本文主要是介绍Postgresql源码(128)深入分析JIT中的函数内联llvm_inline,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
相关
《Postgresql源码(127)投影ExecProject的表达式执行分析》
《LLVM的ThinLTO编译优化技术在Postgresql中的应用》
《LLVM(5)ORC实例分析》
1 JIT优化效果
create table t1(i int primary key, j int, k int);
insert into t1 select i, i % 10, i % 100 from generate_series(1,10000000) t(i);set jit_optimize_above_cost to -1;
set jit_above_cost to 0;
set jit_inline_above_cost to 0;
set jit_tuple_deforming to off;
-- jit_inline_above_cost depend on jit_expressions
set jit_expressions to on;explain analyze select abs(k),abs(k),abs(k),abs(k),abs(k),exp(k),exp(k),exp(k),exp(k),exp(k) from t1;关JIT:9.3秒
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------Seq Scan on t1 (cost=0.00..529063.31 rows=10000175 width=60) (actual time=0.039..8863.584 rows=10000000 loops=1)Planning Time: 0.081 msExecution Time: 9343.666 ms开JIT:5.9秒
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------Seq Scan on t1 (cost=0.00..529063.31 rows=10000175 width=60) (actual time=12.100..5460.438 rows=10000000 loops=1)Planning Time: 0.081 msJIT:Functions: 1Options: Inlining true, Optimization false, Expressions true, Deforming falseTiming: Generation 0.389 ms, Inlining 5.567 ms, Optimization 1.188 ms, Emission 5.301 ms, Total 12.445 msExecution Time: 5921.711 ms
(7 rows)
2 PERF STAT观测区别
JIT执行5次:29秒
4.32 msec task-clock # 0.000 CPUs utilized 13 context-switches # 3.008 K/sec 2 cpu-migrations # 462.821 /sec 282 page-faults # 65.258 K/sec 10,763,253 cycles # 2.491 GHz (31.94%)9,573,998 instructions # 0.89 insn per cycle (55.08%)1,833,970 branches # 424.400 M/sec (75.93%)54,410 branch-misses # 2.97% of all branches (66.02%)3,067,449 L1-dcache-loads # 709.840 M/sec (24.07%)69,671 L1-dcache-load-misses # 2.27% of all L1-dcache accesses (33.98%)54,139 LLC-loads # 12.528 M/sec (17.49%)22,209 LLC-load-misses # 41.02% of all L1-icache accesses (17.49%)29.740983598 seconds time elapsed0.001851000 seconds user0.002641000 seconds sys
