本文主要是介绍【R语言】生存分析模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
生存分析模型是用于研究时间至某个事件发生的概率的统计模型。这个事件可以是死亡、疾病复发、治疗失败等。生存分析模型旨在解决在研究时间相关数据时的挑战,例如右侧截尾(右侧截尾表示未观察到的事件发生,例如研究结束时还未发生事件)和数据缺失。
生存分析模型最常用的是 Cox 比例风险模型,也称为 Cox 回归模型,它是一种半参数化的模型,用于估计时间相关数据中危险比(hazard ratio)的关系。危险比描述了不同条件下事件发生的概率之比。在 Cox 比例风险模型中,假设危险函数是可共享的,即不受时间的影响,而危险比只依赖于协变量的值。
除了 Cox 比例风险模型外,还有其他类型的生存分析模型,如加速失效时间模型(accelerated failure time model)、Weibull 比例风险模型等。这些模型在不同的数据情况下可能更适用,具体取决于研究的问题和数据的性质。
生存分析模型通常应用于医学、流行病学、社会科学等领域,用于研究疾病生存率、药物治疗效果、生存质量等方面。以下通过Cox模型做一个生存风险分析:
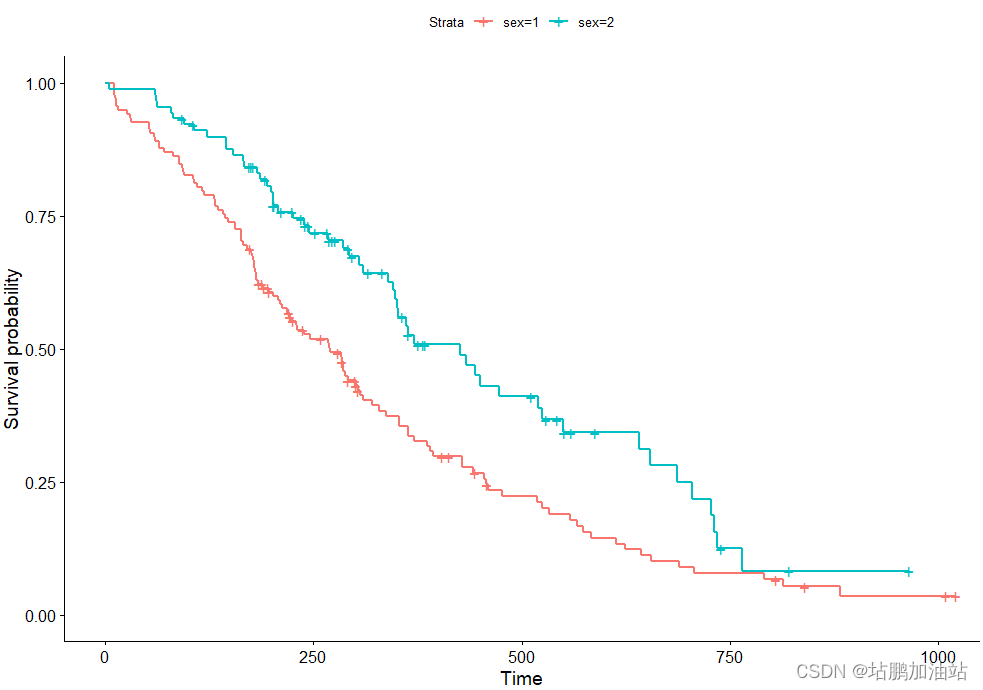
代码如下:
if(!require(devtools)) install.packages("devtools")
devtools::install_github("kassambara/survminer", build_vignettes = FALSE)
library("survminer")
require("survival")
fit <- survfit(Surv(time, status) ~ sex, data = lung)
ggsurvplot(fit, data = lung)ggsurvplot(fit, data = lung, censor.shape="|", censor.size = 4)-
首先,它检查是否已经安装了
devtools包。devtools是一个用于在 R 中开发和安装包的工具包。如果没有安装,它会使用install.packages()函数安装devtools包。 -
接下来,它使用
devtools包中的install_github()函数从 GitHub 上安装survminer包。survminer是一个 R 包,提供了用于生存分析可视化的工具和函数。 -
