本文主要是介绍蚁群算法及十进制蚁群算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文是在学习完蚁群算法,并且在2014年全国大学生数学建模比赛中应用之后,总结而得。其中引用文献均已标注,第一份matlab代码系引用,第二份matlab代码系原创。
转载请注明出处!
引言
蚁群算法(ant colonyoptimization, ACO),又称蚂蚁算法,是一种用来在图中寻找优化路径的机率型算法。它由Marco Dorigo于1992年在他的博士论文中提出,其灵感来源于蚂蚁在寻找食物过程中发现路径的行为。[1] 蚁群算法采用分布式并行计算的机制,可以较好地跳出局部最优,从而找到全局最优解。广泛应用于求解旅行商问题、货郎担问题等NP完全问题,具有较强的鲁棒性。
算法思想
蚂蚁在寻找食物的过程中,总能找到蚁穴到食物的一条最短路径。而每只蚂蚁并不知道食物的位置,只是在前进的过程中,在自身周围的局部范围内搜索路径,并且以相对较高的概率朝着其他蚂蚁留下的信息素浓度较高的地方移动。蚂蚁在前进的同时会留下一定的信息素,留下的信息素的浓度与该蚂蚁经过的路径长度成反比。路径上总的信息素的浓度与通过的蚂蚁的数量成正比。同时,所有的信息素将按照一定的速率挥发。当大量的蚂蚁同时搜索的时候,在最短路径上的信息素将会越来越浓,按照最短路径移动的蚂蚁也会越来越多,形成一个正反馈,经过反复多次迭代,所有蚂蚁的路径都会收敛到这条最短路径上。
概括一下,蚁群算法的关键点有以下五个:
1. 蚂蚁数量与迭代次数。每轮迭代中,每只蚂蚁都要走遍所有的城市,因此一轮迭代后将生成与蚂蚁数量相等的路径数。更新信息素后进入下一轮迭代。
2. 蚂蚁的移动操作。蚂蚁选择下一个城市的时候,要考虑所有路径上的信息素和城市间的距离,选择概率与前者成正比与后者成反比。综合考虑后使用轮盘赌方法随机选择下一个城市。
文献[2]给出的移动概率的计算公式为:
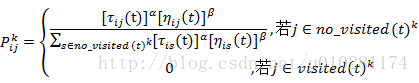
其中,
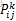
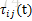
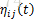
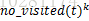
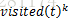
3. 对路径优劣的判断。一次迭代结束后,对所有蚂蚁的路径进行一次评价,根据特定的评判准则(比如TSP问题中的路径最短原则),选取较优(或最优)路径。
4. 信息素的释放。对较优(或最优)路径,认为遍历它们的蚂蚁找到了食物,对这些路径添加新的信息素(由参数控制)。而其余路径不添加信息素。
5. 信息素的更新。每次迭代结束后,除了相应的增添信息素,还要对所有信息素进行衰减(按一定比例)。
文献[2]给出的信息素更新公式为:
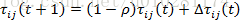
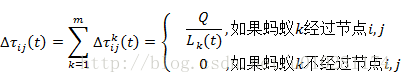
其中,
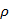
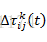
Q表示一只蚂蚁所携带的信息素的强度;
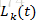
实现步骤
结合下一节的代码,设置变量有:
| 变量 | 取值 | 说明 |
| NC_max | 50 | 最大迭代次数 |
| m | 1000 | 蚂蚁个数 |
| Alpha | 1 | 表征信息素重要程度的参数 |
| Beta | 5 | 表征启发式因子重要程度的参数 |
| Rho | 0.2 | 信息素挥发系数 |
| Q | 0.5 | 信息素增强系数 |
根据上一部分介绍的算法思想,蚁群算法在matlab中的实现步骤如下:
1. 根据已知信息,生成表示各个城市之间的距离的矩阵D,对于无向图,D是一个对称矩阵,有向图则否。
