本文主要是介绍SeetaFace6人脸活体检测C++代码实现Demo,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SeetaFace6包含人脸识别的基本能力:人脸检测、关键点定位、人脸识别,同时增加了活体检测、质量评估、年龄性别估计,并且顺应实际应用需求,开放口罩检测以及口罩佩戴场景下的人脸识别模型。
官网地址:https://github.com/SeetaFace6Open/index
1. 概述
活体检测是判断人脸图像是来自真人还是来自攻击假体(照片、视频等)的方法。
人脸识别系统存在被伪造攻击的风险。因此需要在人脸识别系统中加入活体检测,验证用户是否为真实活体本人操作,以防止照片、视频、以及三维模型的入侵,从而帮助用户甄别欺诈行为,保障用户的利益。
活体检测分为静默活体检测和配合式活体检测。配合式活体检测即“张张嘴”、“眨眨眼”、“摇摇头”之类;多应用于APP刷脸登录、注册等。静默活体检测是不需要任何动作配合,通过算法和摄像头的配合,进行活体判定;使用起来非常方便,用户在无感的情况下就可以通过检测比对,效率非常高。
《GB∕T 41772-2022 信息技术 生物特征识别 人脸识别系统技术要求》给出了假体攻击类型包括不限于二维假体攻击和三维假体攻击,如下表所示。
| 二维假体攻击 | 二维静态纸张图像攻击 | 样本材质 | 打印纸、亚光相纸、高光相纸、绒面相纸、哑粉纸、铜版纸等 |
| 样本质量 | 分辨率、清晰度、大小、角度、光照条件、完整度等 | ||
| 呈现方式 | 距离、角度、移动、弯曲、折叠等 | ||
| 裁剪方式 | 图像是否扣除眼部、鼻子、嘴巴等 | ||
| 二维静态电子图像攻击 | 设备类型 | 移动终端、微型计算机等 | |
| 设备显示性能 | 分辨率、亮度、对比度等 | ||
| 样本质量 | 分辨率、清晰度、大小、角度、光照条件、完整度等 | ||
| 呈现方式 | 距离、角度、移动等 | ||
| 二维动态图像攻击 | 图像类型 | 录制视频、合成视频等 | |
| 设备类型 | 移动终端、微型计算机等 | ||
| 设备显示性能 | 分辨率、亮度、对比度等 | ||
| 图像质量 | 分辨率、清晰度、帧率等 | ||
| 呈现方式 | 距离、角度、移动等 | ||
| 三维假体攻击 | 三维面具攻击 | 面具材质 | 塑料面具、三维纸张面具、硅胶面具等 |
| 呈现方式 | 距离、角度、移动等 | ||
