本文主要是介绍漫步云端之初读Google三大论文(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
GFS(Goole File System):对大数据时代的存储需求进行重新设计的分布式文件系统。
背景:google迅速增长的业务和数据处理需求
设计目标:
- 性能
- 可伸缩性
- 可靠性
- 可用性
以上设计目标与传统的分步式文件系统相同。关键在于不同点。
不同之处:
- 组建失效为常态
- 文件巨大
- 绝大部分文件的修改采用在文件尾部追加数据的方式,而非覆盖。
- 对文件的随机读写几乎不存在,一旦写完,对文件的操作就只有读,按顺序的读取(流式读取)。
设计预期:
- 系统持续监控自身的状态,迅速侦测、冗余、并恢复失效的组件
- 系统存储一定数量的文件,能够有效的管理大文件(也支持小文件,但无需对小文件做专门的优化)
- 系统的工作负载:大规模流式读取,小规模随机读取,大规模、顺序的、数据追加式的写入
- 系统行为必须是高效的、行为定义明确的实现多客户端并追加到同一文件中的语意。“生产者-消费者”队列—使用最小的同步开销实现原子的多路追加数据操作
- 高性能的网络带宽比低延迟重要。对高速、大批量处理数据的需求远大于对单一读写操作的响应要求
系统架构:
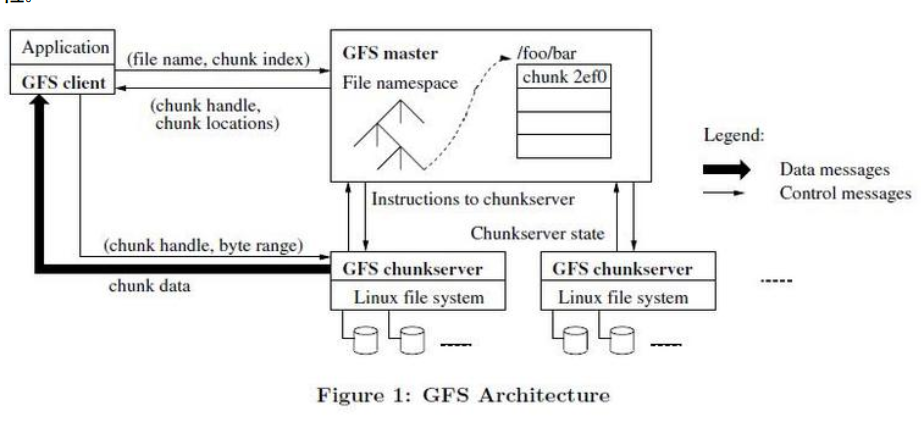
GFS系统集群:由一个单独的Master节点(逻辑上)和多台chunk服务器以及多个客户机组成。Chunk服务器同时被多个客户机访问。
GFS存储文件时,将文件分割成固定大小的chunk,复制各个块到多个块服务器上。
GFS读取文件的流程:
首先,客户端把文件名和程序指定的字节偏移,根据固定的chunk大小,转换成文件的chunk索引,然后将文件名和chunk索引发送给master节点,master节点将相应的chunk标识和副本的位置信息发送给客户端,客户端用文件名和chunk索引作为key缓存这些信息。之后客户端发送请求到其中一个副本处,一般会选择最近的那个。在对chunk的后续读取操作中,客户端不必再与master节点通讯了。
Chunk:
- 创建之时,由master服务器给每个chunk分配一个不变的、全球唯一的64位标识
- 将chunk以linux文件的形式保存于本地硬盘,根据指定的chunk标识和字节范围来读写块数据
Master节点:
- 管理所有文件系统元数据(元数据包括:名字空间、访问控制信息、文件和chunk的映射信息、当前chunk的位置信息等)
- 管理系统范围内的活动,如chunk租约管理,孤儿chunk的回收以及chunk在chunk服务器之间的迁移
- 使用心跳信息周期地和每个chunk服务器通信,发送指令到各个chunk服务器并接收chunk服务器的状态信息
GFS客户端:
GFS客户端代码以库的形式被链接到客户程序中
- 客户端代码实现了GFS文件系统的api接口函数、应用程序与master节点和chunk服务器的通讯、以及对数据进行读写操作
- 客户端与master节点的通讯只获取元数据,所有的数据操作都是客户端直接与chunk服务器交互的
- GFS API的调用无需深入到linux node级别
另外,客户端和chunk服务器皆无需缓存文件数据。由于程序以流的方式读取一个大文件,客户端缓存数据几乎无用(但是客户端会缓存元数据);chunk以本地文件的方式保存,linux的文件系统缓存会把经常访问的数据缓存到内存中。
小结:
google file system 使用普通廉价硬件实现了一个支持大规模数据处理的系统。在设计思路上,与传统的分布式文件系统完全不同,认为组件的失效为常态、采用追加方式写入、然后再读取(通常序列化读取)、对大文件进行优化、放开接口限制来改进整个系统。
GFS通过持续监控,复制关键数据,快速和自动恢复提供灾难冗余。系统的设计保证了在大并发的读写操作时能够提供很高的吞吐量。GFS通过分离控制流和数据流来实现这个目标,master处理控制流,chunk处理数据流和客户端进程。通过选择较大chunk尺寸减小元数据的大小、通过chunk lease将控制权限交给主副本,进而达到将单一master服务器的负担减小到最低的目标,从而避免master成为性能的瓶颈。
这篇关于漫步云端之初读Google三大论文(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
