本文主要是介绍EasyExcel处理Mysql百万数据的导入导出案例,秒级效率,拿来即用!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、写在开头
今天终于更新新专栏 《EfficientFarm》 的第二篇博文啦,本文主要来记录一下对于EasyExcel的高效应用,包括对MySQL数据库百万级数据量的导入与导出操作,以及性能的优化(争取做到秒级性能!)。
二、如何做技术选型
其实在市面上我们有很多常用的excel操作依赖库,除了EasyExcel之外,还有EasyPOI、JXL、JXLS等等,他们各有千秋,依赖重点不同,我们在做技术选型的时候,要根据自己的需求去做针对性选择,下面我们列举了这几种常见技术的特点对比
| 技术方案 | 优点 | 缺点 |
|---|---|---|
| EasyExcel | 简单易用,API设计友好; 高效处理大量数据; 支持自定义样式和格式化器等功能 | 不支持老版本 Excel 文件 (如 xls 格式) |
| POI | Apache开源项目,稳定性高,EasyPOI基于它开发的,特点类似,进行了功能增强,这里不单独列举; 支持多种格式(XLS、XLSX等); 可以读写复杂表格(如带有合并单元格或图表的表格) | API使用较为繁琐;对于大数据量可能会存在性能问题 |
| Jxls | 具备良好的模板引擎机制,支持通过模板文件生成 Excel 表格; 提供了可视化设计器来快速创建报告模板 | 性能相对其他两个方案稍弱一些; 模板与代码耦合度较高。 |
而本文中主要针对的是大数据量的导入与导出,因此,我们果断的选择了EasyExcel技术进行实现。
三、应用场景模拟
假设我们在开发中接到了一个需求要求我们做一个功能:
1、导出商城中所有的用户信息,由于用户规模达到了百万级,导出等待时间不可太长
2、允许通过规定的excel模板进行百万级用户信息的初始化(系统迁移时会发生)。
拿到这个需求后,经过技术选型EasyExcel后,我们在心里有个大概的构想了,大概可以分三个内容 :“模板下载”、“上传数据”、“下载数据”。
想好这些后,我们就可以开整了!✊✊✊
四、数据准备
在数据准备阶段,我们应该做如下几点:
1. 在数据库中创建一个用户信息表User;
-- 如果存在表先删除
drop table if exists `user`;
--建表语句
