本文主要是介绍Python 日志模块Loguru基本使用和封装使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【一】介绍
- Loguru是一个用于Python的日志库,它的设计目标是使日志记录变得简单、快速且易于阅读。
(1)Loguru介绍
- 简洁的API:Loguru提供了一个简洁的API,使得在Python项目中使用日志变得更加容易。只需导入loguru模块,然后使用其提供的函数来记录日志。
- 自动格式化:Loguru会自动将日志消息格式化为带有时间戳、日志级别和消息内容的字符串,无需手动处理。这使得在查看日志时可以轻松地识别出每条日志的时间和级别。
- 多种输出方式:Loguru支持将日志输出到控制台、文件、Slack、GitHub等不同的地方。可以根据需要选择合适的输出方式,并设置不同的日志级别以关注重要信息。
- 配置文件支持:Loguru允许使用JSON格式的配置文件来自定义日志记录的行为,轻松地为应用程序添加自定义的日志处理器或过滤器。
- 异常追踪:Loguru可以自动捕获和记录异常信息,并将其与日志消息一起输出,使调试和排查问题更加方便。
- 彩色输出支持:Loguru支持在控制台输出中添加颜色,使日志更易于阅读和区分。
- 装饰器集成:Loguru提供了日志装饰器,可以直接在函数或类上应用,避免在每个可能产生日志的地方插入日志语句。
(2)Loguru与logging的区别和优势
- 简洁性:与logging相比,Loguru的API更加简洁易用。
- 自动化:Loguru提供了许多自动化的功能,如自动格式化、异常追踪和彩色输出等。
- 灵活性:Loguru支持多种输出方式和自定义方式,如控制台、文件、Slack、GitHub等输出目标,以及自定义日志格式、颜色编码、文件记录等。
- 高效性:Loguru使用了异步I/O技术,可以提高日志记录的效率。
【二】使用
(1)简单使用
- 安装
pip install loguru
-
示例
-
from loguru import logger# 添加一个文件输出目标 logger.add('my_file_log.log') # 记录一条日志,它将同时输出到控制台和文件 logger.info('这是一条info级别日志') logger.warning('这是一条warning级别日志') logger.error('这是一条error级别日志') logger.critical('这是一条critical级别日志') logger.debug('这是一条debug级别日志') -
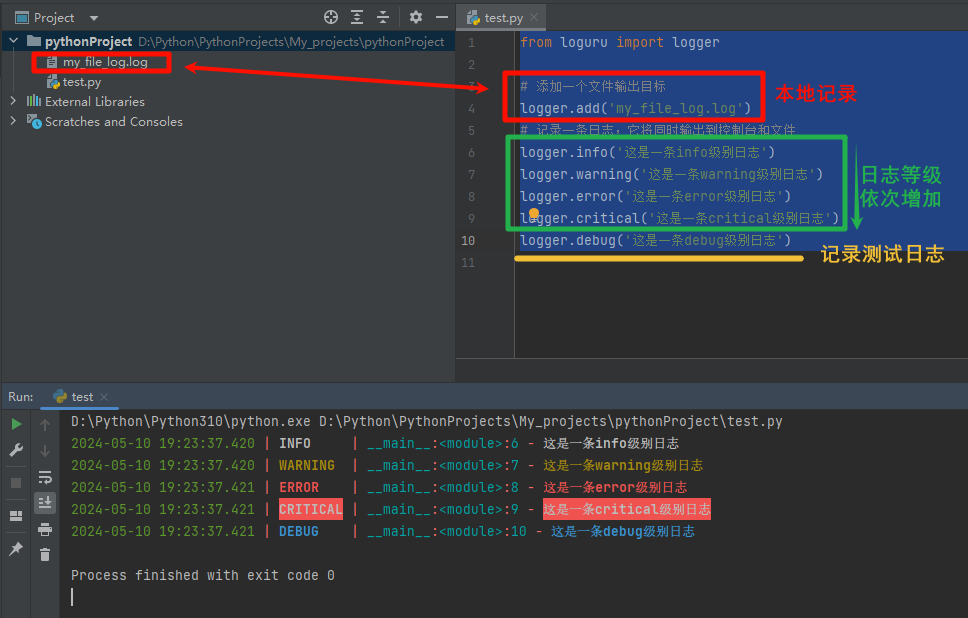
-
-
说明
logger.add()方法添加了一个文件输出目标,指定了日志文件的名称(my_log_file.log)logger对象的不同方法(如info(),warning(),error(),critical(),debug())来记录不同级别的日志消息。- 除了debug,他们的测试等级依次增加
(2)add方法
-
源码
-
class Logger:@overloaddef add(self,sink: Union[TextIO, Writable, Callable[[Message], None], Handler],*,level: Union[str, int] = ...,format: Union[str, FormatFunction] = ...,filter: Optional[Union[str, FilterFunction, FilterDict]] = ...,colorize: Optional[bool] = ...,serialize: bool = ...,backtrace: bool = ...,diagnose: bool = ...,enqueue: bool = ...,context: Optional[Union[str, BaseContext]] = ...,catch: bool = ...
