本文主要是介绍分布式与一致性协议之Quorum NWR算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Quorum NWR算法
概述
不知道你在工作中有没有遇到过这样的事情:你开发实现了一套AP型分布式系统,实现了最终一致性,且业务接入后运行正常,一切看起来都那么美好。
可是突然有同事说,我们要拉这几个业务的数据做实时分析,希望数据写入成功后,就能立即读取到新数据,也就是要实现强一致性(Werner Vogels提出的客户端侧一致性模型,不是指线性一致性),即数据更改后,要保证用户能立即查询到,这时你该怎么办呢?首先你要明确最终一致性和强一致性有什么区别.
- 1.强一致性能保证写操作完成后,任何后续访问都能读到更新后的值。
- 2.最终一致性只能保证如果对某个对象没有新的写操作了,最终所有后续访问都能读到相同的最近更新的值。也就是说,写操作完成后,后续访问可能会读到旧数据。
其实,为了一个临时的需求而重新开发一套系统或者迁移数据到新系统肯定是不合适的。因为工作量比较大,而且耗时也长,所以建议通过Quorum NWR算法解决这个问题。
通过Quorum NWR算法,我们可以自定义一致性级别,通过临时调整写入或者查询的方式满足新需求,当W+R>N时,就可以实现强一致性了。也就是说,在原有系统上开发并实现一个新功能,即可满足业务同事的需求。
其实,在AP型分布式系统中(如Dynamo、Cassandra、InfluxDB企业版的DATA节点集群),Quorum NWR算法时通常都会实现的一个功能,很常用。掌握了Quorum NWR算法,不仅可以掌握一种常用的、实现一致性的方法,而且可以在后续的实际场景中根据业务的特点,灵活地指定一致性级别。
Quorum NWR的三要素
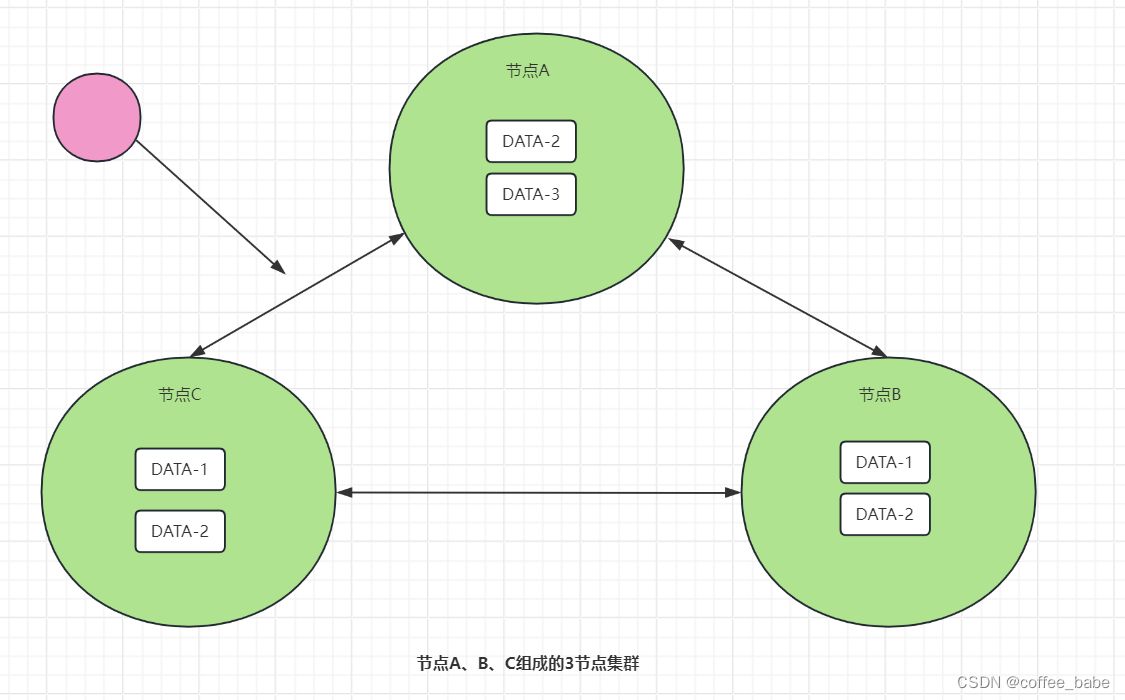
N表示副本数,又叫作复制因子(Replication Factor)。也就是说,N表示集群中同一份数据有多少个副本,如图所示,从图中可以看到,在这个3节点集群中,DATA-1有2个副本,DATA-2有3个副本,DATA-3有1个副本。也就是说,副本数可以不等于节点数,不同的数据可以有不同的副本数。
需要注意的是,在实现Quorum NWR算法的时候,你需要实现自定义副本的功能。也就是说,用户可以自定义指定数据的副本数,比如,用户可以指定DATA-1具有2个副本,DATA-2具有3个副本。
当指定了副本后,我们就可以对副本数据进行读写操作了。但是,这么多副本,你要如何执行读写操作呢?先来看一看写操作,也就是W.