2. 设置每个城市的信息素初始值。
3. 随机(或按照特定规则)释放蚂蚁,按照轮盘赌方法选择每个蚂蚁下一个城市,反复直到所有蚂蚁均完成周游。
4. 评价所有蚂蚁遍历的路径,选择较优者增强信息素。
5. 更新(主要是挥发过程)信息素,存储路径。
6. 检查是否达到最大迭代次数,如果达到则推出,算法结束。否则转到3。
代码
摘自 http://blog.csdn.net/lyp2003ok/article/details/3706247,由解放军信息工程大学的一个老师编写。matlab实现,针对TSP问题的蚁群算法。
主函数:
ACATSP.mfunction [R_best,L_best,L_ave,Shortest_Route,Shortest_Length]=ACATSP(C,NC_max,m,Alpha,Beta,Rho,Q)
%%===========================================================================
% ACATSP.m
% http://blog.csdn.net/lyp2003ok/article/details/3706247
% Ant Colony Algorithm for Traveling Salesman Problem
% ChengAihua,PLA Information Engineering University,ZhengZhou,China
% Email:aihuacheng@gmail.com
% All rights reserved
%---------------------------------------------------------------------------
% 主要符号说明
% C n个城市的坐标,n×2的矩阵
% NC_max 最大迭代次数
% m 蚂蚁个数
% Alpha 表征信息素重要程度的参数
% Beta 表征启发式因子重要程度的参数
% Rho 信息素蒸发系数
% Q 信息素增加强度系数
% R_best 各代最佳路线
% L_best 各代最佳路线的长度
%%===========================================================================%% 第一步:变量初始化
n=size(C,1); %n表示问题的规模(城市个数)
D=zeros(n,n); %D表示完全图的赋权邻接矩阵
for i=1:nfor j=1:nif i~=jD(i,j)=((C(i,1)-C(j,1))^2+(C(i,2)-C(j,2))^2)^0.5;elseD(i,j)=eps; %i=j时不计算,应该为0,但后面的启发因子要取倒数,用eps(浮点相对精度)表示endD(j,i)=D(i,j);end
end
Eta=1./D; %Eta为启发因子,这里设为距离的倒数
Tau=ones(n,n); %Tau为信息素矩阵
Tabu=zeros(m,n); %存储并记录路径的生成
NC=1; %迭代计数器
R_best=zeros(NC_max,n); %各代最佳路线
L_best=inf.*ones(NC_max,1); %各代最佳路线的长度
L_ave=zeros(NC_max,1); %各代路线的平均长度while NC<=NC_max %停止条件之一:达到最大迭代次数%% 第二步:将m只蚂蚁放到n个城市上Randpos=[]; %for i=1:(ceil(m/n))Randpos=[Randpos,randperm(n)];endTabu(:,1)=(Randpos(1,1:m))';%% 第三步:m只蚂蚁按概率函数选择下一座城市,完成各自的周游for j=2:n %所在城市不计算for i=1:mvisited=Tabu(i,1:(j-1)); %已访问的城市J=zeros(1,(n-j+1)); %待访问的城市P=J; %待访问城市的选择概率分布Jc=1; %待访问的城市个数for k=1:nif ~any(visited==k) %判断第k个城市是否已经访问J(Jc)=k;Jc=Jc+1; %访问的城市个数自加1endend%下面计算待选城市的概率分布for