本文主要是介绍Zookeeper简介,架构,单机版搭建,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.Zookeeper简介
Zookeeper-动物园管理者(中文翻译)。好像我们的Hadoop都是一些动物,那这个号称是动物管理员的Zookeeper是什么呢?从字面的意思来看是管理动物的,也就是来管理Hadoop生态圈的,我们看一张图片(来源于网上):
我们可以看到,Hadoop的生态圈里具有这么多的技术工具,那Zookeeper是用来做什么的呢?Zookeeper是一个分布式的,开发源码的分布式应用程序协调服务是Google的Chubby一个开源的实现。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。管理大量主机的协同服务。
2.Zookeeper架构
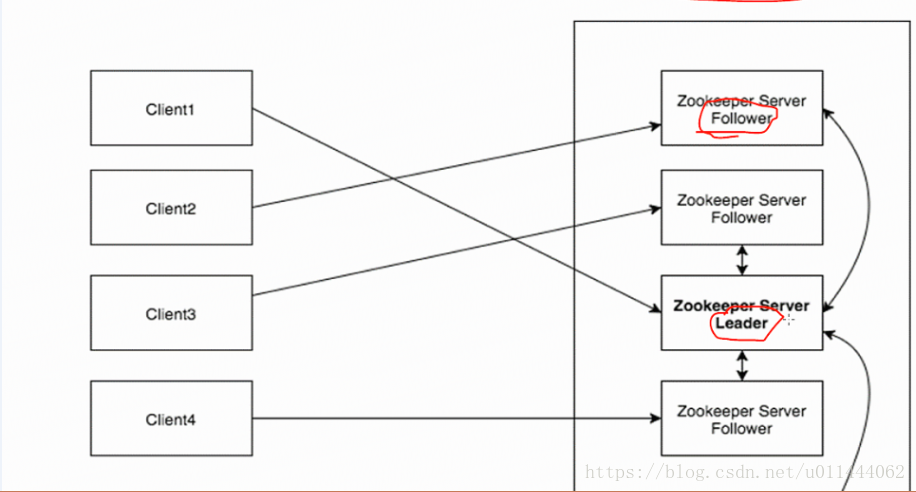
zk(Zookeeper)架构
------------------
1.Client
从server获取信息,周期性发送数据给server,表示自己还活着。
client连接时,server回传ack信息。
如果client没有收到reponse,自动重定向到另一个server.
2.Server(包括Leader和Follwer)
zk集群中的一员,向client提供所有service,回传ack信息给client,表示自己还活着。
3.ensemble
一组服务器(Server)。
zk集群 最小节点数是3.防止zk的leader宕机,不能提供协同服务,zk集群可以允许有(n-1)/2的机器死掉,所以需要3台。
4.Leader
如果连接的节点失败,自定恢复,zk服务启动时,完成leader选举。
5.Follower
追寻leader指令的节点。
zk工作流程
----------------
zk集群启动后,client连接到其中的一个节点,这个节点可以leader,也可以follower。
连通后,node分配一个id给client,发送ack信息给client。
如果客户端没有收到ack,连接到另一个节点。
client周期性发送心跳信息给节点保证连接不会丢失。
如果client读取数据,发送请求给node,node读取自己数据库,返回节点数据给client.
如果client存储数据,将路径和数据发送给server,server转发给leader。
leader再补发请求给所有follower。只有大多数(超过半数)节点成功响应,则
写操作成功。
3.Zookeeper的单机版搭建
zk安装(单机版,s10)
---------------
1.jdk
2.下载zookeeper-3.4.9.tar.gz
3.tar开
4.符号连接环境变量
$>ln -s zookeeper-3.4.9 zk
5.配置zk,复制zoo.cfg.sample-->zoo.cfg
[zk/conf/zoo.conf]
# The number of milliseconds of each tick
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/zpx/zookeeper
clientPort=2181
6.启动zk服务器
$>bin/zkServer.sh start
7.验证zk
$>netstat -anop | grep 2181
8.启动客户端连接到服务器
$>zkCli.sh -server s10:2181 //进入zk命令行
$zk]help //查看帮助
$zk]quit //退出
软件包:
链接:https://pan.baidu.com/s/18f8Cp5nF3fetuYeMRqYcDg 密码:5mbg
这篇关于Zookeeper简介,架构,单机版搭建的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