-
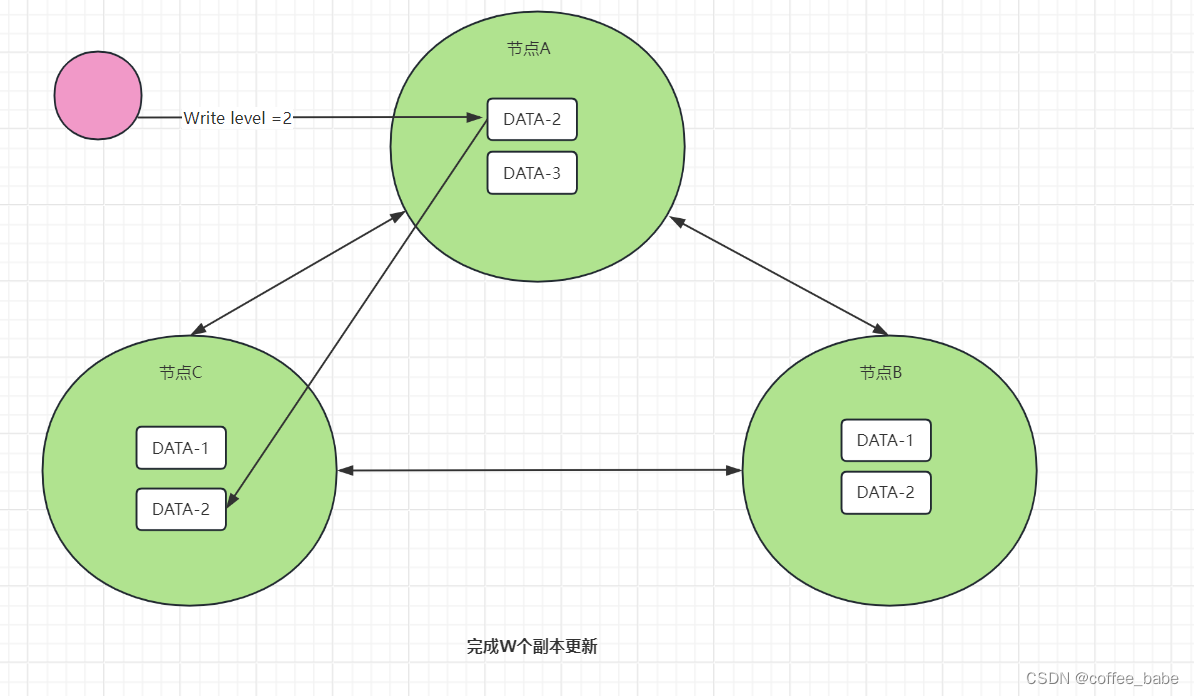
W,又称写一致性级别(Write Consistency Level),表示成功完成W个副本更新才能完成写操作,如图所示。
从图中可以看到,DATA-2的写副本数为2,也就是说,对DATA-2执行写操作是,只有完成了2个副本的更新(比如节点A、C)才完成写操作。
有的人可能会问,DATA-2有3个数据副本,如果完成了2个副本的更新就表示完成了写操作,那么如何实现强一致性呢?如果客户端读到第3个数据副本(比如节点B),不就可能无法读到更新后的值了吗?
-
R,又称读一致性级别(Read Consistency Level),表示读取一个数据对象时需要读取R个副本。也可以这么理解,读取指定数据时要读取R个副本,然后返回R个副本中最新的那份数据,如图所示。从图中可以看到,DATA-2的读副本数为2,也就是说,客户端读取DATA-2的数据时,需要读取2个副本中的数据,然后返回最新的那份数据。
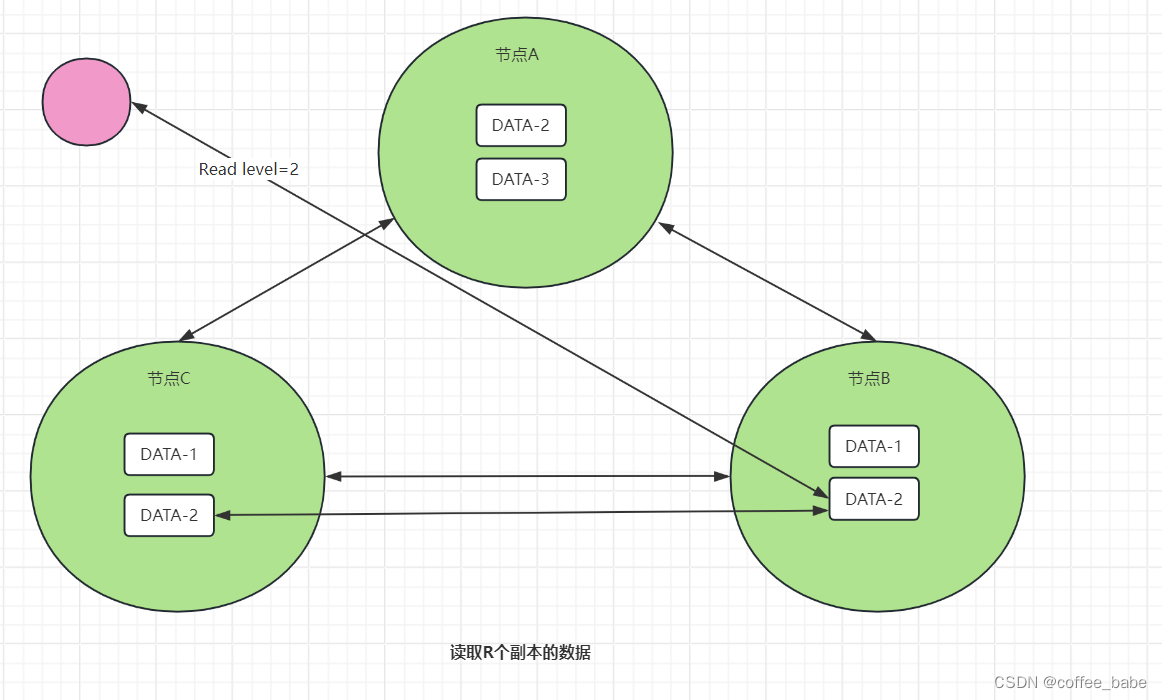
这里需要注意的是,无论客户端如何执行读操作,哪怕它访问的是写操作未强制更新副本数据的节点(比如节点B),但因为W(2) + R(2) > N(3),也就是说,访问节点B执行读操作时,因为要读2份数据副本,所以除了节点B上的DATA-2,还会读取节点A或节点C上的DATA-2,如上图所示(比如节点C上的DATA-2),而节点A和节点C的DATA-2数据副本是强制更新成功的,所以返回给客户端的数据肯定是最新的那份数据。
你看,通过设置R为2,即是读到前面问题中的第3份副本数据(比如节点B),也能返回更新后的那份数据,实现强一致性。
除此之外,关于Quorum NWR算法,我们还需要注意的是,N、W、R的值的不同组合会产生不同的一致性效果,具体来说,不同组合会产生如下两种效果。
- 1.当W+R>N的时候,对于客户端来说,整个系统能保证强一致性,即一定能返回更新后的那份数据
- 2.当W+R ≤ N的时候,对于客户端来说,整个系统只能保证最终一致性,即可能会返回旧数据。
如何实现Quorum NWR
在InfluxDB企业版中,我们可以在创建保留策略时设置指定数据库对应的副本数,如代码所示
create retention policy "rp_one_day" on "telegraf" duration 1d replication 3