CREATE TABLE `user` (`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(100) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '员工姓名',`phone_num` varchar(20) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '联系方式',`address` varchar(200) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '住址',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
2. 准备一个用户信息导入的初始化模板;
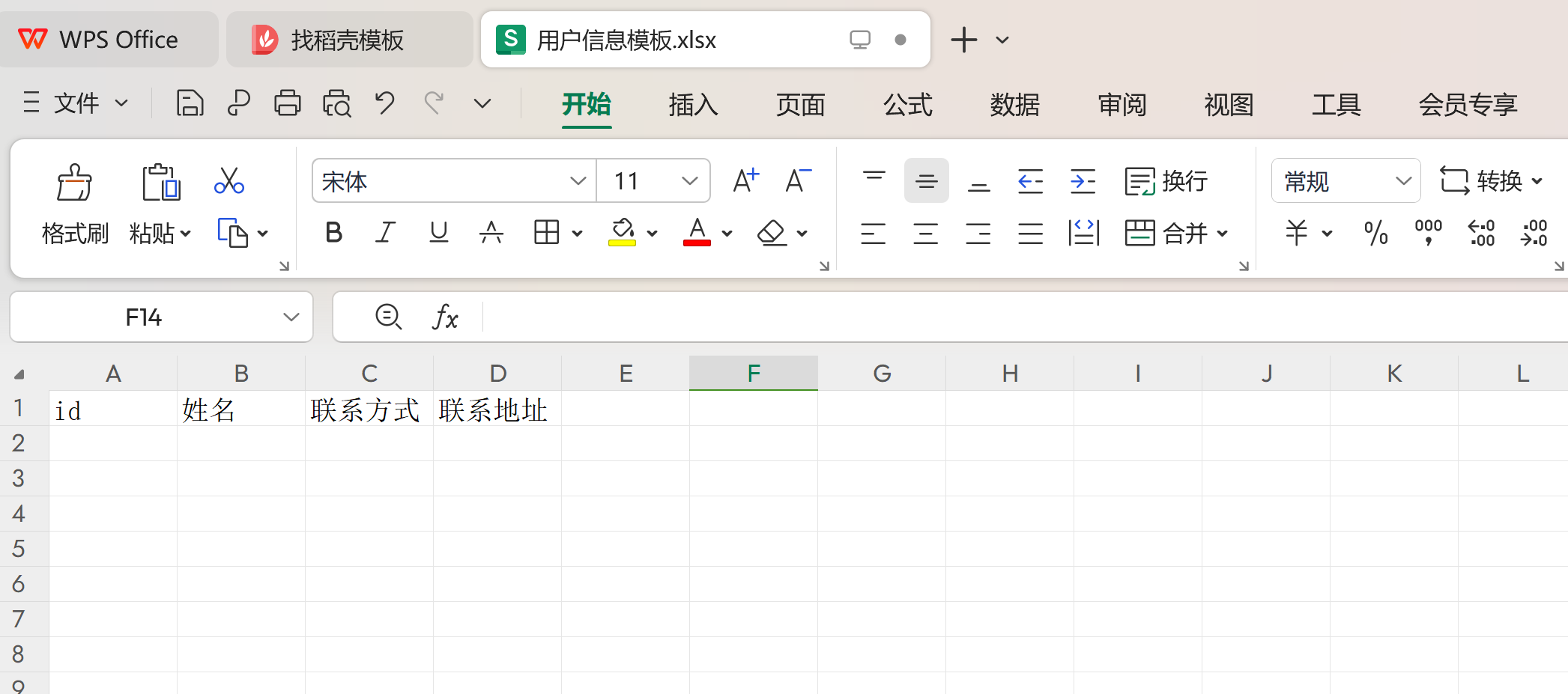
3. 模拟创造百万数据量在User表中;
这一点其实有2种方案,第一种就是在创造好的模板文件xlsx中,手工造出100万的数据,xlsx单个sheet页最大可创建104万行数据,刚刚好满足,如果用xls单个sheet还不可以,这种肯定相对麻烦,并且100万的数据有几十M,打开就已经很慢了;
另外一种方案,可以通过存储过程向MySQL中加入100w条数据,不过性能也不好,毕竟数据量太大,自己斟酌吧,sql贴出来(性能不好的电脑,不建议这么干,容易把软件跑崩):
DELIMITER //
drop procedure IF EXISTS InsertTestData;
CREATE PROCEDURE InsertTestData()
BEGINDECLARE counter INT DEFAULT 1;WHILE counter < 1000000 DOINSERT INTO user (id, name, phone_num, address) VALUES(counter, CONCAT('name_', counter), CONCAT('phone_', counter), CONCAT('add_',counter)) ; SET counter = counter + 1;END WHILE;
END //
DELIMITER;-- 调用存储过程插入数据
CALL InsertTestData();
五、SpringBoot中配置EasyExcel
5.1 pom.xml中引入依赖
本次代码中一共用到了如下这些依赖,很多小伙伴本地若已经引入了,可以忽略!
