本文主要是介绍超标量处理器设计:重排序缓存(ROB),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
★超标量处理器的很多地方用到了重排序缓存,但是我对它不是很了解,所以我整理一下重排序缓存的知识点。
重排序缓存(ROB)在确保乱序执行的指令能够正确地完成和提交(Commit),也可以用来寄存器重命名。
ROB是一个先进先出的表,每个项是ROB表项,可以记录指令执行的信息。
ROB表项的字段
(1)Complete: 标志位,用来标记指令是否已经完成执行阶段。当指令的所有操作(包括计算、访存等)都完成,标志就会被置为“是”,指令准备好进入退休阶段。
(2)Areg:指令在程序代码中指定的目的寄存器(逻辑寄存器)。
(3)Preg:物理寄存器的编号,经过寄存器重命名后指令实际使用的物理寄存器。
(4)OPreg:Old Physical Register,记录Areg在被重命名到当前Preg之前所对应的物理寄存器编号。在指令因异常需要回滚恢复状态时,OPreg用于指向应该恢复的物理寄存器状态,确保异常处理后的状态正确。
(5)PC:指令的程序计数器(PC)值。当指令执行过程中遇到中断时,保存这个PC能够从正确的点重新开始执行程序。
(6)Exception:如果指令执行中触发了异常,字段会记录异常的类型。指令即将退休时,处理器会根据异常类型执行相应的处理逻辑,可能是中止指令执行、恢复现场或是执行特定的异常处理程序。
(7)Type:记录指令的类型,如算术逻辑运算、加载、存储、跳转等。指令退休时,处理器会依据不同的指令类型执行相应的动作,比如存储指令需要把结果写入数据缓存(D-Cache),分支指令则可能需要清理预测执行的痕迹(如恢复检查点资源)。
ROB工作原理
分发(Dispatch)阶段
指令从指令队列或解码阶段被取出,进入流水线执行。每个指令在进入流水线时,会在ROB中分配一个唯一的表项(Entry)。表项会记录该指令的初始状态。将complete状态位设为0,表示指令尚未执行完成。同时,指令的目的寄存器信息、PC值等也会被记录下来。
执行(Execution)阶段
指令在执行阶段完成计算后,将complete状态位设为1,该指令已经执行完毕,计算结果可能被暂时存储在ROB中或直接写入物理寄存器堆(PRF)。如果执行过程中发生异常,异常类型也会被记录在ROB对应的表项中,但异常的实际处理被推迟到提交阶段。
异常与退休(Exception & Commit)阶段
所有对程序状态的最终更改,包括结果的写回、异常处理,都发生在提交阶段。只有当指令的complete状态为1,且所有先前的指令(在程序顺序上)也已正确执行并退休时,该指令才能退休。计算结果根据Areg和Preg信息被写入到寄存器或内存中。
若存在异常,处理器会根据ROB中记录的异常类型进行相应处理,可能包括恢复现场、跳转到异常处理程序等。
ROB工作例子

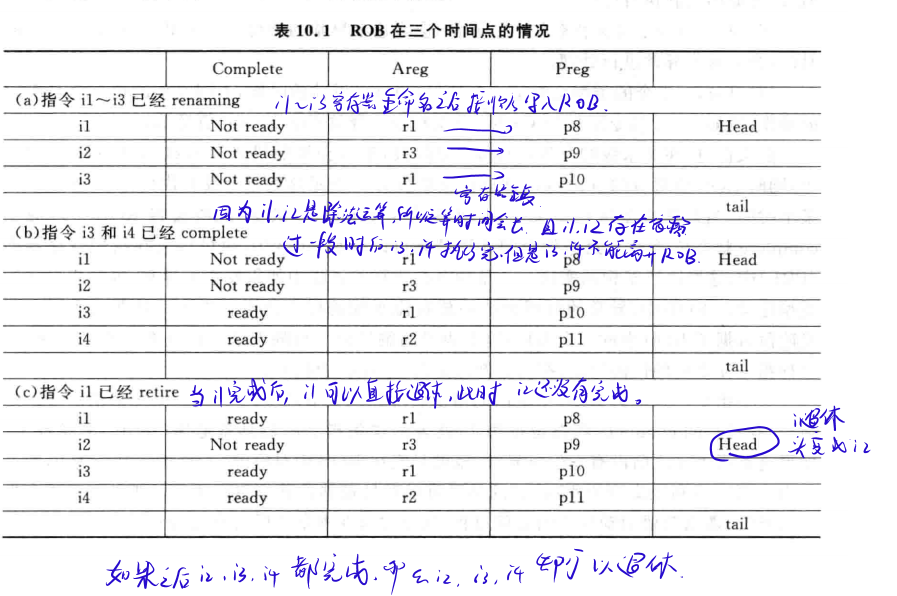
所以ROB就是一个先进先出的队列,当后面的指令执行完必须等到前面的执行完才可以退休。
这篇关于超标量处理器设计:重排序缓存(ROB)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







