本文主要是介绍SQLSERVER CPU占用过高的优化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
有同事反应服务器CPU过高,一看截图基本都是100%了,my god,这可是大问题,赶紧先看看。
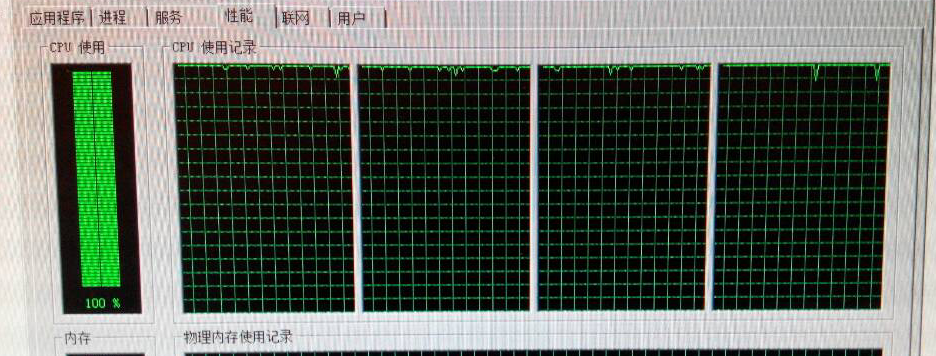
让同事查看系统进程,发现是SQLServer的CPU占用比较高。首先想到的是不是报表生成的时候高,因为这块之前出现过问题,关掉服务程序,还是高。难道是客户端程序引发的?但是这么多的客户端连接,难不成每个都叫人关闭,很简单,把网络断开即可。网络断开之后,CPU立马下降。那么问题到底在哪里呢,是时候祭出我们的利器了——SQLServer Profiler。
使用SQLServer Profiler监控数据库
让同事使用SQLProfiler监控了大概20分钟左右,然后保存为跟踪文件*.rtc。
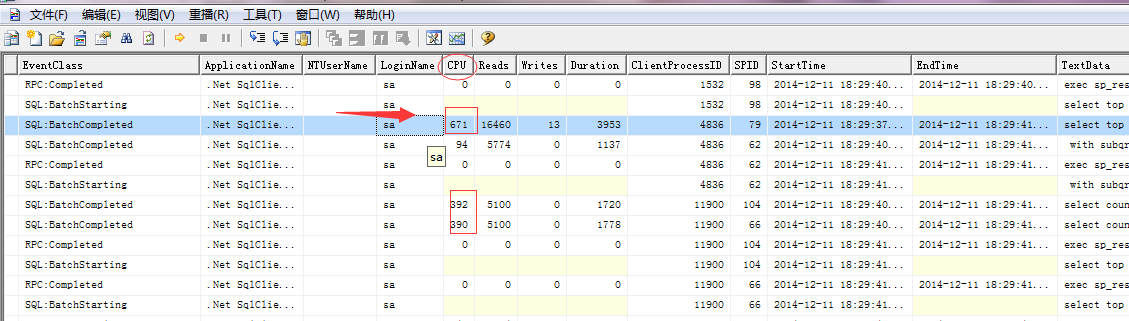
我们来看看到底是哪句SQL有问题:
SQL1:查找最新的30条告警事件
select top 30 a.orderno,a.AgentBm,a.AlarmTime,a.RemoveTime,c.Name as AddrName,b.Name as MgrObjName,a.Ch,a.Value,a.Content,a.Level,ag.Name as AgentServerName,a.EventBm,a.MgrObjId,a.Id,a.Cfmoper,a.Cfm,a.Cfmtime,a.State,a.IgnoreStartTime,a.IgnoreEndTime,a.OpUserId,d.Name as MgrObjTypeName,l.UserName as userName,f.Name as AddrName2
from eventlog as a left join mgrobj as b on a.MgrObjId=b.Id and a.AgentBm=b.AgentBm left join addrnode as c on b.AddrId=c.Id left join mgrobjtype as d on b.MgrObjTypeId=d.Id left join eventdir as e on a.EventBm=e.Bm left join agentserver as ag on a.AgentBm=ag.AgentBm left join loginUser as l on a.cfmoper=l.loginGuid left join addrnode as f on ag.AddrId=f.Id
where ((MgrObjId in (select Id from MgrObj where AddrId in ('','02100000','02113000','02113001','02113002','02113003','02113004','02113005','02113006','02113007','02113008','02113009','02113010','02113011','02113012','02113013','02113014','02113015','02113016','02113017','02113018','02113019','02113020','02113021','02113022','02113023','02113024','02113025','02113026'))) or (mgrobjid in ('00000000-0000-0000-0000-000000000000','00000000-0000-0000-0000-000000000000','00000000-0000-0000-0000-000000000000','11111111-1111-1111-1111-111111111111','11111111-1111-1111-1111-111111111111')))
order by alarmtime DESCSQL2:获取当前的总报警记录数
