本文主要是介绍六、Redis五种常用数据结构-zset,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
zset是Redis的有序集合数据类型,但是其和set一样是不能重复的。但是相比于set其又是有序的。set的每个数据都有一个double类型的分数,zset正是根据这个分数来进行数据间的排序从小到大。有序集合中的元素是唯一的,但是分数(score)是可以重复的。每个zset集合最多可以存放232-1个数据。zset常被用于排行榜功能。
1、常用命令
- zadd key score1 member1 [score2 member2]:向有序集合中添加一个或多个数据,或者更新已存在成员的分数(member会先删除在重新插入)。
- zcard key:获取集合的数据个数。
- zcount key min max:计算集合中在指定分数区间内的数据个数。
- zincrby key increment member:在集合指定成员的分数加上增量increment。increment为负数表示减去相应的值。
- zinterstore destination numberkeys key [key…]:计算给定的一个或者多个集合的交集,并将结果存储到destination中。结果集中某个成员的分数是所有给定的集合该成员所有分数的和。
- zlexcount key min max:在有序集合中计算指定字典区间内的成员数量。
- zrange key start end[withscores]:通过索引区间返回指定区间内的成员。
- zrangebylex key min max[limit offset count]:通过字典区间返回有序集合的成员。
- zrangebyscore key min max[withscores][limit]:通过分数返回集合中的成员。
- zrank key member:返回有序集合中指定成员的索引。
- zrem key member [memeber…]:删除集合中一个或者多个成员。
- zremrangebylex key min max:移出集合中指定字典区间内的所有成员。
- zremrangebyrank key start stop:移出有序集合中给定的排名区间内的所有成员。
- zrevrange key start end[withscores]:返回指定索引区间内的成员,分数从高到低。
- zrevrangebyscore key max min[withscores]:返回集合中指定分数区间内的成员,分数从高到低。
- zrevrank key member:返回集合中指定成员的排名。0表示最高。
- zscore key member:返回集合中指定成员的分数。
- zunionstore destination numberkeys key [key…]:计算给定的一个或者多个集合的并集,并存储在destination中。
- zscan key cursor[match pattern][COUNT count]:迭代集合的元素。
2、底层实现
zset的底层实现有两种,ziplist和dict+skiplist。
2.1、ziplist
2.1.1、使用条件
- 集合中元素数量小于128个。
- 每个元素的长度小于64字节。
以上两个条件有任何一个不满足,就会使用dict+skiplist的结构存储数据。
每个集合元素使用紧挨着的两个压缩列表节点保存,第一个节点保存元素的成员,第二个保存元素的分数。

2.1.2、ziplist结构
见Hash中的ziplist
2.2、dict+skiplist
2.2.1、介绍
dict用来存储value到score的映射关系,这样就可以在O(1)时间内找到对应value的score值。skiplist按照从小到大的顺序存储分数。skiplist每个元素的值都是[score,value]对。
2.2.2、zset结构
typedf struct zset{//字典,键为value,值为scoredict* dict;//跳表,按分值进行排序zskiplist *zsl;
}zset;
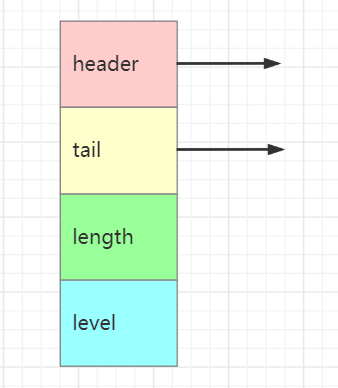
typedf struct zskiplist{//头节点struct zskiplistNode *header;//尾节点struct zskiplistNode *tail;//跳表中的元素个数unsigned long length;//目前表内节点最高的层数int level;
}zskiplist;
zskiplist的示意图如下:
typedf struct zskiplistNode{//具体的数据sds ele;//分数double size;//后退指针struct zskiplistNode *backward;struct zskiplistLevel{//前进指针struct zskiplistNode *forward;/跨服unsigned int span;}level[]; //层数数组 最大32
}zskiplistNode;
skiplistNode的示意图如下:

2.2.3、skiplist-跳表
跳表skiplist在Redis中的使用场景只有一个,那就是作为zset的底层结构实现。跳表可以保证增、删、查的时间复杂度为O(logN),其余一般的链表结构的时间复杂度为O(n)相比,性能上有不少的提升。但是唯一美中不足的是跳表需要占用更多的空间,其实这就是一种空间换时间的思想。跳表的结构如下:

Redis中的跳表的实现有点类似于Kafka中的稀疏索引。
在Kafka中进行持久化的时候,会生成两个文件,一个是xxxxxx.log,一个是xxxxxx.index,其中log文件中以链表的方式保存着消息。而index文件中则保存着这些消息的索引,或者说是偏移量,但又不是每一条消息的索引都在index文件中。index中的索引是稀疏的,比如log文件中的索引是0-10000,那么index文件中存储的索引可能是100,500,700,1000,5000,6500,每个索引中都保存着对应log文件中消息的具体位置。如图:

当要访问899这个索引的消息时,先去index文件中查找,找到了700到1000的这个区间,根据700这个索引去log文件中找到700这个索引的消息,然后顺着700这个消息顺序往下找,直到找到899这个索引的消息。从这个实现中,我们看到Kafka并没有对log文件进行全部的遍历,而是先通过index中的稀疏索引,找到一个大概的位置,然后顺序遍历。

Redis的跳表的实现方式与上面的类似,不过Kafka的稀疏索引只有一层,而Redis的稀疏索引是多层。如图:

所有的元素都会在L0层的链表中,根据分数进行排序,同时会有一部分节点被抽取到L1层,作为一个稀疏索引,同样L1层的索引也有一定的机会被抽取到L2层,以此类推,Redis允许跳表中一个节点最高有**64层,**一个跳表中最多存储264 个元素。
2.2.4、跳表-增、删、查
首先假定有这么一个跳表,这里只展示分数:

如果要查找分数为66的元素,首先在L2层的索引查找。很明显。66位于25和85之间:
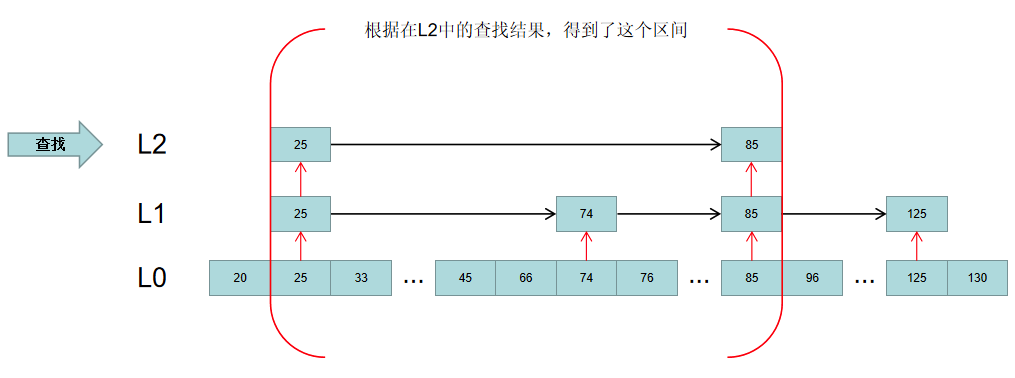
然后根据获得的区间,去对应的L1的区间查找,得到一个更精确的区间:

最终根据更精确的区间,去L0层顺序遍历,即可找到要查找的元素:

上述即是对跳表原理的一个描述。
这种跳表的实现,其实和二分查找的思路接近,只是一方面因为二分查找法只能适用与数组,而无法用于链表,所以为了让链表有二分查找类似的效率,就以空间换时间来达到目的。
跳表因为是一个根据分数权重进行排序的列表,可以在很多场景中使用,比如排行榜,搜索排序等。
这篇关于六、Redis五种常用数据结构-zset的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




