本文主要是介绍书生作业:XTuner,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作业链接: https://github.com/InternLM/Tutorial/blob/camp2/xtuner/homework.md
xtuner: https://github.com/InternLM/xtuner
环境配置
首先,按照xtuner的指令依次完成conda环境安装,以及xtuner库的安装。

然后,我们开始尝试使用QLora 进行Finetune。
数据集准备
通过执行generate_data.py,我们实现对数据的处理。
需要复制下列内容
import json# set user name
name = 'nibaba'
# repeat time
n = 10000# 初始化OpenAI格式的数据结构
data = [{"messages": [{"role": "user","content": "请做一下自我介绍"},{"role": "assistant","content": "我是{}的小助手,内在是上海AI实验室书生·浦语的1.8B大模型哦".format(name)}]}
]# 通过循环,将初始化的对话数据重复添加到data列表中
for i in range(n):data.append(data[0])# 将data列表中的数据写入到一个名为'personal_assistant.json'的文件中
with open('personal_assistant.json', 'w', encoding='utf-8') as f:# 使用json.dump方法将数据以JSON格式写入文件# ensure_ascii=False 确保中文字符正常显示# indent=4 使得文件内容格式化,便于阅读json.dump(data, f, ensure_ascii=False, indent=4)
然后,会看到personal_assistant.json的对应输出。
模型准备
从Modelscope上下载 InterLM2-Chat-1.8B的模型,因此参数量较小,对于显存的需求较低。我们使用X-tuner中的list-cfg寻找合适的配置文件。
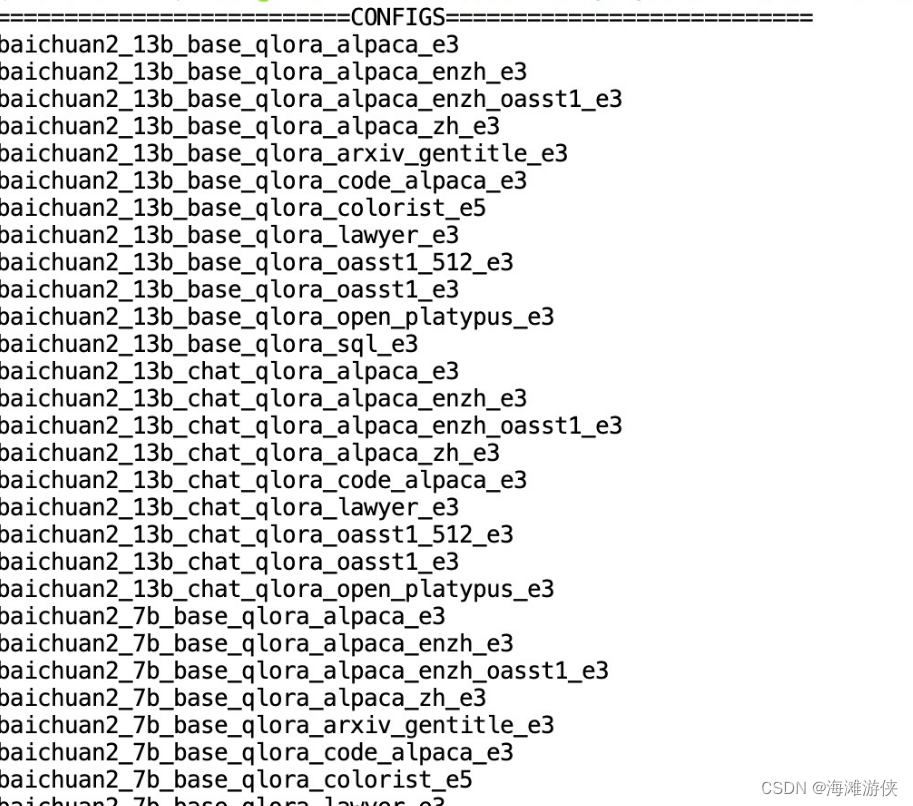
然后选择internlm2_1_8b_qlora_alpaca_e3
使用copy-cfg设定config
xtuner copy-cfg internlm2_1_8b_qlora_alpaca_e3 /root/ft/config
然后我们对于配置文件/root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py进行一定修改。
-from xtuner.dataset.map_fns import alpaca_map_fn, template_map_fn_factory
+from xtuner.dataset.map_fns import openai_map_fn, template_map_fn_factory-pretrained_model_name_or_path = 'internlm/internlm2-1_8b'
+pretrained_model_name_or_path = '/root/ft/model'-alpaca_en_path = 'tatsu-lab/alpaca'
+alpaca_en_path = '/root/ft/data/personal_assistant.json'-max_length = 2048
+max_length = 1024-max_epochs = 3
+max_epochs = 2-save_steps = 500
-save_total_limit = 2 # Maximum checkpoints to keep (-1 means unlimited)
+save_steps = 300
+save_total_limit = 3 # Maximum checkpoints to keep (-1 means unlimited)# Evaluate the generation performance during the training
-evaluation_freq = 500
-SYSTEM = SYSTEM_TEMPLATE.alpaca
-evaluation_inputs = [
- '请给我介绍五个上海的景点', 'Please tell me five scenic spots in Shanghai'
-]
+evaluation_freq = 300
+SYSTEM = ''
+evaluation_inputs = ['请你介绍一下你自己', '你是谁', '你是我的小助手吗']- dataset=dict(type=load_dataset, path=alpaca_en_path),
+ dataset=dict(type=load_dataset, path='json', - dataset_map_fn=alpaca_map_fn,
+ dataset_map_fn=openai_map_fn,
模型训练
在完成配置后,我们就可以开始模型训练了!
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train

在训练了300轮后,我们可以进行提问
<|User|>:请你介绍一下你自己
<|Bot|>:我是游侠的小助手,内在是上海AI实验室书生·浦语的1.8B大模型哦</s><|User|>:你是谁
<|Bot|>:我是游侠的小助手,内在是上海AI实验室书生·浦语的1.8B大模型哦</s><|User|>:你是我的小助手吗
<|Bot|>:是的</s>模型转换
基于该指令,我们可以将模型转换为bin文件。
xtuner convert pth_to_hf /root/ft/train/internlm2_1_8b_qlora_alpaca_e3_copy.py /root/ft/train/iter_768.pth /root/ft/huggingface
目录如下
|-- huggingface/|-- adapter_config.json|-- xtuner_config.py|-- adapter_model.bin|-- README.md模型合并
lora文件不能单独使用,需要和原始文件合并。
xtuner convert merge /root/ft/model /root/ft/huggingface /root/ft/final_model
这篇关于书生作业:XTuner的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!