k=1:length(J)P(k)=(Tau(visited(end),J(k))^Alpha)*(Eta(visited(end),J(k))^Beta);endP=P/(sum(P));%按 概率原则 选取下一个城市Pcum=cumsum(P); %cumsum,求序列的和序列Select=find(Pcum>=rand); %若计算的概率大于原来的就选择这条路线to_visit=J(Select(1));Tabu(i,j)=to_visit;endendif NC>=2Tabu(1,:)=R_best(NC-1,:);end%% 第四步:记录本次迭代最佳路线L=zeros(m,1); %开始距离为0,m*1的列向量for i=1:mR=Tabu(i,:);for j=1:(n-1)L(i)=L(i)+D(R(j),R(j+1)); %原距离加上第j个城市到第j+1个城市的距离endL(i)=L(i)+D(R(1),R(n)); %一轮下来后走过的距离endL_best(NC)=min(L); %最佳距离取最小pos=find(L==L_best(NC));R_best(NC,:)=Tabu(pos(1),:); %此轮迭代后的最佳路线L_ave(NC)=mean(L); %此轮迭代后的平均距离NC=NC+1%% 第五步:更新信息素Delta_Tau=zeros(n,n); %开始时信息素为n*n的0矩阵for i=1:mfor j=1:(n-1)Delta_Tau(Tabu(i,j),Tabu(i,j+1))=Delta_Tau(Tabu(i,j),Tabu(i,j+1))+Q/L(i); %此次循环在路径(i,j)上的信息素增量endDelta_Tau(Tabu(i,n),Tabu(i,1))=Delta_Tau(Tabu(i,n),Tabu(i,1))+Q/L(i); %此次循环在整个路径上的信息素增量endTau=(1-Rho).*Tau+Delta_Tau; %考虑信息素挥发,更新后的信息素%% 第六步:禁忌表清零Tabu=zeros(m,n);
end%% 第七步:输出结果
Pos=find(L_best==min(L_best)); %找到最佳路径(非0为真)
Shortest_Route=R_best(Pos(1),:) %最大迭代次数后最佳路径
Shortest_Length=L_best(Pos(1)) %最大迭代次数后最短距离
subplot(1,2,1); %绘制第一个子图形
DrawRoute(C,Shortest_Route); %画路线图的子函数
subplot(1,2,2); %绘制第二个子图形
plot(L_best);
hold on; %保持图形
plot(L_ave,'r')
title('平均距离和最短距离'); %标题子函数:
DrawRoute.mfunction DrawRoute(C,R)
%%====================================================================
% DrawRoute.m
% 画路线图的子函数
%--------------------------------------------------------------------
% C Coordinate 节点坐标,由一个N×2的矩阵存储
% R Route 路线
%%====================================================================N=length(R);
scatter(C(:,1),C(:,2));
hold on
plot([C(R(1),1),C(R(N),1)],[C(R(1),2),C(R(N),2)])
hold on
for ii=2:Nplot([C(R(ii-1),1),C(R(ii),1)],[C(R(ii-1),2),C(R(ii),2)])hold on
end若以网上流传的中国31个城市为目标,用下面的语句调用上面的函数:
C=[ 1304 23123639 13154177 22443712 13993488 15353326 15563238 12294196 10044312 7904386 5703007 19702562 17562788 14912381 16761332 6953715 16783918 21794061 23703780 22123676 25784029 28384263 29313429 19083507 23673394 26433439 32012935 32403140 35502545 23572778 28262370 2975 ];
m=31;
Alpha=1;
Beta=5;
Rho=0.1;
NC_max=200;
Q=100;
[R_best,L_best,L_ave,Shortest_Route,Shortest_Length]=ACATSP(C,NC_max,m,Alpha,Beta,Rho,Q);
结果为:
Shortest_Length = 1.5602e+04
绘图:
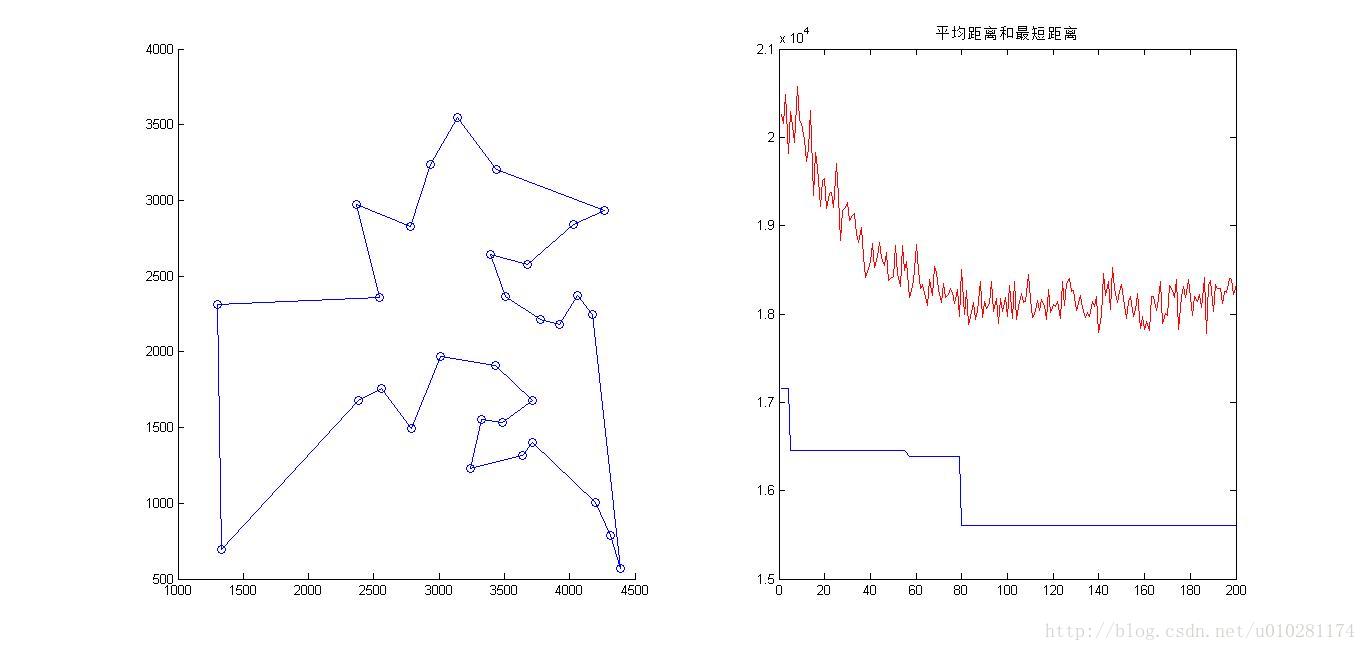
解决连续函数优化问题—十进制蚁群算法[3]
蚁群算法虽然能跳出局部最优找到全局最优解,但是其处理的都是离散问题(城市都是离散的),对于连续问题(比如求一个实数)却无能为力。文献[3]提到的一种十进制蚁群算法,采用特殊的办法构造城市群,可以解决这个问题,以一元连续函数优化为例:
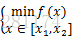
具体方法如下。
构造城市群
首先将待优化的参数归一化,归一到[0,1)上。比如在本例中,令
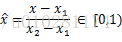
假设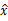
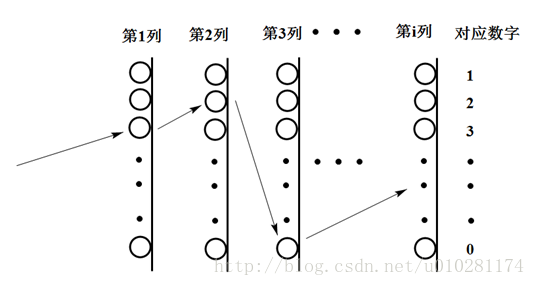
如图,构造10p+1个城市,分成p+1列,第一列一个城市表示起始点,其余每一列的城市分别代表数字1,2,3…9,0。一共有10p个城市,所有的p列放在一起代表精度为p的小数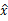
路径转移规则
除了最后一列,每一列的每一个城市都只能前往下一列的10所城市。于是每只蚂蚁遍历完成后,都只经历了除起始城市之外的所有10p个城市中的p个,每列遍历且只遍历一个城市。
最终构造出来的邻接矩阵是一个非对称矩阵(因为城市间移动是单向的),每个点的出度均为10(最后一列除外),入度均为10(起始城市和第一列除外)。且城市间的距离是二值化的,即有连接和没连接。由于城市是虚拟的,本不存在彼此距离之说,所以不妨将有连接的城市的距离设为常数,没连接的设为无穷大。
记第k列第i个城市到第k+1列第j个城市之间的路径的信息素为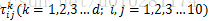
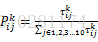
从上式可以看出,两个城市间的信息量越多,蚂蚁转移的概率越大。但由于信息素再大也是基于概率的,所以信息量少的路径扔有可能被选择,即避免了全部蚂蚁陷入局部最优无法跳出的结果。这样就保留了原蚁群算法的优势。
信息素更新规则
信息素的更新需要在原基础上额外满足以下两个条件:
1. 选择的较优的路径上的所有信息素都要加强,且按路径的优劣程度有不同程度的加强。
2. 局部搜索增强策略。考虑到x是连续值,为了增强局部搜索能力,规定若某次迭代中(i,j)在较优路径里,其信息素增强了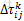
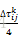
设第N次迭代时第k列第i个城市到第k列第j个城市之间的路径的信息素为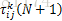
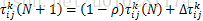
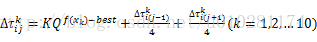
其中,K为权重系数,Q为小于1的正数,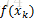