一旦
survminer包安装完成,代码通过library()函数加载了survminer包以便后续使用。library("survminer")将survminer包加载到 R 的工作环境中。 -
然后,代码使用
require()函数来检查是否已经加载了survival包。survival包是一个用于生存分析的常用包。如果未加载,require()函数会加载survival包。 -
survfit()函数用于拟合生存分析模型。在这个例子中,它拟合了一个 Cox 比例风险模型,其中生存时间由time变量表示,事件状态由status变量表示,与性别sex之间的关系进行建模。这个模型是基于lung数据集。 -
最后,
ggsurvplot()函数用于绘制生存曲线图。它接收拟合的生存分析模型fit和数据集lung作为输入,并生成一个生存曲线图,用于可视化不同性别在生存时间上的差异。
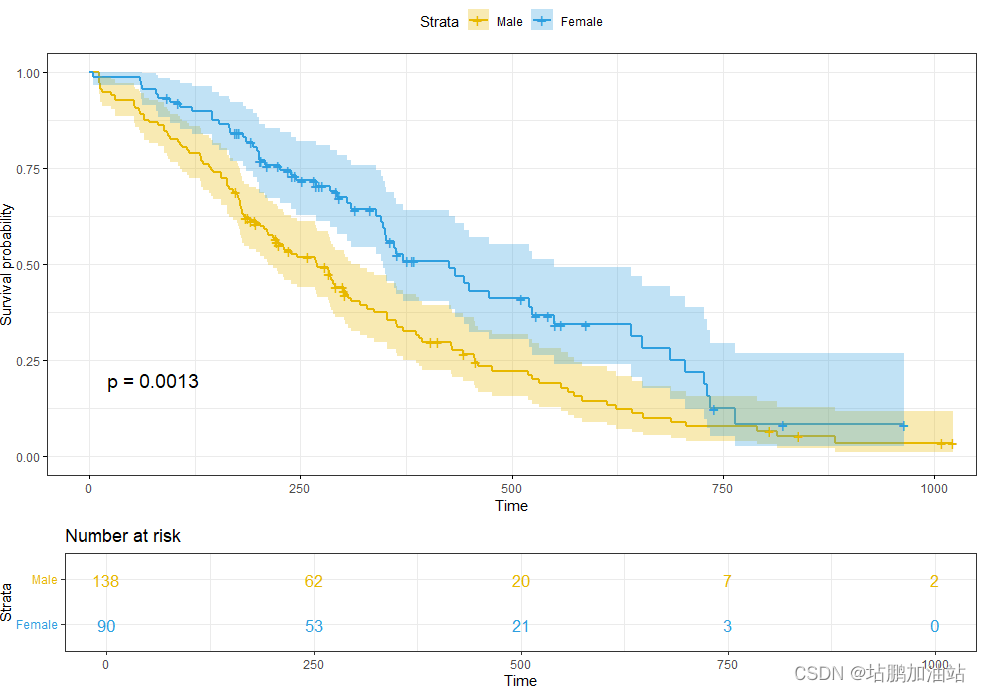 代码如下:
代码如下:
ggsurvplot(fit,data = lung,size = 1, # 改变线条大小palette =c("#E7B800", "#2E9FDF"),# 自定义颜色调色板conf.int = TRUE, # 添加置信区间pval = TRUE, # 添加 p 值risk.table = TRUE, # 添加风险表risk.table.col = "strata",# 风险表按组着色legend.labs =c("男性", "女性"), # 更改图例标签risk.table.height = 0.25, # 当有多个组时,修改风险表高度很有用ggtheme = theme_bw() # 更改 ggplot2 主题为黑白风格
)
这段代码调用了
ggsurvplot()函数,用于绘制生存曲线图,并设置了一些参数进行绘图的自定义。
size = 1:改变生存曲线的线条大小。palette = c("#E7B800", "#2E9FDF"):定义了两个颜色,用于表示不同性别的生存曲线。conf.int = TRUE:在生存曲线上添加了置信区间。pval = TRUE:在生存曲线图上添加了 p 值。risk.table = TRUE:在图的旁边添加了风险表。risk.table.col = "strata":根据不同的组(strata)对风险表进行了着色。legend.labs = c("男性", "女性"):将图例标签更改为了 "男性" 和 "女性"。risk.table.height = 0.25:当有多个组时,可以使用此参数来修改风险表的高度。ggtheme = theme_bw():将 ggplot2 的主题更改为了黑白风格。