-
-
sink:
-
这是指定日志输出的地方,可以是一个文件名、文件对象、标准输出(例如
sys.stderr或sys.stdout)、一个URL(如向Slack发送消息)等。 -
logger.add("my_file_log.log") # 输出到my_file_log.log文件 logger.add(sys.stdout) # 输出到标准输出
-
-
level:
-
用于指定日志级别。如果指定了级别,则只有该级别及以上的日志才会被输出到该sink。如果不指定,则使用全局级别
-
logger.add("my_file_log.log", level="INFO") # 只记录INFO级别及以上的日志
-
-
format:
-
用于定义日志的格式。这是一个字符串,可以使用各种占位符来自定义输出格式。
-
logger.add("my_file_log.log", format="{time} {level} {message}") -
可填参数
-
占位符 描述 %(asctime)s日志事件发生的时间 %(levelname)s日志级别名称 %(message)s日志消息,传递给 logger方法的字符串%(name)s用于记录日志的logger的名称 %(pathname)s调用日志记录方法的源文件的完整路径名 %(filename)s调用日志记录方法的源文件的文件名。 %(module)s调用日志记录方法的模块名 %(process)d进程ID %(thread)d线程ID(可能不是所有平台都可用) %(threadName)s线程名(可能不是所有平台都可用) %(lineno)d调用日志记录方法的源代码行号 %(funcName)s调用日志记录方法的函数名 %(processName)s进程名 -
import logging logging.basicConfig(format='%(asctime)s - %(name)s - %(levelname)s - %(message)s') logger = logging.getLogger(__name__) logger.info('This is an info message.')
-
-
如何指定时间格式
-
日志内容信息只保留年月日信息,十分秒不要
-
from loguru import logger # 自定义时间格式,仅包含年、月、日 format_string = "{time:YYYY-MM-DD} | {level} | {message}" # 添加一个日志输出配置,指定时间格式 logger.add(sink="my_file_log.log", format=format_string) logger.info("这是一条日志消息")
-
-
日志文件名字带有时间,带有年月日
-
from loguru import logger# 添加一个文件输出目标 logger.add('my_file_log{time:YYYY-MM-DD}.log') # 记录一条日志,它将同时输出到控制台和文件 logger.info('这是一条info级别日志')xxxxxxxxxx from loguru import logger# 添加一个文件输出目标logger.add('my_file_log{time:YYYY-MM-DD}.log')# 记录一条日志,它将同时输出到控制台和文件logger.info('这是一条info级别日志')
-
-
-
-
filter:
-
可选的函数或条件表达式,用于决定是否输出日志。如果提供了
filter,则只有满足该filter条件的日志才会被输出到该sink。 -
def filter_fn(record): # 返回布尔值,记录的级别不是DEBUG就返回Truereturn record["level"].name != "DEBUG" logger.add("my_file_log.log", filter=filter_fn) # 不记录DEBUG级别的日志
-
-
colorize:
-
用于指定是否对日志消息进行颜色编码(布尔值)。默认为True,控制台输出是颜色编码的,但文件输出不是。
-
logger.add("my_file_log.log", colorize=True)
-
-
serialize:
-
默认为False,如果为True,则日志消息会被序列化为JSON格式。这对于非文本输出(如发送到Elasticsearch)很有用。
-
logger.add("my_file_log.log", serialize=True) -
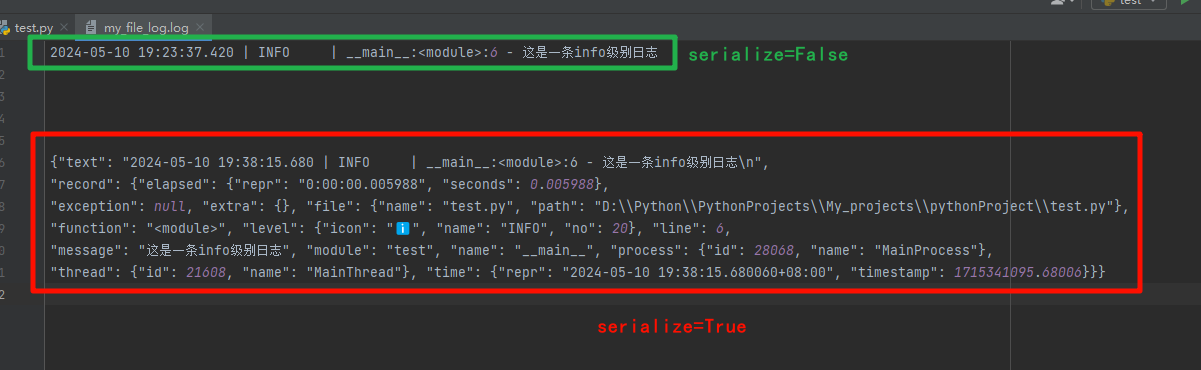
-
-
enqueue:
-
默认为False,如果为True,则日志调用是异步的,并通过内部队列进行处理。这可以提高性能,特别是在高负载下。
-
logger.add("my_file_log.log", enqueue=True)
-
-
rotation:
-
用于文件输出的日志轮转设置。可以基于文件大小(如
"5 MB")或时间间隔(如"1 week")进行轮转。 -
logger.add("my_file_log.log", rotation="1 week") # 每周轮转一次 logger.add("my_file_log.log", rotation="5MB") # 每到5MB就轮转一次
-
-
retention:
-
指定日志文件的保留时长,超过这个时长的日志文件将被自动删除。
-
logger.add("my_file_log.log", retention="10 days") # 保留10天的日志文件
-
-
compression:
-
用于指定日志文件的压缩格式,如
"zip"。 -
logger.add("my_file_log", compression="zip")
-
-
backtrace:
-
默认为False,如果为True,则在记录错误级别的日志时自动添加回溯信息。
-
logger.add("with_backtrace.log", backtrace=True, level="ERROR")
