本文主要是介绍嵌入式学习第三十四天!(哈希表),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 哈希表:
1. 在记录的存储位置和它的关键字之间建立一种去特定的对应关系,使得每个关键字key对应一个存储位置;在查找时,根据确定的对应关系,找到给定的key的映射。其中记录的存储位置 = f(关键字),我们把这种关系 f 称为哈希函数(散列函数);
2. 采用这种散列技术将记录存储在一块连续的存储空间,这块连续存储开空间称为哈希表或散列表。
3. 存储时,通过散列函数计算出记录的散列地址;查找时,根据同样的散列函数计算记录的散列地址,并按此散列地址访问记录。
2. 哈希冲突/哈希矛盾:
拿到不同数据的关键字,但经过哈希函数的映射,映射到同一地址,称为哈希冲突或哈希矛盾。
解决方式:
1. 重新设计哈希函数,尽可能均匀的散列分布。
2. 开放定址法:通过哈希函数找到地址,判断是否存在数据,如果没有数据存储,直接存储,如果有向下找没有存放数据的地方存储。
3. 链地址法:存储的是链表的地址。
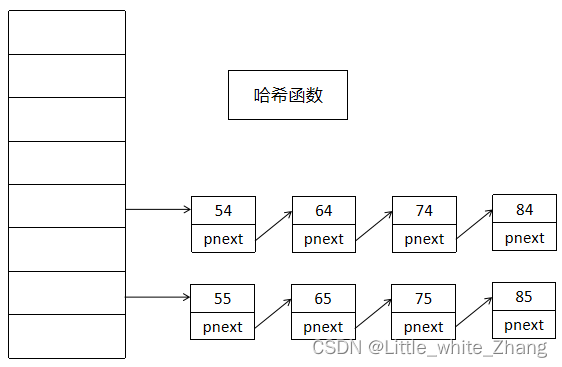
3. 通过哈希表的链地址法实现单词的存储:
1. 哈希表的定义:
#define HASH_SIZE 27typedef struct dict
{char word[64];char mean[1024];
}DATA_TYPE;typedef struct dict_hash_node
{DATA_TYPE data;struct dict_hash_node *pnext;
}HASH_NODE;2. 哈希函数的创建:
HASH_NODE *dictword[HASH_SIZE] = {NULL};int Hash_Condition(char ch)
{if(ch >= 'a' && ch <='z'){return ch - 'a';}else{return HASH_SIZE-1;}
}3. 插入数据到哈希表中:
int Insert_Hash_Node(DATA_TYPE data)
{HASH_NODE *pnode = malloc(sizeof(HASH_NODE));if(pnode == NULL){perror("fail to malloc");return -1;}pnode->data = data;pnode->pnext = NULL;int addr = Hash_Condition(data.word[0]);if(dictword[addr] == NULL){dictword[addr] = pnode;}else{HASH_NODE *ptmp = dictword[addr];while(ptmp->pnext != NULL){ptmp = ptmp->pnext;}ptmp->pnext = pnode;}return 0;
}
4. 遍历哈希表:
void HashTable_For_Each(void)
{for(int i = 0; i < HASH_SIZE; i++){HASH_NODE *pnode = dictword[i];while(pnode != NULL){printf("%s: %s\n", pnode->data.word, pnode->data.mean);pnode = pnode->pnext;}}
}5. 销毁哈希表:
void Destroy_Hash_Table(void)
{HASH_NODE *pfree = NULL;for(int i = 0; i < HASH_SIZE; i++){while(dictword[i] != NULL){pfree = dictword[i];dictword[i] = pfree->pnext;free(pfree);}}return;
}这篇关于嵌入式学习第三十四天!(哈希表)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







