本文主要是介绍【联合索引】最左匹配原则是什么?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是联合索引
联合索引(Composite Index)是一种索引类型,它由多个列组成。
MySQL的联合索引(也称为复合索引)是建立在多个字段上的索引。这种索引类型允许数据库在查询时同时考虑多个列的值,从而提高查询效率和性能。
联合索引:也称复合索引,就是建立在多个字段上的索引。联合索引的数据结构依然是 B+ Tree
例如:当使用(col1, col2, col3)创建一个联合索引时,创建的只是一颗B+ Tree,在这棵树中,会先按照最左的字段col1排序,在col1相同时再按照col2排序,col2相同时再按照col3排序。
联合索引的存储结构
联合索引是一种特殊类型的索引,它包含两个或更多列
在MySQL中,联合索引的数据结构通常是B+Tree,这与单列索引使用的数据结构相同。
当创建联合索引时,需要注意列的顺序,因为这将影响到索引的使用方式。
如下图所示,表的数据如右图,ID 为主键,创建的联合索引为 (a,b),注意联合索引顺序,下图是模拟的联合索引的 B+ Tree 存储结构
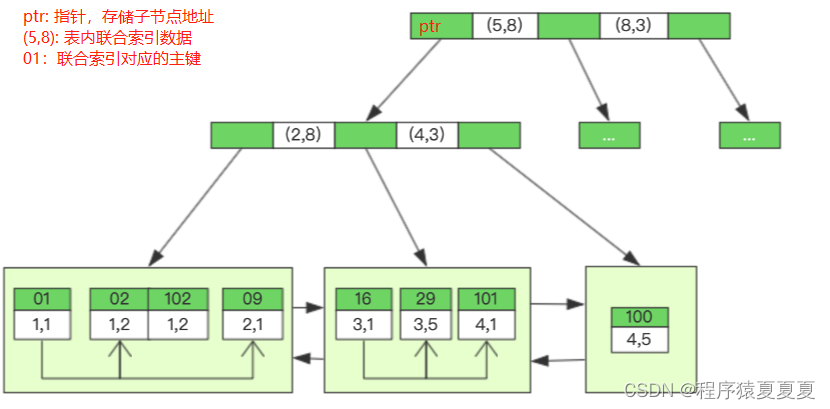
最左匹配原则
联合索引还是一颗B+树,只不过联合索引的健 数量不是一个,而是多个。
构建一颗B+树只能根据一个值来构建,因此数据库依据联合索引最左的字段来构建B+树。
假如创建一个(a,b)的联合索引,联合索引B+ Tree结构如下:
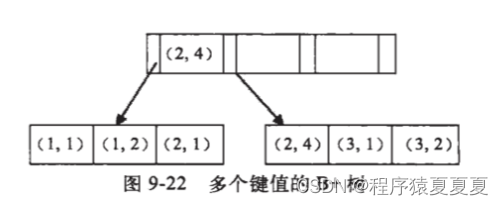
结合上述联合索引B+ Tree结构,可以得出如下结论:
1.a的值是有顺序的,1,1,2,2,3,3,而b的值是没有顺序的1,2,1,4,1,2。
所以b = 2这种查询条件没有办法利用索引,因为联合索引首先是按a排序的,b是无序的。
2.当a值相等的情况下,b值又是按顺序排列的,但是这种顺序是相对的。
所以最左匹配原则遇上范围查询就会停止,剩下的字段都无法使用索引。
例如a = 1 and b = 2 ,a,b字段都可以使用索引,因为在a值确定的情况下b是相对有序的,而a>1and b=2,a字段可以匹配上索引,但b值不可以,因为a的值是一个范围,在这个范围中b是无序的。
最左匹配原则
最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
下面我们以建立联合索引(a,b,c)为例,进行详细说明
1、全值匹配查询时
下述SQL会用到索引,因为where子句中,几个搜索条件顺序调换不影响查询结果,因为MySQL中有查询优化器,会自动优化查询顺序。
select * from table_name where a = '1' and b = '2' and c = '3'
select * from table_name where b = '2' and a = '1' and c = '3'
select * from table_name where c = '3' and b = '2' and a = '1'
2、匹配列前缀
如果a是字符类型,那么前缀匹配用的是索引,后缀和中缀只能全表扫描了
select * from table_name where a like 'As%'; //前缀都是排好序的,走索引查询
select * from table_name where a like '%As'; //全表查询
select * from table_name where a like '%As%'; //全表查询
3、匹配左边的列时
下述SQL,都从最左边开始连续匹配,用到了索引。
select * from table_name where a = '1'
select * from table_name where a = '1' and b = '2'
select * from table_name where a = '1' and b = '2' and c = '3'
下述SQL中,没有从最左边开始,最后查询没有用到索引,用的是全表扫描。
select * from table_name where b = '2'
select * from table_name where c = '3'
select * from table_name where b = '1' and c = '3'
下述SQL中,如果不连续时,只用到了a列的索引,b列和c列都没有用到