select count(*) from eventlog as a left join mgrobj as b on a.MgrObjId=b.Id and a.AgentBm=b.AgentBm left join addrnode as c on b.AddrId=c.Id left join mgrobjtype as d on b.MgrObjTypeId=d.Id left join eventdir as e on a.EventBm=e.Bm
where MgrObjId in (select Id from MgrObj where AddrId in ('','02100000','02100001','02100002','02100003','02100004','02100005','02100006','02100007','02100008','02100009','02100010','02100011','02100012','02100013','02100014','02100015','02100016','02100017','02100018','02100019','02101000','02101001','02101002','02101003','02101004','02101005','02101006','02101007','02101008','02101009','02101010','02101011','02101012','02101013','02101014','02101015','02101016','02101017','02101018','02101019','02101020','02101021','02101022','02101023','02101024','02101025','022000','022001','022101','022102','0755','0755002')) and mgrobjid not in ('00000000-0000-0000-0000-000000000000','00000000-0000-0000-0000-000000000000','00000000-0000-0000-0000-000000000000','11111111-1111-1111-1111-111111111111','11111111-1111-1111-1111-111111111111')这是典型的获取数据并分页的数据,一条获取最新分页记录总数,一条获取分页记录,正是获取最新事件这里导致的CPU过高。这里的业务大概是每个客户端,每3秒执行一次数据库查找,以便显示最新的告警事件。好了,元凶找到了,怎么解决?
有哪些SQL语句会导致CPU过高?
上网查看了下文章,得出以下结论:
1.编译和重编译
编译是 Sql Server 为指令生成执行计划的过程。Sql Server 要分析指令要做的事情,分析它所要访问的表格结构,也就是生成执行计划的过程。这个过程主要是在做各种计算,所以CPU 使用比较集中的地方。
执行计划生成后会被缓存在 内存中,以便重用。但是不是所有的都可以 被重用。在很多时候,由于数据量发生了变化,或者数据结构发生了变化,同样一句话执行,就要重编译。
2.排序(sort) 和 聚合计算(aggregation)
在查询的时候,经常会做 order by、distinct 这样的操作,也会做 avg、sum、max、min 这样的聚合计算,在数据已经被加载到内存后,就要使用CPU把这些计算做完。所以这些操作的语句CPU 使用量会多一些。
3.表格连接(Join)操作
当语句需要两张表做连接的时候,SQLServer 常常会选择 Nested Loop 或 Hash 算法。算法的完成要运行 CPU,所以 join 有时候也会带来 CPU 使用比较集中的地方。
4.Count(*) 语句执行的过于频繁
特别是对大表 Count() ,因为 Count() 后面如果没有条件,或者条件用不上索引,都会引起 全表扫描的,也会引起 CPU 的大量运算
大致的原因,我们都知道了,但是具体到我们上述的两个SQL,好像都有上述提到的这些问题,那么到底哪个才是最大的元凶,我们能够怎么优化?