评价标准
对本例来说,最终目的是求出满足min(f(x))的x值,因此相应的评价标准即为min(f(x))。由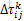
代码
结合上一份解决TSP问题的代码,我写了下面这份解决连续函数优化的代码。写完后简单验证了一下,没有用复杂的函数来试验。不妥之处欢迎指正。
function fx_best=DACA(NC_max,m,Rho,Q,K,f,num,Range,precision)
%% DACA.m
%十进制蚁群算法,用于解决连续函数优化问题,求min(f)
%主要变量定义和符号说明
% f; %目标函数
% num=11; %优化参数的个数
% Range; %优化参数的范围,num行,2列,每行对应一个参数范围
% precision=5;%每个优化参数的精度,精确到小数点后第几位
n=num*precision*10+1;%n表示城市个数,一共产生num个数,每个数有precision位精度,每位精度有10个可能值;第一个城市为起始城市
D=zeros(n,n); %D表示完全图的赋权邻接矩阵
% NC_max=50; %最大迭代次数
% m=1000; %蚂蚁个数
% Rho=0.2; %信息素蒸发系数
% Q=0.5; %信息素增加强度系数,小于1
% K=5; %信息素的权重系数
R_best=zeros(NC_max,floor(n/10+1)); %各代最佳路线
x=0;
fx_best=inf;
fx_ave=zeros(NC_max,1); %各代路线的平均长度%% 第一步:变量初始化
%构造D
D(1,1)=eps;
for i=2:nif i<=11D(1,i)=1;elseD(1,i)=inf;endD(i,1)=inf;
end
for i1=1:numfor i2=1:precisionfor i3=1:10i=(i1-1)*precision*10+(i2-1)*10+i3+1;for j1=1:numfor j2=1:precisionfor j3=1:10j=(j1-1)*precision*10+(j2-1)*10+j3+1;if i==jD(i,j)=eps; %i=j时不计算,应该为0,但后面的启发因子要取倒数,用eps(浮点相对精度)表示elseif i1==j1 && i2==j2-1 || (i1==j1-1 && j2==1 && i2==precision)D(i,j)=1;else D(i,j)=inf;endendendendendendend
end
% Eta=1./D; %Eta为启发因子,这里设为距离的倒数
Tau=5*ones(n,n); %Tau为信息素矩阵
Tabu=zeros(m,floor(n/10+1)); %存储并记录路径的生成
NC=1; %迭代计数器while NC<=NC_max %停止条件之一:达到最大迭代次数%% 第二步:将m只蚂蚁放到初始城市上for i=1:mTabu(i,1)=1;end%% 第三步:m只蚂蚁按概率函数选择下一座城市,完成各自的周游for j=2:n/10+1 %所在城市不计算for i=1:mlast_city=Tabu(i,j-1);P=zeros(1,10);%概率分布next_line=ceil((last_city-1)/10)*10+2;%待访问的城市的第一个,即待访问的城市编号为:J到J+9%下面计算待选城市的概率分布p=0;for k=next_line:next_line+9if D(last_city,k)==1p=p+Tau(last_city,k);endendfor k=next_line:next_line+9if D(last_city,k)==1P(k-next_line+1)=Tau(last_city,k)/p;endend%按 概率原则 选取下一个城市Pcum=cumsum(P); %cumsum,求序列的和序列Select=find(Pcum>=rand); %若计算的概率大于原来的就选择这条路线to_visit=next_line+Select(1)-1;Tabu(i,j)=to_visit;endend%杀死第一只蚂蚁,取而代之的是之前的迭代中最优的蚂蚁if NC>=2Tabu(1,:)=R_best(NC-1,:);end%% 第四步:记录本次迭代最佳路线data=zeros(m,num); %m只蚂蚁,每只蚂蚁对应num个数。