select * from table_name where a = '1' and c = '3'
4、匹配范围值
下述SQL,可以对最左边的列进行范围查询
select * from table_name where a > 1 and a < 3
多个列同时进行范围查找时,只有对索引最左边的那个列进行范围查找才用到B+树索引,也就是只有a用到索引。
在1<a<3的范围内b是无序的,不能用索引,找到1<a<3的记录后,只能根据条件 b > 1继续逐条过滤。
select * from table_name where a > 1 and a < 3 and b > 1;
5、精确匹配某一列并范围匹配另外一列
如果左边的列是精确查找的,右边的列可以进行范围查找,如下SQL中,a=1的情况下b是有序的,进行范围查找走的是联合索引
select * from table_name where a = 1 and b > 3;
6、排序
一般情况下,我们只能把记录加载到内存中,再用一些排序算法,比如快速排序,归并排序等在内存中对这些记录进行排序,有时候查询的结果集太大不能在内存中进行排序的话,还可能暂时借助磁盘空间存放中间结果,排序操作完成后再把排好序的结果返回客户端。
Mysql中把这种再内存中或磁盘上进行排序的方式统称为文件排序。文件排序非常慢,但如果order子句用到了索引列,就有可能省去文件排序的步骤
select * from table_name order by a,b,c limit 10;
因为b+树索引本身就是按照上述规则排序的,所以可以直接从索引中提取数据,然后进行回表操作取出该索引中不包含的列就好了,order by的子句后面的顺序也必须按照索引列的顺序给出,比如下SQL,在以下SQL中颠倒顺序,没有用到索引
select * from table_name order by b,c,a limit 10;
以下SQL中会用到部分索引,联合索引左边列为常量,后边的列排序可以用到索引
select * from table_name where a =1 order by b,c limit 10;
跳跃扫描机制
一定要遵循最左匹配原则吗?
最左前缀匹配原则,也就是SQL的查询条件中必须要包含联合索引的第一个字段,这样才能命中联合索引查询,但实际上这条规则也并不是100%遵循的。
因为在MySQL8.x版本中加入了一个新的优化机制,也就是索引跳跃式扫描,这种机制使得咱们即使查询条件中,没有使用联合索引的第一个字段,也依旧可以使用联合索引,看起来就像跳过了联合索引中的第一个字段一样,这也是跳跃扫描的名称由来。
我们来看如下例子,理解一下索引跳跃式扫描如何实现的。
比如此时通过(A、B、C)三个列建立了一个联合索引,此时有如下一条SQL:
SELECT * FROM table_name WHERE B = `xxx` AND C = `xxx`;
按正常情况来看,这条SQL既不符合最左前缀原则,也不具备使用索引覆盖的条件,因此绝对是不会走联合索引查询的。
但这条SQL中都已经使用了联合索引中的两个字段,结果还不能使用索引,这似乎有点亏啊?
因此MySQL8.x推出了跳跃扫描机制,但跳跃扫描并不是真正的“跳过了”第一个字段,而是优化器为你重构了SQL,比如上述这条SQL则会重构成如下情况:
SELECT * FROM `table_name ` WHERE B = `xxx` AND C = `xxx`
UNION ALL
SELECT * FROM `table_name ` WHERE B = `xxx` AND C = `xxx` AND A = "yyy"
......
SELECT * FROM `table_name ` WHERE B = `xxx` AND C = `xxx` AND A = "zzz";
通过MySQL优化器处理后,虽然你没用第一个字段,但优化器给你加上去,今天这个联合索引你就得用,不用也得给我用。
但是跳跃扫描机制也有很多限制,比如多表联查时无法触发、SQL条件中有分组操作也无法触发、SQL中用了DISTINCT去重也无法触发等等,总之有很多限制条件,具体的可以参考《MySQL官网8.0-跳跃扫描》。
可以通过通过如下命令来选择开启或关闭跳跃式扫描机制。
set @@optimizer_switch = ‘skip_scan=off|on’;
这篇关于【联合索引】最左匹配原则是什么?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