查看SQL的查询计划
SQLServer的查询计划很清楚的告诉了我们到底在哪一步消耗了最大的资源。我们先来看看获取top30的记录:
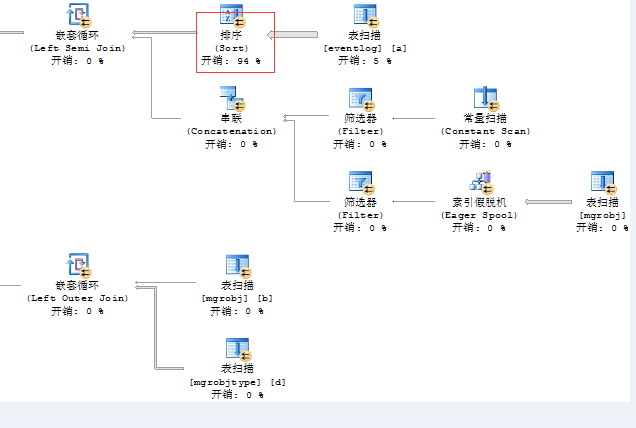
排序竟然占了94%的资源。原来是它!同事马上想到,用orderno排序会不会快点。先把上述语句在SQLServer中执行一遍,清掉缓存之后,大概是2~3秒,然后排序字段改为orderno,1秒都不到,果然有用。但是orderno的顺序跟alarmTime的顺序是不完全一致的,orderno的排序无法替代alarmTime排序,那么怎么办?我想,因为选择的是top,那么因为orderno是聚集索引,那么选择前30条记录,可以立即返回,根本无需遍历整个结果,那么如果alarmTime是个索引字段,是否可以加快排序?
选择top记录时,尽量为order子句的字段建立索引
先建立索引:
IF NOT EXISTS(SELECT * FROM sysindexes WHERE id=OBJECT_ID('eventlog') AND name='IX_eventlog_alarmTime')CREATE NONCLUSTERED INDEX IX_eventlog_alarmTime ON dbo.eventlog(AlarmTime)在查看执行计划:
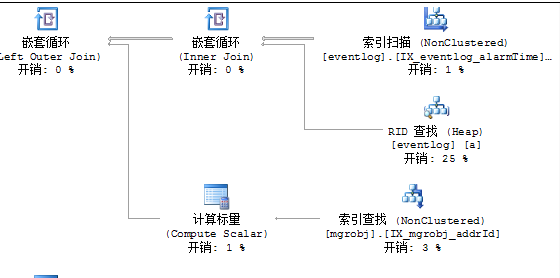
看到没有,刚才查询耗时的Sort已经消失不见了,那么怎么验证它能够有效的降低我们的CPU呢,难道要到现场部署,当然不是。
查看SQL语句CPU高的语句
SELECT TOP 10 TEXT AS 'SQL Statement',last_execution_time AS 'Last Execution Time',(total_logical_reads + total_physical_reads + total_logical_writes) / execution_count AS [Average IO],(total_worker_time / execution_count) / 1000000.0 AS [Average CPU Time (sec)],(total_elapsed_time / execution_count) / 1000000.0 AS [Average Elapsed Time (sec)],execution_count AS "Execution Count",qs.total_physical_reads,qs.total_logical_writes,qp.query_plan AS "Query Plan"
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.plan_handle) st
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
ORDER BY total_elapsed_time / execution_count DESC我们把建索引前后CPU做个对比:

已经明显减低了。
通过建立相关索引来减少表扫描
我们再来看看count(*)这句怎么优化,因为上面的这句跟count这句差别就在于order by的排序。老规矩,用查询计划看看。
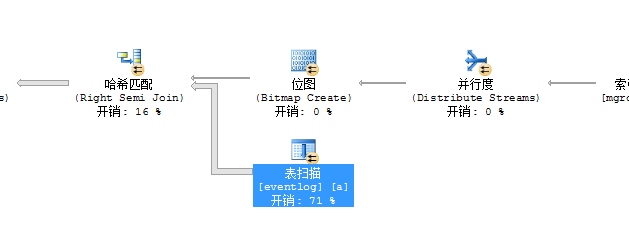
用语句select count(0) from eventlog一看,该表已经有20多w的记录,每次查询30条数据,竟然要遍历这个20多w的表两次,能不耗CPU吗。我们看看是否能够利用相关的条件来减少表扫描。很明显,我们可以为MgrObjId建立索引:
CREATE NONCLUSTERED INDEX IX_eventlog_moid ON dbo.eventlog(MgrObjId)
但是无论我怎么试,都是没有利用到索引,难道IN子句和NOT IN子句是没法利用索引一定会引起表扫描。于是上网查资料,找到桦仔的文章,这里面有解答:
SQLSERVER对筛选条件(search argument/SARG)的写法有一定的建议
对于不使用SARG运算符的表达式,索引是没有用的,SQLSERVER对它们很难使用比较优化的做法。非SARG运算符包括
NOT、<>、NOT EXISTS、NOT IN、NOT LIKE和内部函数,例如:Convert、Upper等
但是这恰恰说明了IN是可以建立索引的啊。百思不得其解,经过一番的咨询之后,得到了解答:
不一定是利用索引就是好的,sqlserver根据你的查询的字段的重复值的占比,决定是表扫描还是索引扫描
有道理,但是我查看了下,重复值并不高,怎么会有问题呢。
关键是,你select的字段,这个地方使用索引那么性能更差,你select字段 id,addrid,agentbm,mgrobjtypeid,name都不在索引里。
真是一语惊醒梦中人,缺的是包含索引!!!关于包含索引的重要性我在这篇文章《我是如何在SQLServer中处理每天四亿三千万记录的》已经提到过了,没想到在这里又重新栽了个跟头。实践,真的是太重要了!