-
(3)装饰器中的应用
-
再装饰器可以使用记录日志功能,这样只使用了该装饰器,那么就可以自动记录日志
-
示例
-
from loguru import logger from functools import wraps import timedef timed_function(func):@wraps(func)def wrapper(*args, **kwargs):start_time = time.time()result = func(*args, **kwargs)end_time = time.time()duration = end_time - start_timelogger.info(f"Function {func.__name__} took {duration:.2f}s to execute.")return resultreturn wrapper@timed_function def add_func(x, y):import timetime.sleep(1)return x + yadd_func(1, 2)
-
【三】封装一个loguru
- 目录结构:一般都是放在一个utils文件夹下
pythonProject # 项目文件-- utils # 工具文件夹-- common_loguru # 自定义loguru工具包-- __init__.py # 初始化文件-- common_loguru.py # 主要逻辑py文件-- settings.py # 配置文件--test.py # 测试文件
_inti_.py文件
from .common_loguru import logger as common_loguru
common_loguru.py文件
import os
from pathlib import Path
from loguru import logger
# import settings
from . import settings
import sysclass LoguruConfigurator:def __init__(self):self._file_set = settings.LOGURU_FILEself._console_set = settings.LOGURU_CONSOLEdef configure(self):# 清除所有现有的日志处理器(如果有的话)logger.remove()# 控制台输出if self._console_set.get('is_show', '').lower() == "on":level = self._console_set.get('level', 'INFO')logger.add(sink=sys.stderr,format="[<green>{time:YYYY-MM-DD HH:mm:ss}</green> {level:<8}| ""<cyan>{module}</cyan>.<cyan>{function}</cyan>:<cyan>{line}</cyan> | ""<level>{message}</level>",level=level,)# 文件保存if self._file_set.get('is_show', '').lower() == "on":log_path = self._file_set.get('path', os.path.join(Path(__file__).parent.parent.parent, 'logs','test{time:YYYY-MM-DD}.log'))level = self._file_set.get('level', 'INFO')rotation = self._file_set.get('rotation', '10MB')retention = self._file_set.get('retention', '7 days')logger.add(log_path,rotation=rotation,retention=retention,compression='zip',encoding="utf-8",enqueue=True,format="[{time:YYYY-MM-DD HH:mm:ss} {level:<6} | {file}:{module}.{function}:{line}] {message}",level=level,)configurator = LoguruConfigurator()
configurator.configure()if __name__ == '__main__':# 测试logger.info('这是一条info级别日志')logger.warning('这是一条warning级别日志')logger.error('这是一条error级别日志')logger.critical('这是一条critical级别日志')logger.debug('这是一条debug级别日志')settings.py文件
import os
from pathlib import PathLOGURU_FILE = {"is_show": "on","level": "INFO",'path': os.path.join(Path(__file__).parent.parent.parent, 'logs', 'test{time:YYYY-MM-DD}.log'),"rotation": "10MB",'retention': "7 days",
}
LOGURU_CONSOLE = {"is_show": "on","level": "INFO",
}
test.py文件
from utils.common_loguru import common_logurucommon_loguru.info('再次测试')这篇关于Python 日志模块Loguru基本使用和封装使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