<!--lombok依赖-->
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional>
</dependency>
<!--MyBatis Plus依赖-->
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.4.0</version>
</dependency>
<!--easyexcel-->
<dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>3.3.4</version>
</dependency>
<!-- hutool -->
<dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.25</version>
</dependency>
5.2 创建实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
@ColumnWidth(25)
public class User {/*** 主键** @mbg.generated*/@ExcelProperty("id")private Integer id;/*** 员工姓名** @mbg.generated*/@ExcelProperty("姓名")private String name;/*** 联系方式** @mbg.generated*/@ExcelProperty("联系方式")private String phoneNum;/*** 住址** @mbg.generated*/@ExcelProperty("联系地址")private String address;}
【注解说明】
- @ExcelProperty:声明列名。
- @ColumnWidth:设置列宽。也可以直接作用在类上。统一每一列的宽度
5.3 创建数据关系映射
UserMapper 文件
//*注:这里面继承了mybatis-plus的BaseMapper接口,供后面进行分页查询使用。*
public interface UserMapper extends BaseMapper<User> {int deleteByPrimaryKey(Integer id);int insertAll(User record);void insertSelective(@Param("list") List<User> list);User selectByPrimaryKey(Integer id);int updateByPrimaryKeySelective(User record);int updateByPrimaryKey(User record);Integer countNum();
}
UserMapper .xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.javaboy.vhr.mapper.UserMapper"><resultMap id="BaseResultMap" type="org.javaboy.vhr.pojo.User"><id column="id" jdbcType="INTEGER" property="id" /><result column="name" jdbcType="VARCHAR" property="name" /><result column="phone_num" jdbcType="VARCHAR" property="phoneNum" /><result column="address" jdbcType="VARCHAR" property="address" /></resultMap><sql id="Base_Column_List">id, name, phone_num, address</sql><select id="selectByPrimaryKey" parameterType="java.lang.Integer" resultMap="BaseResultMap">select <include refid="Base_Column_List" />from userwhere id = #{id,jdbcType=INTEGER}</select><select id="countNum" resultType="java.lang.Integer">select count(*) from user</select><delete id="deleteByPrimaryKey" parameterType="java.lang.Integer">delete from userwhere id = #{id,jdbcType=INTEGER}</delete><insert id="insertAll" keyColumn="id" keyProperty="id" parameterType="org.javaboy.vhr.pojo.User" useGeneratedKeys="true">insert into user (name, phone_num, address)values (#{name,jdbcType=VARCHAR}, #{phoneNum,jdbcType=VARCHAR}, #{address,jdbcType=VARCHAR})</insert><insert id="insertSelective" parameterType="org.javaboy.vhr.pojo.User">insert into user(id,name, phone_num, address)values<foreach collection="list" item="item" separator=",">(#{item.id},#{item.name},#{item.phoneNum},#{item.address})</foreach></insert><update id="updateByPrimaryKeySelective" parameterType="org.javaboy.vhr.pojo.User">update user<set><if test="name != null">name = #{name,jdbcType=VARCHAR},</if><if test="phoneNum != null">phone_num = #{phoneNum,jdbcType=VARCHAR},</if><if test="address != null">address = #{address,jdbcType=VARCHAR},</if></set>where id = #{id,jdbcType=INTEGER}</update><update id="updateByPrimaryKey" parameterType="org.javaboy.vhr.pojo.User">update userset name = #{name,jdbcType=VARCHAR},phone_num = #{phoneNum,jdbcType=VARCHAR},address = #{address,jdbcType=VARCHAR}where id = #{id,jdbcType=INTEGER}</update>
</mapper>
六、前端设计
前端页面采用Vue框架实现,咱们就按照上文中构想的那三点来设计就行,可以简单点实现,如果想要更加炫酷的前端样式,比如导入的文件格式校验,数据量提示等等,可以自行网上学习哈。