在上述代码中,我们通过replication参数指定了数据库telegraf对应的副本数为3。需要注意的时,在InfluxDB企业版中,副本数不能超过节点数据。你可以这样理解,多副本的意义在于冗余备份,如果副本数超过节点数,就意味着一个节点上会存在多个副本,那么这时冗余备份的意义就不大了。比如机器故障时,节点上的多个副本是同时被影响的。
InfluxDB企业版支持"Any、One、Quorum、All"4种写一致性级别,具体含义分析如下:
- 1.Any:任何一个节点写入成功后,或者接收节点已将数据写入Hinted-handoff缓存(也就是写其他节点失败后,本地节点上缓存写失败数据的队列)后,就会返回成功给客户端
- 2.One:任何一个节点写入成功后,就会立即返回成功给客户端,不包括成功写入Hinted-handoff缓存
- 3.Quorum:当大多数节点写入成功后,就会返回给客户端。此选项仅在副本数大于2时才有意义,否则等效于All
- 4.All:仅在所有节点都写入成功后,返回成功
强调一下,对时序数据库而言,读操作会拉取大量数据,其查询性能是挑战,是必须要考虑优化的。因此,InfluxDB企业版不支持读一致性级别,只支持写一致性级别。另外,我们还可以设置写一致性级别为All,来实现强一致性。
如果我们像InfluxDB企业版这样实现了Quorum NWR算法,那么在业务临时需要实现强一致性时,就可以通过设置写一致性级别为All来实现了
重点总结
- 1.一般而言,不推荐副本数超过当前的节点数,因为当副本数超过节点数时,就会出现同一个节点存在多个副本的情况。当这个节点有故障时,上面的多个副本就都会收到影响
- 2.当W+R>N时,可以实现强一致性。另外,如何设置N、W、R值,取决于我们想优化哪方面的性能。比如,N决定了副本的冗余备份能力;如果设置W=N,则读性能较好;如果设置R=N,则写性能比较好;如果设置W=(N+1)/2、 R=(N+1)/2,则容错能力比较好,能容忍少数节点[也就是(N-1)/2]的故障。
最后,Quorum NWR算法是一种非常使用的算法,能有效地弥补AP型系统缺乏强一致性的通电,给业务提供了按需选择一致性级别的灵活度。建议子啊开发实现AP型系统时也采用Quorum NWR算法。另外,我们在实际开发种,除了需要考虑数据访问的一致性,还需要考虑系统状态的一致性,也即实现事务,那么如何在分布式系统中实现事务呢?
这篇关于分布式与一致性协议之Quorum NWR算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







