本文主要是介绍提高谷歌抓取成功率:代理IP的7个使用误区,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在当今数字化时代,数据采集和网络爬取已成为许多企业和个人必不可少的业务活动。对于爬取搜索引擎数据,特别是Google,使用代理IP是常见的手段。然而,使用代理抓取Google并不是一件轻松的事情,有许多常见的误区可能会导致爬取失败甚至被封禁。下面这些误区千万别踩!

误区一:免费代理可解决所有问题
我知道很多人会去薅免费的代理羊毛,因为它们节省成本。然而,免费代理通常质量较低,连接速度慢,容易被封禁,且隐私保护较差。Google很容易检测到大量使用免费代理的请求,从而可能封禁这些代理的IP地址。建议选择付费的高质量代理服务,以确保稳定和可靠的数据抓取。
1.不稳定性:免费代理通常由不稳定的服务器提供,容易出现连接中断或无法访问的情况,导致数据采集的不稳定性和不可靠性。
2.速度慢:由于免费代理被大量用户共享,服务器负载较高,导致连接速度缓慢,影响数据采集的效率。
3.容易被封禁:由于免费代理通常被多个用户同时使用,而这些用户可能进行大量频繁的抓取行为,导致代理IP地址容易被Google封禁,使数据采集难以进行。
4.安全隐患:免费代理通常没有经过严格的安全审查和监管,可能存在安全漏洞和数据泄漏的风险,影响用户的数据安全和隐私。
实际上高质一点的代理IP服务也并不昂贵,代理ip服务商IPFoxy是全球动静态代理提供商,可以保证代理独享免受其他共用者影响,更加安全,为了降低业务试错成本,提供免费测试额度。
误区二:使用大量并发连接可以提高效率
一些人认为增加并发连接数可以加快数据抓取速度。然而,Google有自己的反爬虫机制,大量并发连接会引起警觉,导致IP被封禁。恰当设置并发连接数,避免过于频繁地请求,可以降低被封禁的风险,同时保持较好的抓取效率。
误区三:忽略隐私和法律问题
使用代理抓取Google数据时,忽略隐私和法律问题可能会带来严重的后果。例如,某些国家和地区对数据爬取有严格的法律规定,未经授权的数据抓取可能违法。此外,抓取用户敏感信息或侵犯用户隐私也会导致法律问题。在进行数据抓取之前,务必了解当地法律规定,确保合法合规地进行抓取活动。
误区四:忽略Google的robots.txt文件
Google的robots.txt文件是网站管理员用来指示搜索引擎爬虫哪些页面可以访问和抓取的文件。忽略robots.txt文件,直接抓取网站数据,可能导致被Google视为违反规定,从而影响网站在搜索结果中的排名或被封禁。在进行数据抓取时,务必遵守网站的robots.txt文件,以避免不必要的麻烦。

误区五:不设置User-Agent或使用相同的User-Agent
User-Agent是一个HTTP头部字段,用于标识客户端的信息。不设置User-Agent或者使用相同的User-Agent会让Google很容易检测到大量请求来自同一个客户端,被视为恶意爬虫。正确设置User-Agent,模拟真实用户的访问行为,可以降低被封禁的风险。
误区六:频繁更换代理IP
一些人可能会频繁更换代理IP,以避免被封禁。然而,过于频繁地更换代理IP可能会被Google视为恶意行为,导致更多的封禁。建议选择稳定的代理IP,并适当调整抓取频率,以避免被封禁。
误区七:忽视代理IP的地理位置
在抓取Google数据时,代理IP的地理位置非常重要。如果使用的代理IP与目标网站所在地相差太大,可能会导致数据不准确或被屏蔽。选择与目标网站相近的地理位置的代理IP,可以提高抓取效率和数据准确性。
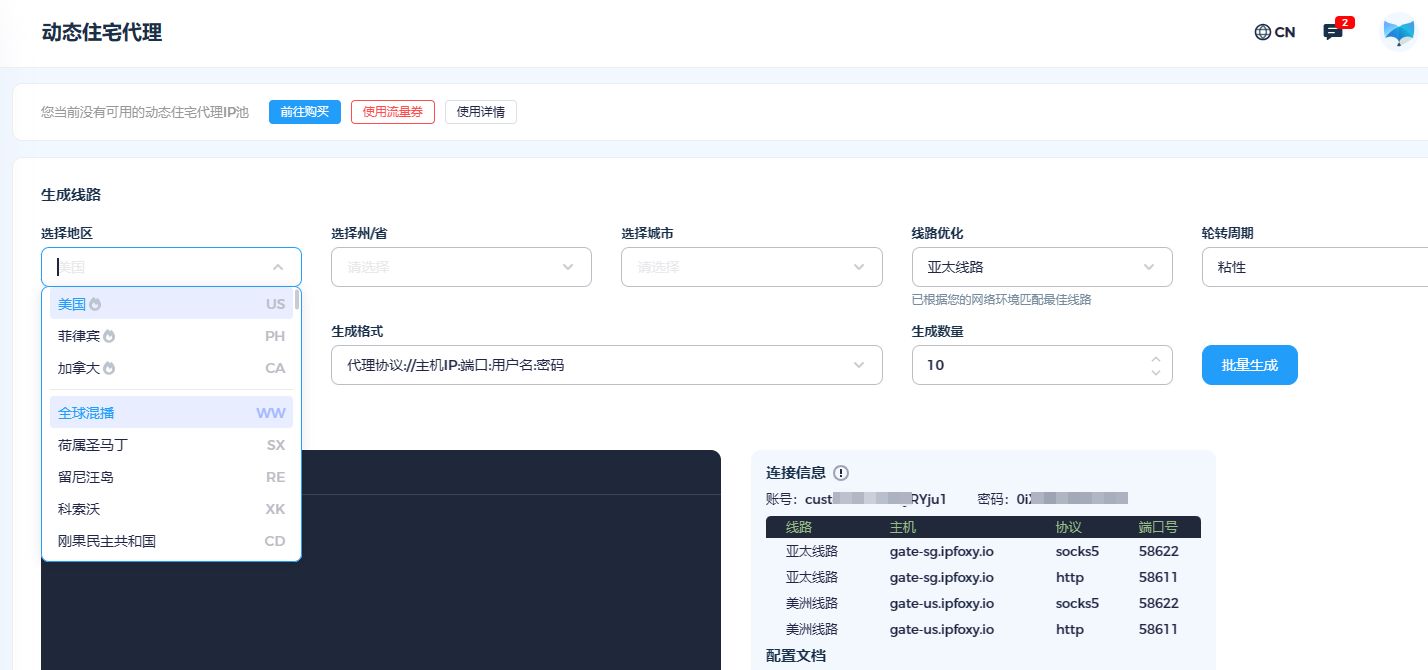
结论
在使用代理抓取Google数据时,需要避免以上七个常见误区,以确保顺利进行数据抓取,并降低被封禁的风险。选择高质量的付费代理服务,选择稳定的代理IP,都是确保成功抓取Google数据的关键因素。通过避免常见误区,您可以更加高效地进行Google数据的抓取,并从中获取有价值的信息和洞察。
这篇关于提高谷歌抓取成功率:代理IP的7个使用误区的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