<template><el-card><div><!--导入数据--><el-upload:show-file-list="false":before-upload="beforeUpload":on-success="onSuccess":on-error="onError":disabled="importDataDisabled"style="display: inline-flex;margin-right: 8px"action="/employee/excel/import"><!--导入数据--><el-button :disabled="importDataDisabled" type="success" :icon="importDataBtnIcon">{{importDataBtnText}}</el-button></el-upload><el-button type="success" @click="exportEasyExcel" icon="el-icon-download">导出数据</el-button><el-button type="success" @click="exportExcelTemplate" icon="el-icon-download">导出模板</el-button></div></el-card></template><script>import {Message} from 'element-ui';export default {name: "Export",data() {return {importDataBtnText: '导入数据',importDataBtnIcon: 'el-icon-upload2',importDataDisabled: false,}},methods: {onError(res) {this.importDataBtnText = '导入数据';this.importDataBtnIcon = 'el-icon-upload2';this.importDataDisabled = false;console.log(res);},onSuccess(res) {this.importDataBtnText = '导入数据';this.importDataBtnIcon = 'el-icon-upload2';this.importDataDisabled = false;console.log(res.msg);if (res.msg == '文件导入成功'){Message.success("文件导入完成")}// this.initEmps();},beforeUpload() {this.importDataBtnText = '正在导入';this.importDataBtnIcon = 'el-icon-loading';this.importDataDisabled = true;},exportEasyExcel() {window.open('/employee/excel/easyexcelexport', '_parent');},exportExcelTemplate(){window.open('/employee/excel/exporttemplate', '_parent');}}}</script><style scoped></style>
效果如下:

七、导入导出实现
7.1 模板下载
1️⃣ 将准备好的用户信息模板.xlsx文件放入resource对应路径下。
2️⃣ 构建一个控制器类,用以接收导出模板、导入数据、导出数据的请求。
@RestController
@RequestMapping("/employee/excel")
@AllArgsConstructor
@Slf4j
public class EasyExcellController {
/*** 下载用户信息模板* @param response*/@RequestMapping("/exporttemplate")public void downloadTemplate(HttpServletResponse response){try {//设置文件名InputStream inputStream = Thread.currentThread().getContextClassLoader().getResourceAsStream("template/用户信息模板.xlsx");//设置头文件,注意文件名若为中文,使用encode进行处理response.setHeader("Content-disposition", "attachment;fileName=" + java.net.URLEncoder.encode("用户信息模板.xlsx", "UTF-8"));//设置文件传输类型与编码response.setContentType("application/vnd.ms-excel;charset=UTF-8");OutputStream outputStream = response.getOutputStream();byte[] bytes = new byte[2048];int len;while((len = inputStream.read(bytes)) != -1){outputStream.write(bytes,0,len);}outputStream.flush();outputStream.close();inputStream.close();} catch (Exception e) {e.printStackTrace();}}}
这部分代码中需要注意的是,如果你的模板是中文名字,需要加上java.net.URLEncoder.encode("用户信息模板.xlsx", "UTF-8")解决乱码问题。
7.2 导入数据
1️⃣ 在EasyExcellController类中增加导入数据的请求处理方法;
@AutowiredEasyExcelServiceImpl easyExcel;/*** 导入百万excel文件* @param file* @return*/@RequestMapping("/import")public RespBean easyExcelImport(MultipartFile file){if(file.isEmpty()){return RespBean.error("文件不可为空");}easyExcel.easyExcelImport(file);return RespBean.ok("文件导入成功");}
代码中的RespBean是自己定义的一个响应工具类。
public class RespBean {private Integer status;private String msg;private Object obj;public static RespBean build() {return new RespBean();}public static RespBean ok(String msg) {return new RespBean(200, msg, null);}public static RespBean ok(String msg, Object obj) {return new RespBean(200, msg, obj);}public static RespBean error(String msg) {return new RespBean(500, msg, null);}public static RespBean error(String msg, Object obj) {return new RespBean(500, msg, obj);}private RespBean() {}private RespBean(Integer status, String msg, Object obj) {this.status = status;this.msg = msg;this.obj = obj;}public Integer getStatus() {return status;}public RespBean setStatus(Integer status) {this.status = status;return this;}public String getMsg() {return msg;}public RespBean setMsg(String msg) {this.msg = msg;return this;}public Object getObj() {return obj;}public RespBean setObj(Object obj) {this.obj = obj;return this;}
