本文主要是介绍Python 全栈系列242 踩坑记录:租用算力机完成任务,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明
记一次用算力机分布式完成任务的坑。
内容
1 背景
很早的时候,做了一个实体识别模型。这个模型可以识别常见的PER、ORG、LOC和TIME几种类型实体。
后来,因为主要只用来做PER、ORG的识别,于是我根据业务数据,重新训练了模型。
再后来,因为在输入和输出端存在问题,于是我做了函数链的封装。输入的问题例如:字符串存在非utf8字符,输出的问题例如主体识别会多一个字,或者过短的实体。总之,函数链封装之后,看起来是一个整体。能适应当时业务的问题。
然后,因为业务上的需求,需要最快速度处理完900万篇文档。
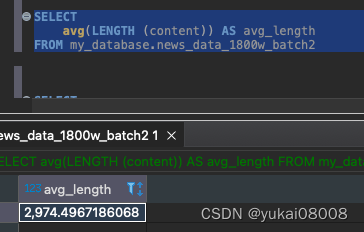
顺带的,我把数据存了clickhouse,计算平均长度是3k。
2 过程
2.1 nginx反向代理
一开始采用在本地部署nginx反向代理,然后租用算力机启动多个服务来进行分摊。这样只要填写租用算力机的IP:端口就可以横向拓展算力了。
实操时,一方面要不断修改nginx的配置,重启,会浪费很多手工。另外发现,由于租用机的网络会有抖动(总体来说带宽大,但不稳),而当前设计每次处理耗时较长,一旦出错时间就全部浪费了。
2.2 租用机本地服务+任务
租用了算力机,然后把本地文件同步过去。然后在租用的机器上启动3个服务,然后通过脚本均匀分配任务执行。最后将结果回传,写入。
过程中的第一个坑是文件传送。文件整体大小是25G, 按UCS的方式切分数据,只有一个block(0.0.0), 其下有874个brick。在规划上,是启动3台机器,每台机器3个服务,共9条线进行处理。在拷贝时本来是可以通过命令只传送每台机器对应的数据的,但是一时间没有调好命令。时间又比较急,所以用了笨办法,将25G传到每台机器。然后就花了很多手工时间,也花了1个多小时传送数据。
# 命令语句例子
123rsync -rvltz -e 'ssh -p 46717' --progress /home/data4T/news_data_1800w_batch2/left root@s9vyc6vwjag1.com:/root/andy/回传结果rsync -rvltz -e 'ssh -p 46717' --progress root@s9vyc6vwjag1.com:/root/andy/right/ /home/data4T/news_data_1800w_batch2/right/
第二个坑就是启动服务,修改服务文件,然后写worker, player这种方式去手动的规划任务了。一方面真的浪费很多手工时间,另一方面也浪费了很多处理时间。原来的设计就是server模式的,这种方式更适合应对持续性的需求,这次任务属于一次性的,其实应该采取worker模式。从显存上看,server模式会一直维持显存,且可能不断增大,所以只能开3个进程。如果是worker模式,那么资源随用随放,我认为开5个worker都没有问题,所以模式的选择错误,又浪费了计算时间。
2.3 其他
还有一些坑。
原来的服务把出具处理和实体识别包在一起了,极大降低了显卡资源利用率。以后应当把资源耗用集中度也作为耦合设计的一个原则(原来只是考虑逻辑复杂性)。
使用文件的方式不可取。一方面是涉及到的手工操作太多,各种文件同步命令,非常浪费时间。最近正好部署了clickhouse,非常适合用于大文件的存取,这也对应了UCS设计中的brick操作,设计可以落地了。
使用数据库,可以规范数据格式。本次在读取pkl文件的时候碰到:ModuleNotFoundError: No module named 'pandas.core.indexes.numeric'错误。大概是因为租用机的pandas、pickle版本的问题。所以后来不得不在本地进行数据的集成,又浪费了很多手工操作。
最后在准备收集数据批量提交时,我稍微修改了一下模式:没有再回收文件到本地,而是存到了clickhouse。然后再按照brick从clickhouse中读取,分块存到postgres。
在存储数据的时候,我倒是又想到了一个问题,就是重复主键。如何避免主键的重复插入?
一种通用的方式是批量的使用主键查询,然后只插入差集。(这些在WMongo都实现了,只是新的库还需要重新适配开发一下)
本次的解决方案是用meta记录brick,按照brick进行批量的增删。
总结
如果再来一次,我会把文件传到一个算力机,然后建一个clickhouse,数据全部写进去。然后将任务写到队列中,按照brick作为基本单位。然后租用更多的算力机,每个算力机上启动n个worker。worker工作时到队列中获取brick,然后根据brick从clickhouse中取数。处理完成后,数据写到结果表。写表前根据brick判断,是否可以插入。
这样的话,估计手工的时间只需要2个小时,整体跑数时间应该短于6小时。
其他:
- 1 可能会因为连接不稳,而导致处理中断。–不合适把租用机作为稳定的后端服务业源
- 2 不要只考虑server模式,也要考虑worker模式。 e.g. streamlit --> 前端, tornado --> api, clickhouse,rabbitmq --> worker
- 3 大量传输数据还是很费时的,传输25个G可能会要1个小时
- 4 耦合设计:资源集中度、逻辑复杂性
- 5 使用数据库,非常节约手工操作的时间
- 6 使用clickhouse的整体感觉还不错
- 7 不要小气,在执行任务的时候不妨再租一个算力机做中转(带宽大)
- 8 可能需要使用anaconda搭建虚拟环境(不是所有算力机都允许启动镜像)
这篇关于Python 全栈系列242 踩坑记录:租用算力机完成任务的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







