本文主要是介绍开散列哈希桶,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
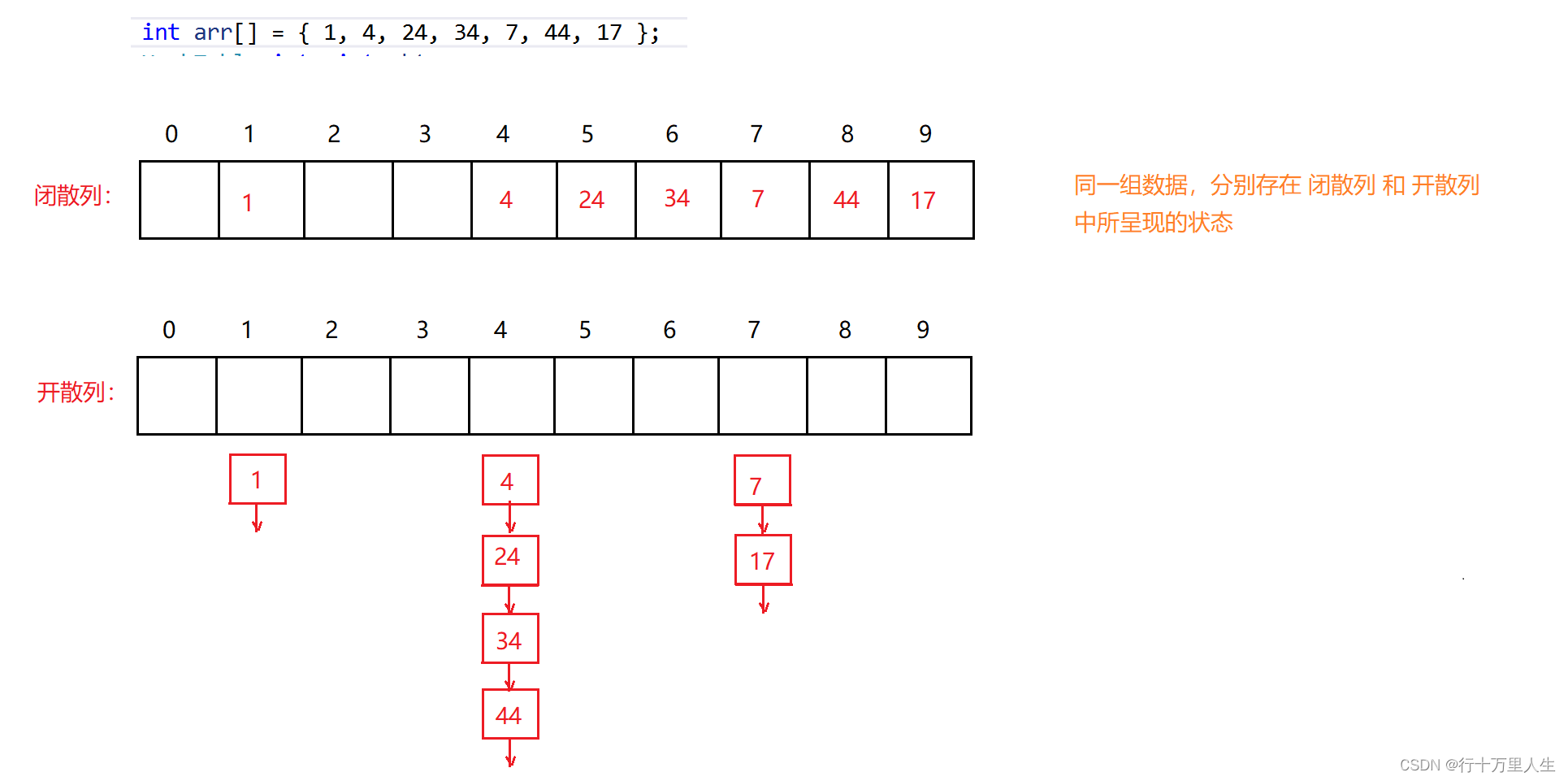
通过上面这幅图,读者应该能较为直观地理解何为开散列,以及闭散列与开散列的区别在哪里 —— 数据的存储形式不同,至于其他的,如确定每个元素的哈希地址等一概相同。
与闭散列相比,开散列能够更好地处理发生冲突的元素 —— 假使我们要在上述闭散列中再插入 5 ,会因为 24 的先插入而导致 5 必须往后寻找空位置,进而影响 6 的插入等。
1. 什么是桶?