| 光线条件 | 正常光、强光、弱光、逆光等 | ||
| 裁剪方式 | 面具是否扣除眼部、鼻子、嘴巴等 | ||
| 三维头模攻击 | 头模材质 | 泡沫、树脂、全彩砂岩、石英砂等 | |
| 呈现方式 | 距离、角度、移动等 | ||
| 光线条件 | 正常光、强光、弱光、逆光等 |
2. SeetaFace6活体检测
SeetaFace6的活体检测方案,提供了全局活体检测和局部活体检测 两个方法。
- 全局活体检测就是对图片整体做检测,主要是判断是否出现了活体检测潜在的攻击介质,如手机、平板、照片等等。
- 局部活体检测是对具体人脸的成像细节通过算法分析,区别是一次成像和二次成像,如果是二次成像则认为是出现了攻击。
2.1 基本使用
活体检测识别器可以加载一个局部检测模型或者局部检测模型+全局检测模型。
只加载一个局部检测模型:
#include <seeta/FaceAntiSpoofing.h>
seeta::FaceAntiSpoofing *new_fas() {seeta::ModelSetting setting;setting.append("fas_first.csta");return new seeta::FaceAntiSpoofing(setting);
}或者局部检测模型+全局检测模型,启用全局检测能力:
#include <seeta/FaceAntiSpoofing.h>
seeta::FaceAntiSpoofing *new_fas_v2() {seeta::ModelSetting setting;setting.append("fas_first.csta");setting.append("fas_second.csta");return new seeta::FaceAntiSpoofing(setting);
}调用有两种模式,一个是单帧识别,另外就是视频识别。 其接口声明分别为:
seeta::FaceAntiSpoofing::Status seeta::FaceAntiSpoofing::Predict( const SeetaImageData &image, const SeetaRect &face, const SeetaPointF *points ) const;
seeta::FaceAntiSpoofing::Status seeta::FaceAntiSpoofing::PredictVideo( const SeetaImageData &image, const SeetaRect &face, const SeetaPointF *points ) const;从接口上两者的入参和出参的形式是一样的。出参这里列一下它的声明:
class FaceAntiSpoofing {
public:/* * 活体识别状态 */enum Status{REAL = 0, ///< 真实人脸SPOOF = 1, ///< 攻击人脸(假人脸)FUZZY = 2, ///< 无法判断(人脸成像质量不好)DETECTING = 3, ///< 正在检测};
}单帧识别返回值会是REAL、SPOOF或FUZZY。 视频识别返回值会是REAL、SPOOF、FUZZY或DETECTING。
两种工作模式的区别在于前者属于一帧就是可以返回识别结果,而后者要输入多个视频帧然后返回识别结果。在视频识别输入帧数不满足需求的时候,返回状态就是DETECTING。
这里给出单帧识别调用的示例:
void predict(seeta::FaceAntiSpoofing *fas, const SeetaImageData &image, const SeetaRect &face, const SeetaPointF *points) {auto status = fas->Predict(image, face, points);switch(status) {case seeta::FaceAntiSpoofing::REAL:std::cout << "真实人脸" << std::endl; break;case seeta::FaceAntiSpoofing::SPOOF:std::cout << "攻击人脸" << std::endl; break;case seeta::FaceAntiSpoofing::FUZZY:std::cout << "无法判断" << std::endl; break;case seeta::FaceAntiSpoofing::DETECTING:std::cout << "正在检测" << std::endl; break;}
}这里需要注意face和points必须对应,也就是points必须是face表示的人脸进行关键点定位的结果。points是5个关键点。当然image也是需要识别的原图。
如果是视频识别模式的话,只需要将predict中的fas->Predict(image, face, points)修改为fas->PredictVideo(image, face, points)。
