清除掉。
2. strings包中有两个重要类型:Builder和Reader。 Builder用于构建字符串,Reader用于读取字符串。
3. Builder与string值相比,Builder的优势体现在字符串拼接方面。它不需要像string那样每次修改都创建新的字节数组,它可以在原字节数组基础上进行扩容,减少内存分配和内容拷贝的次数。
4. Builder扩容的逻辑,就和切片扩容一模一样。
5. Reader读取字符串的高效体现在 会保存对已读字节数的计数上。它代表着下一次读取的起始索引位置,可以更加灵活地进行字符串读取。
七、bytes包与字节串操作
1. bytes包和strings包在 API 方面非常的相似,从函数功能上讲,差别微乎其微。区别是:
strings包面向的是 Unicode 字符和经过 UTF-8 编码的字符串。
2. bytes.Buffer类型的用途主要是作为 字节序列的缓冲区。bytes.Buffer是集读、写功能于一身的数据类型。
3. bytes.Buffer的len()方法获取的长度是未读内容的长度,而不是已存内容的总长度。
cap()方法获取的是内部字节切片的容量,只与之前的写操作有关,并会随着内容的写入而不断增长。
4. bytes.Buffer 和 string.Builder都使用已读字节数的计数机制。但区别是这个已读计数不能直接获得。
已读计数非常重要,在读取内容、写入内容、截断内容、读回退、重置内容、导出内容和获取长度时,都需要它。
5. bytes.Buffer 存在 非标准读取的操作问题。比如:
通过 unreadBytes := buffer1.Bytes() 获得未读字节 切片 unreadBytes。
这个unreadBytes 和 buffer1 在共用着底层的一个字节数组。在buffer1内容被添加之后,只要对 unreadBytes 进行切片操作,就能非标准地获得 未读的内容。甚至对切片内容进行修改。
最彻底的避免问题的办法是,在传出切片值时做隔离。比如先做深度拷贝,再把副本传出。
这篇关于GO语言核心30讲 实战与应用 (WaitGroup和Once,context,Pool,Map,字符编码,string包,bytes包)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