通过建立包含索引来让SQL语句走索引
好吧,立马建立相关索引:
IF NOT EXISTS(SELECT * FROM sysindexes WHERE id=OBJECT_ID('eventlog') AND name='IX_eventlog_moid')CREATE NONCLUSTERED INDEX IX_eventlog_moid ON dbo.eventlog(MgrObjId) INCLUDE(EventBm,AgentBM)我们再来看看查询计划:
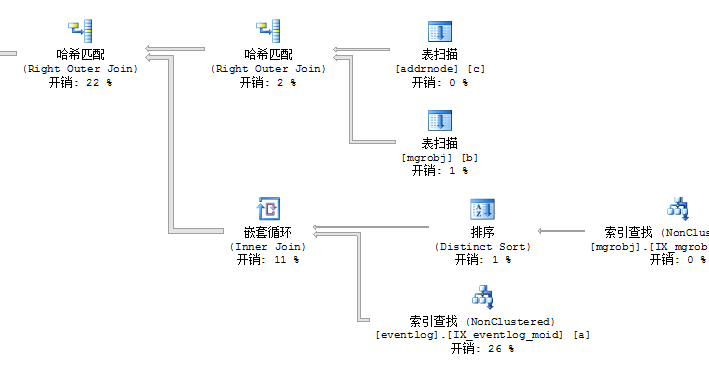
看到没有,已经没有eventlog表的表扫描了。我们再来比较前后的CPU:

很明显,这个count的优化,对查询top的语句依然的生效的。目前为止,这两个查询用上去之后,再也没有CPU过高的现象了。
其他优化手段
- 通过服务端的推送,有事件告警或者解除过来才查询数据库。
- 优化上述查询语句,比如count(*)可以用count(0)替代——参考《SQL开发技巧(二)》
- 优化语句,先查询出所有的MgrObjId,然后在做连接
- 为管理对象、地点表等增加索引
- 添加了索引之后,事件表的插入就会慢,能够再怎么优化呢?可以分区建立索引,每天不忙的时候,把新的记录移入到建好索引的分区
当然,这些优化的手段是后续的事情了,我要做的事情基本完了。
总结
- 服务器CPU过高,首先查看系统进程,确定引发CPU过高的进程
- 通过SQLServer Profiler能够轻易监控到哪些SQL语句执行时间过长,消耗最多的CPU
- 通过SQL语句是可以查看每条SQL语句消耗的CPU是多少
- 导致CPU高的都是进行大量计算的语句:包括内存排序、表扫描、编译计划等。
- 如果使用Top刷选前面几条语句,则尽量为Order By子句建立索引,这样可以减少对所有的刷选结果进行排序
- 使用Count查询记录数时,尽量通过为where字句的相关字段建立索引以减少表扫描。如果多个表进行join操作,则把相关的表连接字段建立在包含索引中
- 通过服务端通知的方式,减少SQL语句的查询
- 通过表分区,尽量降低因为添加索引而导致表插入较慢的影响
这篇关于SQLSERVER CPU占用过高的优化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