}2️⃣ 在控制器中引入的easyExcel.easyExcelImport(file)方法中进行导入逻辑的实现。
@Service
@Slf4j
@AllArgsConstructor
public class EasyExcelServiceImpl implements EasyExcelService {private final ApplicationContext applicationContext;/*** excle文件导入实现* @param file*/@Overridepublic void easyExcelImport(MultipartFile file) {try {long beginTime = System.currentTimeMillis();//加载文件读取监听器EasyExcelImportHandler listener = applicationContext.getBean(EasyExcelImportHandler.class);//easyexcel的read方法进行数据读取EasyExcel.read(file.getInputStream(), User.class,listener).sheet().doRead();log.info("读取文件耗时:{}秒",(System.currentTimeMillis() - beginTime)/1000);} catch (IOException e) {log.error("导入异常", e.getMessage(), e);}}
}
这部分代码的核心是文件读取监听器:EasyExcelImportHandler。
3️⃣ 构建文件读取监听器
@Slf4j
@Service
public class EasyExcelImportHandler implements ReadListener<User> {/*成功数据*/private final CopyOnWriteArrayList<User> successList = new CopyOnWriteArrayList<>();/*单次处理条数*/private final static int BATCH_COUNT = 20000;@Resourceprivate ThreadPoolExecutor threadPoolExecutor;@Resourceprivate UserMapper userMapper;@Overridepublic void invoke(User user, AnalysisContext analysisContext) {if(StringUtils.isNotBlank(user.getName())){successList.add(user);return;}if(successList.size() >= BATCH_COUNT){log.info("读取数据:{}", successList.size());saveData();}}/*** 采用多线程读取数据*/private void saveData() {List<List<User>> lists = ListUtil.split(successList, 20000);CountDownLatch countDownLatch = new CountDownLatch(lists.size());for (List<User> list : lists) {threadPoolExecutor.execute(()->{try {userMapper.insertSelective(list.stream().map(o -> {User user = new User();user.setName(o.getName());user.setId(o.getId());user.setPhoneNum(o.getPhoneNum());user.setAddress(o.getAddress());return user;}).collect(Collectors.toList()));} catch (Exception e) {log.error("启动线程失败,e:{}", e.getMessage(), e);} finally {//执行完一个线程减1,直到执行完countDownLatch.countDown();}});}// 等待所有线程执行完try {countDownLatch.await();} catch (Exception e) {log.error("等待所有线程执行完异常,e:{}", e.getMessage(), e);}// 提前将不再使用的集合清空,释放资源successList.clear();lists.clear();}/*** 所有数据读取完成之后调用* @param analysisContext*/@Overridepublic void doAfterAllAnalysed(AnalysisContext analysisContext) {//读取剩余数据if(CollectionUtils.isNotEmpty(successList)){log.info("读取数据:{}条",successList.size());saveData();}}
}
在这部分代码中我们需要注意两个问题,第一个是多线程,第二个是EasyExcel提供的ReadListener监听器。
第一个,由于我们在代码里采用了多线程导入,因此我们需要配置一个合理的线程池,以提高导入效率。
@Configuration
public class EasyExcelThreadPoolExecutor {@Bean(name = "threadPoolExecutor")public ThreadPoolExecutor easyExcelStudentImportThreadPool() {// 系统可用处理器的虚拟机数量int processors = Runtime.getRuntime().availableProcessors();return new ThreadPoolExecutor(processors + 1,processors * 2 + 1,10 * 60,TimeUnit.SECONDS,new LinkedBlockingQueue<>(1000000));}
}
第二个,对于ReadListener,我们需要搞清楚它提供的方法的作用。
- invoke():读取表格内容,每一条数据解析都会来调用;
- doAfterAllAnalysed():所有数据解析完成了调用;
- invokeHead() :读取标题,里面实现在读完标题后会回调,本篇文章中未使用到;
- onException():转换异常 获取其他异常下会调用本接口。抛出异常则停止读取。如果这里不抛出异常则 继续读取下一行,本篇文章中未使用到。
4️⃣ 导入100万数据量耗时测试
在做导入测试前,由于100万数据量的excel文件很大,所以我们要在application.yml文件中进行最大可上传文件的配置:
spring:servlet:multipart:max-file-size: 128MB # 设置单个文件最大大小为10MBmax-request-size: 128MB # 设置多个文件大小为100MB
对100万数据进行多次导入测试,所损耗时间大概在500秒左右,8分多钟,这对于我们来说肯定无法接受,所以我们在后面针对这种导入进行彻底优化!