data记录各优化参数fx=zeros(m,1); %保存优化函数值pos=0; %保存本次迭代取到最优的位置for i=1:mR=Tabu(i,2:end)-floor((Tabu(i,2:end)-2)./10)*10-2;%R记录各个城市对应的数,0~9for j=1:numsum=0.0;for k=1:precisionsum=sum/10+R((j-1)*precision+k)/10;endsum=sum*(Range(j,2)-Range(j,1))+Range(j,1);data(i,j)=sum;endfx(i,1)=f(data(i)); %求该优化参数对应的优化函数值if fx(i)<=fx_bestx=data(i);fx_best=fx(i);pos=i;endendR_best(NC,:)=Tabu(pos,:); %此轮迭代后的最佳路线fx_ave(NC)=fx(pos);%mean(fx);NC=NC+1%% 第五步:更新信息素Delta_Tau=zeros(n,n); %开始时信息素为n*n的0矩阵for i=1%:size(pos,2) %如果每轮迭代保存前若干优的路径,则要用到这一句for j=1:(n/10-1)Delta_Tau(Tabu(pos(i),j),Tabu(pos(i),j+1))=K*Q^(fx(i)-fx_best); %此次循环在路径(i,j)上的信息素增量if Tabu(pos(i),j+1)-1>0 && D(Tabu(pos(i),j),Tabu(pos(i),j+1)-1)==1Delta_Tau(Tabu(pos(i),j),Tabu(pos(i),j+1)-1)=K*Q^(fx(i)-fx_best)/4;endif Tabu(pos(i),j+1)+1<n && D(Tabu(pos(i),j),Tabu(pos(i),j+1)+1)==1Delta_Tau(Tabu(pos(i),j),Tabu(pos(i),j+1)+1)=K*Q^(fx(i)-fx_best)/4;endendendTau=(1-Rho).*Tau+Delta_Tau; %考虑信息素挥发,更新后的信息素%% 第六步:禁忌表清零Tabu=zeros(m,floor(n/10+1));
end
%% 第七步:输出结果
x
fx_best
figure;
plot(fx_ave,'r')
% hold on; %保持图形
% plot(R_best,'b');
title('平均'); %标题总结
第一次接触十进制蚁群算法在文献[3]中,是用于解决月球着陆轨迹问题的,原文为了求优化目标(函数)的优化变量(另一个函数),采用参数化方法,用蚁群算法生成了十几个优化参数,拟合出优化变量,再对优化目标进行计算、评价,反馈。较为复杂。
文献[3]在蚁群算法方面引用了文献[5]。文献[5]详细介绍了用于连续函数优化的十进制蚁群算法,与本文所讲整体思想一致,但细节上略有不同。值得一提的是,局部搜索增强策略是文献[3]所提,在连续函数优化上不失为一个良策。
参考文献
[1]百度百科http://baike.baidu.com/view/539346.htm?fr=aladdin
[2]杜利峰,牛永洁. 蚁群算法在MATLAB中的实现[J]. 信息技术,2011,06:115-118.
[3]段佳佳,徐世杰,朱建丰. 基于蚁群算法的月球软着陆轨迹优化[J]. 宇航学报,2008,02:476-481+488.
[4]蚁群算法代码http://blog.csdn.net/lyp2003ok/article/details/3706247
[5]陈烨. 用于连续函数优化的蚁群算法[J].四川大学学报(工程科学版),2004,06:117-120.
这篇关于蚁群算法及十进制蚁群算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