通过 HashFunc 计算每个元素的哈希地址,哈希地址相同的元素所组成的子集称为 哈希桶 ,这些元素通过单链表链接在一起。
如:4 % 10 == 24 % 10 == 34 % 10 == 44 % 10 == 4 。
开散列的每个桶中存的都是发生哈希冲突的元素。
2. 开散列框架搭建
- HashFunc
template<class K> struct HashFunc {size_t operator()(const K& key){size_t ret = key;return ret;} };// 为 string 写一个特化版本 template<> struct HashFunc<string> {size_t operator()(const string& s){size_t hash = 0;for (auto& e : s){hash = hash * 131 + e; // 131 是前辈用大量数据测试得到的值,可以尽大程度避免哈希冲突}return hash;} };
- HashNode
template<class K, class V>struct HashNode{HashNode* _next;pair<K, V> _kv;HashNode(const pair<K, V>& kv):_next(nullptr),_kv(kv){}};
- HashTable
template<class K, class V, class Hash = HashFunc<K>>class HashTable{typedef HashNode<K, V> Node;public:HashTable(){_tables.resize(10);}private:vector<Node*> _tables;size_t _n = 0;};
3. Insert()
bool Insert(const pair<K, V>& kv){if (Find(kv.first)) // 未实现的 Find,已存在则返回该元素哈希位置的指针,不存在则返回空return false;Hash hs;// 扩容 if (_n == _tables.size()) // STL 库中,开散列的负载因子设为 1{// ...}// 插入size_t hashi = hs(kv.first) % _tables.size();Node* newNode = new Node(kv);newNode->_next = _tables[hashi];_tables[hashi] = newNode;// 头插++_n;return true;}
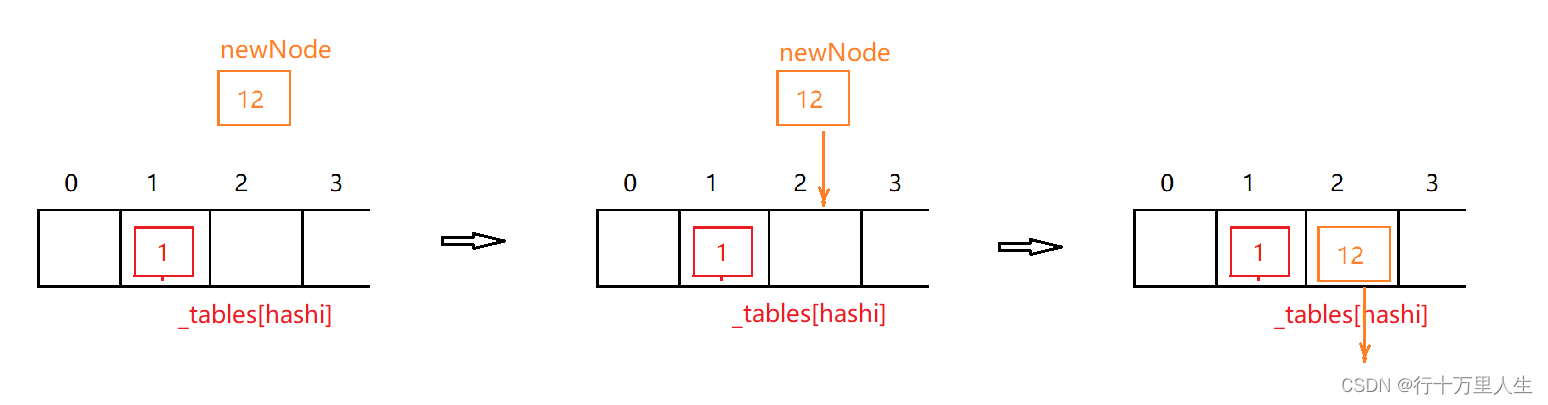
再来聊一聊扩容逻辑。
与闭散列不同,我们不准备复用 Insert() 完成数据的拷贝 —— 假设哈希桶中已经存在 1000, 000 个元素,需要重新拷贝 1000, 000 个元素,再将原表中的元素一一释放。
更好的办法是,直接将原表中的节点 挂到 新表对应的哈希位置上。
// 扩容部分if (_n == _tables.size()){vector<Node*> newTable(2 * _tables.size(), nullptr);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;size_t hashi = hs(cur->_kv.first) % newTable.size();cur->_next = newTable[hashi];newTable[hashi] = cur;cur = next;}_tables[i] = nullptr;// 将原表置空}_tables.swap(newTable);// 不需要手动将 newTable delete[],编译器会自动调用 vector 的析构函数,// 且 swap 后,newTable 里全为空,不需要担心内存泄露的问题}
4. Find() 和 Erase()
- Find()
Node* Find(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){break;}cur = cur->_next;}if (cur && cur->_kv.first == key)return cur;else return nullptr;}
- Erase()
开散列的 Erase() 不能像闭散列那样,Find() 后直接删除。
调用 Find() 能得到 key 对应的 HashData 的指针,但无法得到前一个节点的指针,会造成一系列问题。
bool Erase(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];Node* prev = nullptr; // prev 为前一个节点指针while (cur){if (cur->_kv.fisrt == key) // 找到了{if (prev) // prev 不为空,说明 cur 为中间节点{prev->_next = cur->_next;}else // prev 为空,说明 cur 为 _tables[hashi]{_tables[hashi] = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}
这篇关于开散列哈希桶的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!