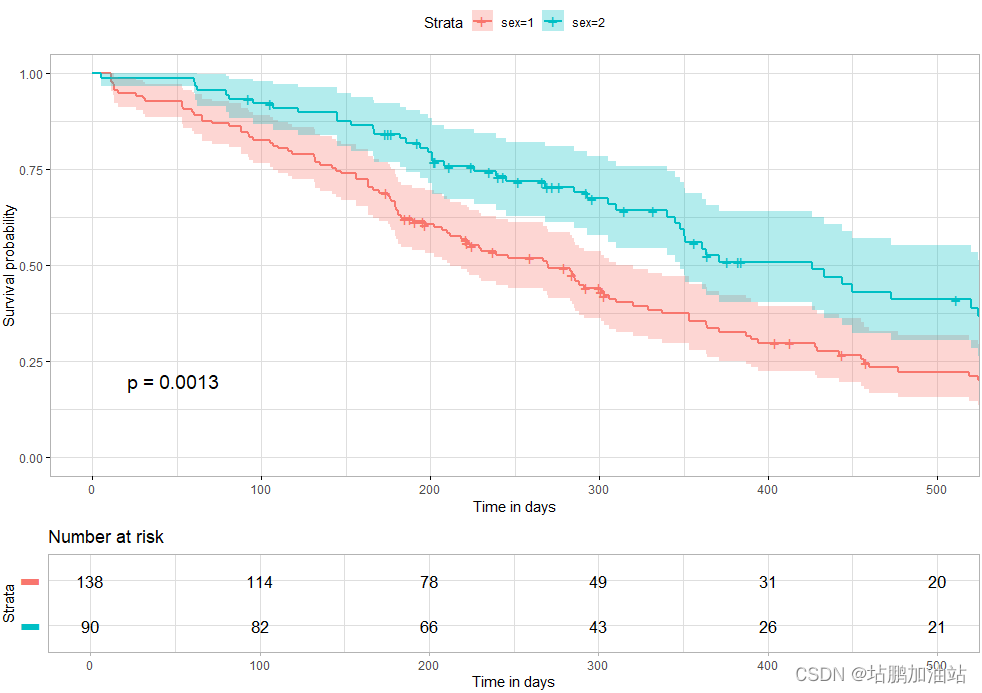
代码如下:
ggsurvplot(fit, # 拟合生存曲线的 survfit 对象。data = lung, # 用于拟合生存曲线的数据集。risk.table = TRUE, # 显示风险表。pval = TRUE, # 显示 log-rank 检验的 p 值。conf.int = TRUE, # 显示生存曲线点估计的置信区间。xlim = c(0,500), # 设置 X 轴范围为 0 到 500 天。xlab = "时间(天)", # 自定义 X 轴标签。break.time.by = 100, # 按 100 天的时间间隔分割 X 轴。ggtheme = theme_light(), # 使用 theme_light() 函数定制绘图和风险表的主题。risk.table.y.text.col = T, # 颜色风险表文本注释。risk.table.y.text = FALSE # 在风险表的文本注释中显示条形图而不是名称。
)
这段代码调用了
ggsurvplot()函数,用于绘制生存曲线图,并设置了一些参数进行绘图的自定义。
fit:拟合生存曲线的survfit对象。data = lung:用于拟合生存曲线的数据集。risk.table = TRUE:显示风险表。pval = TRUE:显示 log-rank 检验的 p 值。conf.int = TRUE:显示生存曲线点估计的置信区间。xlim = c(0,500):设置 X 轴范围为 0 到 500 天。xlab = "时间(天)":自定义 X 轴标签为 "时间(天)"。break.time.by = 100:按 100 天的时间间隔分割 X 轴。ggtheme = theme_light():使用theme_light()函数定制绘图和风险表的主题。risk.table.y.text.col = T:颜色风险表文本注释。risk.table.y.text = FALSE:在风险表的文本注释中显示条形图而不是名称。
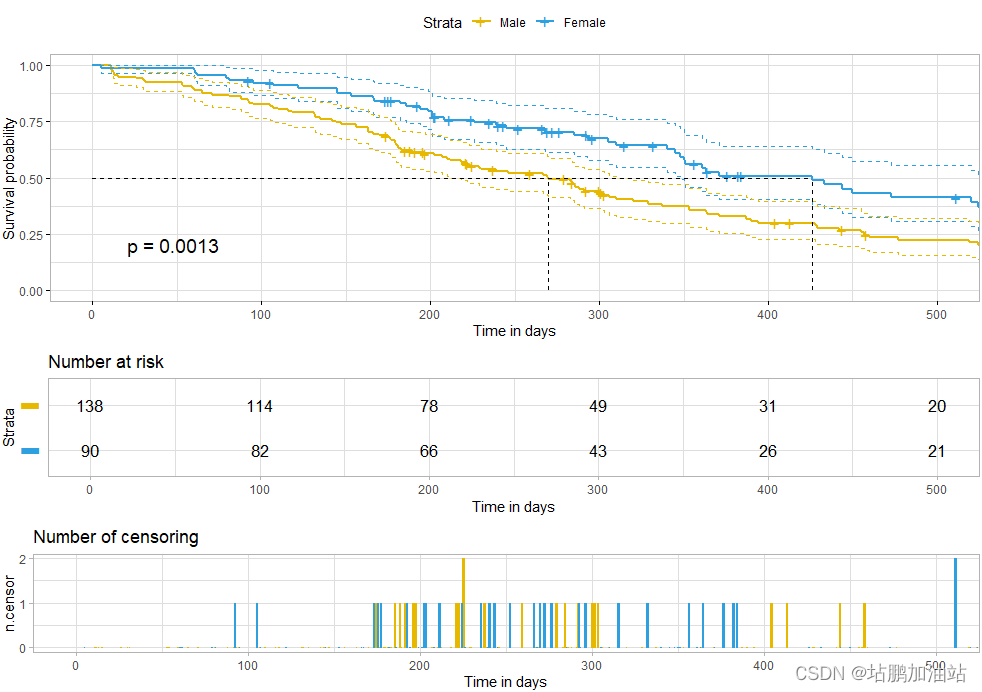 代码如下:
代码如下:
ggsurv <- ggsurvplot(fit, # 拟合生存曲线的 survfit 对象。data = lung, # 用于拟合生存曲线的数据集。risk.table = TRUE, # 显示风险表。pval = TRUE, # 显示 log-rank 检验的 p 值。conf.int = TRUE, # 显示生存曲线点估计的置信区间。palette = c("#E7B800", "#2E9FDF"), # 自定义颜色调色板。xlim = c(0,500), # 设置 X 轴范围为 0 到 500 天。xlab = "时间(天)", # 自定义 X 轴标签。break.time.by = 100, # 按 100 天的时间间隔分割 X 轴。ggtheme = theme_light(), # 使用 theme_light() 函数定制绘图和风险表的主题。risk.table.y.text.col = T, # 颜色风险表文本注释。risk.table.height = 0.25, # 风险表的高度。risk.table.y.text = FALSE, # 在风险表的文本注释中显示条形图而不是名称。ncensor.plot = TRUE, # 绘制时间 t 处被截尾的观察数。ncensor.plot.height = 0.25, # 截尾观察数的高度。conf.int.style = "step", # 自定义置信区间的样式。surv.median.line = "hv", # 添加中位生存指针。legend.labs =c("男性", "女性") # 更改图例标签。
)
ggsurv
这段代码调用了
ggsurvplot()函数来创建一个生存曲线图,并将结果存储在名为ggsurv的变量中,然后打印出这个生存曲线图。
ncensor.plot = TRUE:绘制时间 t 处被截尾的观察数。ncensor.plot.height = 0.25:截尾观察数的高度。conf.int.style = "step":自定义置信区间的样式为 "step"。surv.median.line = "hv":添加中位生存指针,指定其样式为水平垂直线。legend.labs = c("男性", "女性"):更改图例标签为 "男性" 和 "女性"。
这篇关于【R语言】生存分析模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