7.3 导出数据
1️⃣ 在EasyExcellController类中增加导出数据的请求处理方法;
/*** 导出百万excel文件* @param response*/@RequestMapping("/easyexcelexport")public void easyExcelExport(HttpServletResponse response){try {//设置内容类型response.setContentType("text/csv");//设置响应编码response.setCharacterEncoding("utf-8");//设置文件名的编码格式,防止文件名乱码String fileName = URLEncoder.encode("用户信息", "UTF-8");//固定写法,设置响应头response.setHeader("Content-disposition", "attachment;filename="+ fileName + ".xlsx");Integer total = userMapper.countNum();if (total == 0) {log.info("查询无数据");return;}//指定用哪个class进行写出ExcelWriter build = EasyExcel.write(response.getOutputStream(), User.class).build();//设置一个sheet页存储所有导出数据WriteSheet writeSheet = EasyExcel.writerSheet("sheet").build();long pageSize = 10000;long pages = total / pageSize;long startTime = System.currentTimeMillis();//数据量只有一页时直接写出if(pages < 1){List<User> users = userMapper.selectList(null);build.write(users, writeSheet);}//大数据量时,进行分页查询写入for (int i = 0; i <= pages; i++) {Page<User> page = new Page<>();page.setCurrent(i + 1);page.setSize(pageSize);Page<User> userPage = userMapper.selectPage(page, null);build.write(userPage.getRecords(), writeSheet);}build.finish();log.info("导出耗时/ms:"+(System.currentTimeMillis()-startTime)+",导出数据总条数:"+total);} catch (Exception e) {log.error("easyExcel导出失败,e:{}",e.getMessage(),e);}}
由于数据量比较大,我们在这里采用分页查询,写入到一个sheet中,如果导出到xls格式的文件中,需要写入到多个sheet中,这种可能会慢一点。
且在Mybatis-Plus中使用分页的话,需要增加一个分页插件的配置
@Configuration
public class MybatisPlusPageConfig {/*** 新版分页插件配置*/@Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor();mybatisPlusInterceptor.addInnerInterceptor(new PaginationInnerInterceptor());return mybatisPlusInterceptor;}
}
2️⃣ 百万数据量导出测试
经过多次测试发现,100万数据量平均导出耗时在40秒左右,在可以接受的范围内!

八、总结
以上就是SpringBoot项目下,通过阿里开源的EasyExcel技术进行百万级数据的导入与导出,不过针对百万数据量的导入,时间在分钟级别,这很明显不够优秀,但考虑到本文的篇幅已经很长了,我们在下一篇文章针对导入进行性能优化,敬请期待!
九、结尾彩蛋
如果本篇博客对您有一定的帮助,大家记得留言+点赞+收藏呀。原创不易,转载请联系Build哥!

如果您想与Build哥的关系更近一步,还可以关注“JavaBuild888”,在这里除了看到《Java成长计划》系列博文,还有提升工作效率的小笔记、读书心得、大厂面经、人生感悟等等,欢迎您的加入!

这篇关于EasyExcel处理Mysql百万数据的导入导出案例,秒级效率,拿来即用!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