在视频识别模式中,如果该识别结果已经完成,需要开始新的视频的话,需要调用ResetVideo重置识别状态,然后重新输入视频:
void reset_video(seeta::FaceAntiSpoofing *fas) {fas->ResetVideo();
}当了解基本调用接口之后,就可以直接看出来,识别接口直接输入的就是单个人脸位置和关键点。因此,当视频或者图片中存在多张人脸的时候,需要业务决定具体识别哪一个人脸。一般有这几种选择,1. 只做单人识别,当出现两个人的时候识别中止。2. 识别最大的人脸。3. 识别在指定区域中出现的人脸。这几种选择对精度本身影响不大,主要是业务选型和使用体验的区别。
2.2 参数设置
设置视频帧数:
void SetVideoFrameCount( int32_t number );默认为10,当在PredictVideo模式下,输出帧数超过这个number之后,就可以输出识别结果。这个数量相当于多帧识别结果融合的融合的帧数。当输入的帧数超过设定帧数的时候,会采用滑动窗口的方式,返回融合的最近输入的帧融合的识别结果。一般来说,在10以内,帧数越多,结果越稳定,相对性能越好,但是得到结果的延时越高。
设置识别阈值:
void SetThreshold( float clarity, float reality );默认为(0.3, 0.8)。活体识别时,如果清晰度(clarity)低的话,就会直接返回FUZZY。清晰度满足阈值,则判断真实度(reality),超过阈值则认为是真人,低于阈值是攻击。在视频识别模式下,会计算视频帧数内的平均值再跟帧数比较。两个阈值都符合,越高的话,越是严格。
设置全局检测阈值:
void SetBoxThresh(float box_thresh);默认为0.8,这个是攻击介质存在的分数阈值,该阈值越高,表示对攻击介质的要求越严格,一般的疑似就不会认为是攻击介质。这个一般不进行调整。
以上参数设置都存在对应的Getter方法,将方法名称中的Set改为Get就可以访问对应的参数获取了。
2.3 参数调试
在应用过程中往往不可避免对阈值产生疑问,如果要调试对应的识别的阈值,这里我们给出了每一帧分数的获取函数。
下面给出识别之后获取识别具体分数的方法:
void predict_log(seeta::FaceAntiSpoofing *fas, const SeetaImageData &image, const SeetaRect &face, const SeetaPointF *points) {auto status = fas->Predict(image, face, points);float clarity, reality;fas->GetPreFrameScore(&clarity, &reality);std::cout << "clarity = " << clarity << ", reality = " << reality << std::endl;
}在Predict或者PredictVideo之后,调用GetPreFrameScore方法可以获取刚刚输入帧的识别分数。
3. 演示Demo
3.1 开发环境
- Windows 10 Pro x64
- Visual Studio 2015
- Seetaface6
3.2 功能介绍
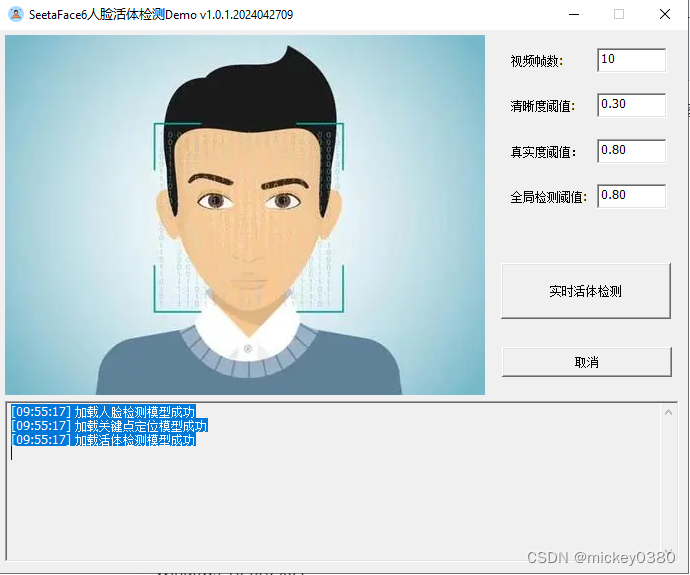
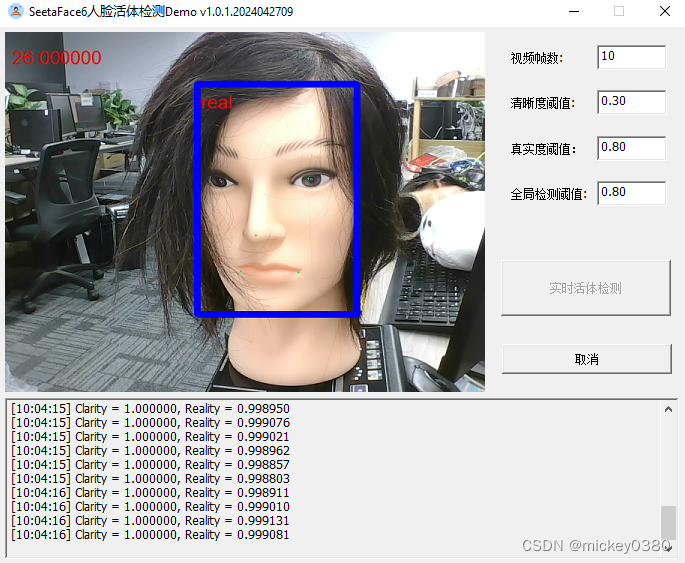
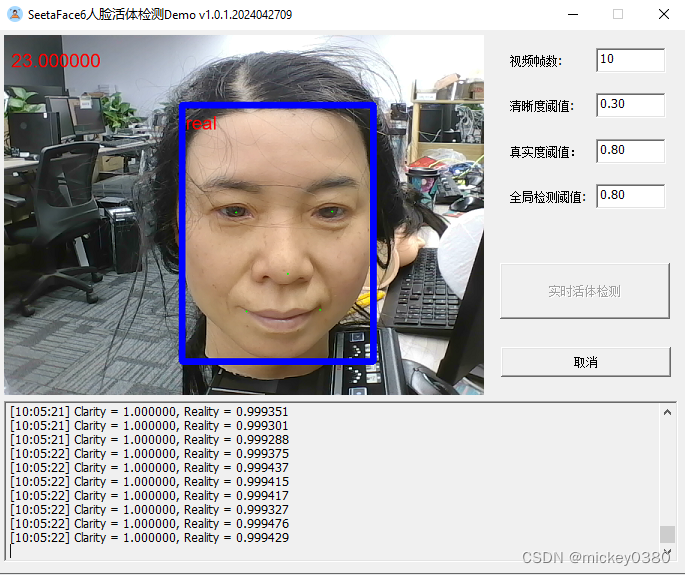
演示程序主界面如下图所示,包括参数显示、实时活体检测、取消等功能。
3.3 效果测试
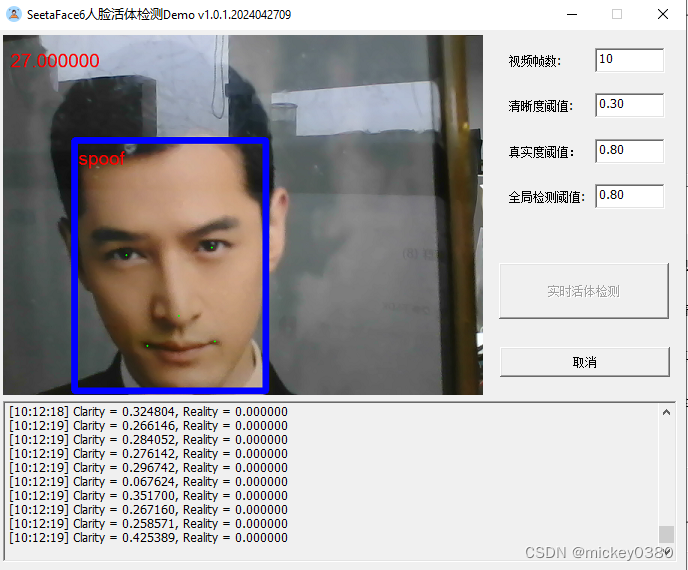
二维假体攻击,包括二维静态纸张图像攻击、二维静态电子图像攻击、二维动态图像攻击,检测效果还是不错。
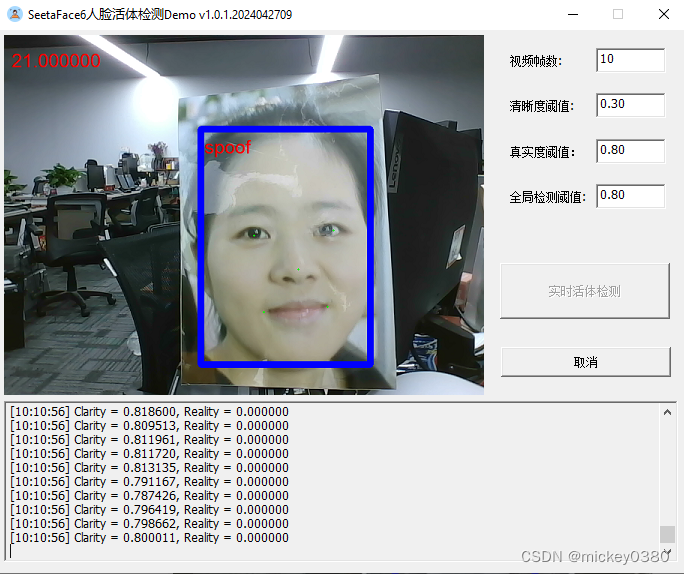
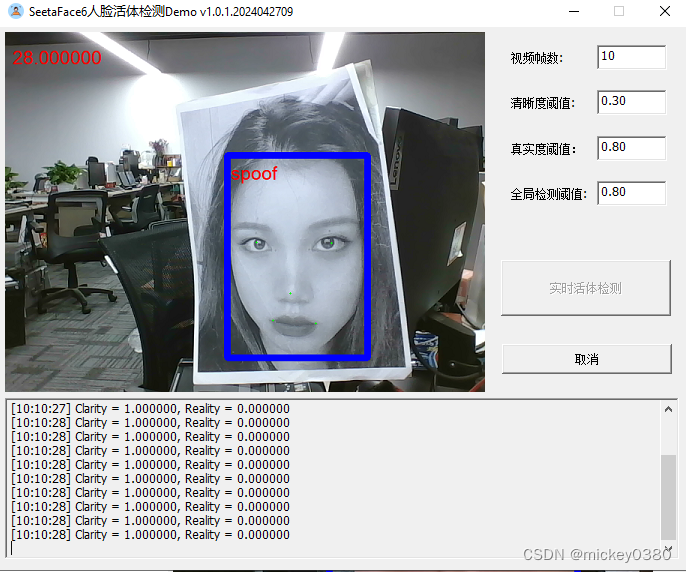
三维假体攻击,除了塑料材质检测效果还可以,其他材质基本无法正确检测。
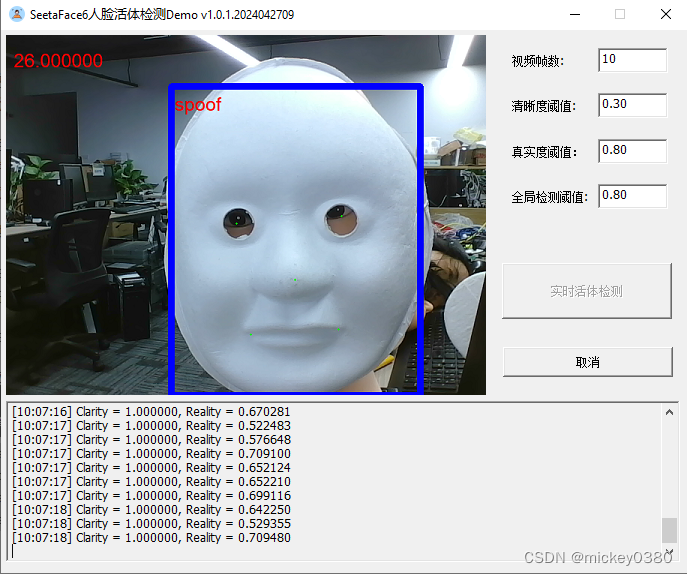
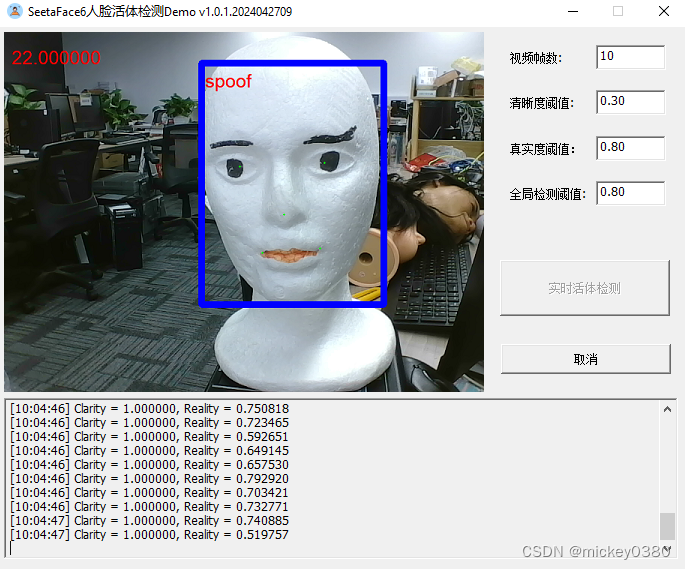
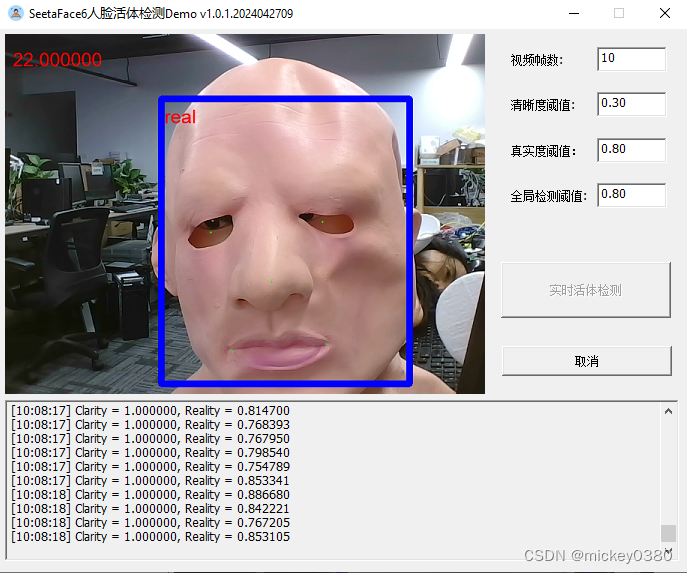
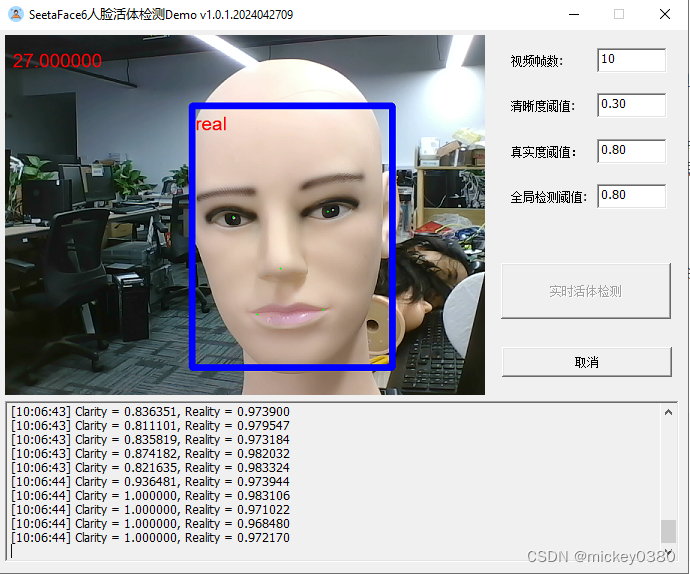
3.4 下载地址
开发环境:
- Windows 10 pro x64
- Visual Studio 2015
- Seetaface6
VS工程下载:SeetaFace6人脸活体检测C++代码实现Demo
这篇关于SeetaFace6人脸活体检测C++代码实现Demo的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