NO JIT执行5次:46秒
Performance counter stats for '/data/pg16/pghome/bin/psql -p 1101 -h127.0.0.1 -U pg16 postgres -f nj.sql':3.92 msec task-clock # 0.000 CPUs utilized 13 context-switches # 3.319 K/sec 2 cpu-migrations # 510.542 /sec 282 page-faults # 71.986 K/sec 9,896,281 cycles # 2.526 GHz (35.98%)8,902,749 instructions # 0.90 insn per cycle (61.50%)1,719,940 branches # 439.050 M/sec (79.78%)51,247 branch-misses # 2.98% of all branches (70.28%)1,976,835 L1-dcache-loads # 504.628 M/sec (20.22%)75,055 L1-dcache-load-misses # 3.80% of all L1-dcache accesses (29.72%)52,070 LLC-loads # 13.292 M/sec (17.30%)29,130 LLC-load-misses # 55.94% of all L1-icache accesses (17.30%)46.686925078 seconds time elapsed0.002121000 seconds user0.001970000 seconds sys
对比

指标含义
| 事件 | no jit | jit | 分析 |
|---|---|---|---|
| task-clock | 3.92 | 4.32 | 执行程序的CPU时间 |
| context-switches | 13 | 13 | 上下文切换次数,相同 |
| cpu-migrations | 2 | 2 | CPU迁移次数,相同 |
| page-faults | 282 | 282 | 内存缺页,相同 |
| cycles | 9,896,281 | 10,763,253 | CPU花费的周期 |
| instructions | 8,902,749(0.90 insn per cycle) | 9,573,998(0.89 insn per cycle | 这段时间内完成的CPU指令,每个指令都包含多个步骤,每个步骤由CPU的一个叫做功能单元组件处理,每个步骤至少花费一个cycle周期。insn per cycle表示一个CPU周期内完成几个指令,越高越好,这里没有太大差距。 |
| branches | 1,719,940 | 1,833,970 | 分支预测的次数 |
| branch-misses | 51,247 | 54,410 | 分支预测失败的次数 |
| L1-dcache-loads | 1,976,835 | 3,067,449 | 一级数据缓存读取次数,差距非常大 |
| L1-dcache-load-misses | 75,055 | 69,671 | 一级数据缓存读取失败次数 |
| LLC-loads | 52,070 | 54,139 | last level cache读取次数 |
| LLC-load-misses | 29,130 | 22,209 | last level cache读取失败次数,最后一级缓存未命中 |
| 总执行时间 | 46.686925078 | 29.740983598 |
差距的原因比较多,内联和优化会有较大的影响:
- 内存访问模式的改变:LLVM优化可能改变了数据的访问模式,使得数据访问更加局部化。这可以提高缓存的命中率,因为数据更有可能在缓存中被找到。
- 循环优化:LLVM可能进行了循环展开(loop unrolling)或循环融合(loop fusion)等优化,这些优化可以减少循环开销和提高迭代中数据的重用。
- 数据预取:LLVM可能插入了数据预取指令,这些指令可以在数据被访问之前就将其加载到缓存中,从而减少缓存未命中。
- 数据对齐和填充:LLVM可能改变了数据结构的对齐方式,或者添加了填充,以减少缓存行冲突和提高缓存利用率。
- 死码消除和代码简化:LLVM的优化可能移除了不必要的代码和变量,这样可以减少对内存的需求,从而减少L1缓存的加载操作。
- 内联和函数优化:通过函数内联,LLVM可以减少函数调用的开销,并可能进一步优化局部变量的使用,这样也可能减少对L1缓存的访问。
- 变量生命周期的管理:LLVM优化可能改变了变量的生命周期,使得变量在使用时更集中,这样可以提高缓存的命中率。
3 llvm_inline执行流程分析
上面给的用例函数的编译执行是在投影列中的(无JIT投影列执行可以参考这篇《Postgresql源码(127)投影ExecProject的表达式执行分析》)。
LLVM的执行计划,投影列的计算会进入LLVM堆栈:
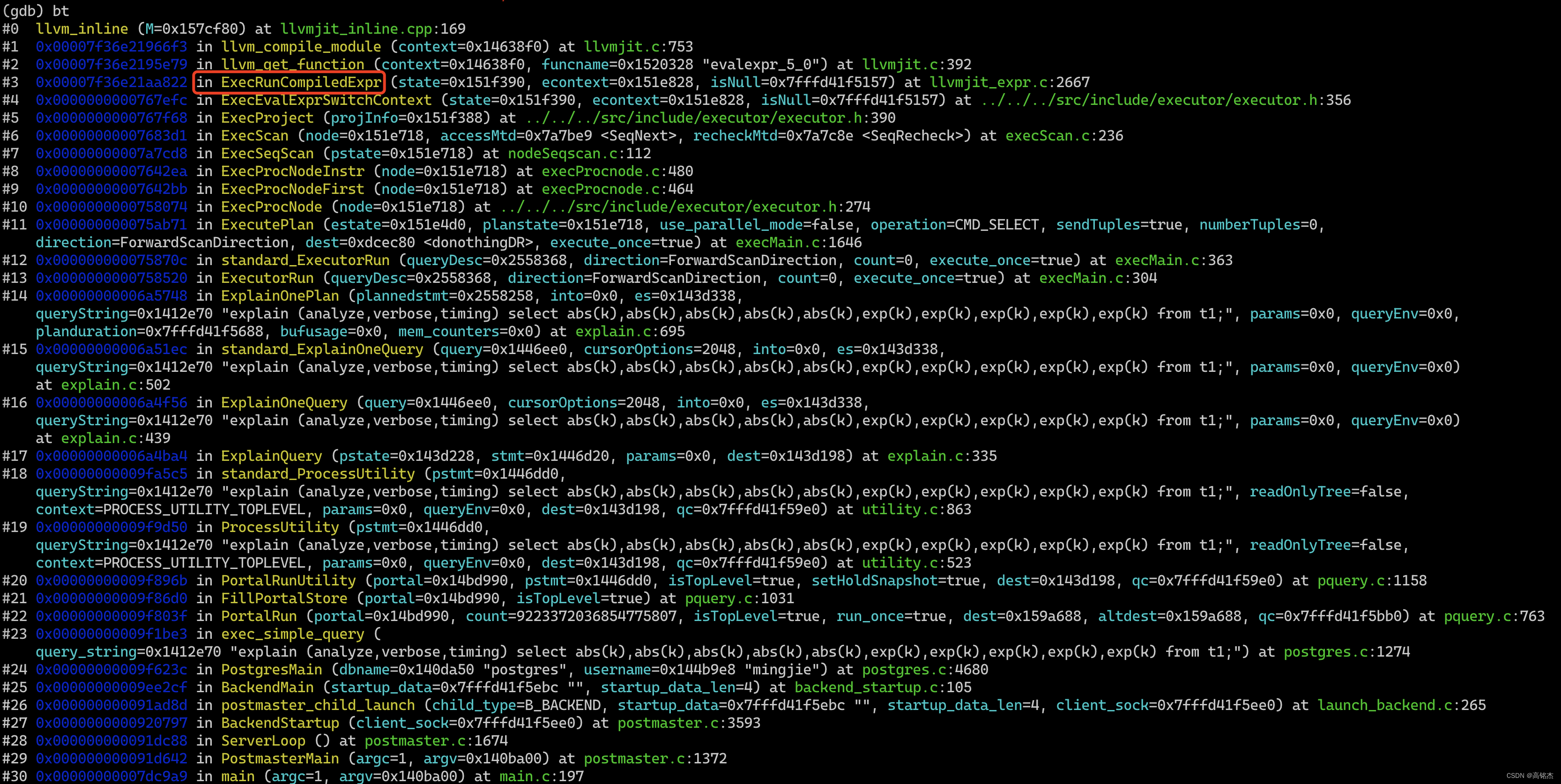
static Datum
ExecRunCompiledExpr(ExprState *state, ExprContext *econtext, bool *isNull)
{CompiledExprState *cstate = state->evalfunc_private;ExprStateEvalFunc func;CheckExprStillValid(state, econtext);llvm_enter_fatal_on_oom();func = (ExprStateEvalFunc) llvm_get_function(cstate->context,cstate->funcname);llvm_leave_fatal_on_oom();Assert(func);/* remove indirection via this function for future calls */state->evalfunc = func;return func(state, econtext, isNull);
}
llvm的总入口是llvm_get_function,llvm_get_function→llvm_compile_module→llvm_inline。
下面重点分析inline的过程:
static void
llvm_compile_module(LLVMJitContext *context)
{...if (context->base.flags & PGJIT_INLINE){...llvm_inline(context->module);...}...
3.1 llvm_inline入参
llvm_inline(context->module);
(gdb) p *context
$2 = {base = {flags = 13, resowner = 0x144d320, instr = {created_functions = 1, generation_counter = {ticks = 315193}, deform_counter = {ticks = 0}, inlining_counter = {ticks = 0},optimization_counter = {ticks = 0}, emission_counter = {ticks = 0}}}, module_generation = 5, llvm_context = 0x0, module = 0x157cf80, compiled = false, counter = 1, handles = 0x0}
module的含义:《LLVM(5)ORC实例分析》

3.2 module在哪里初始化?
llvm_mutable_module创建一个名称为pg的空module:
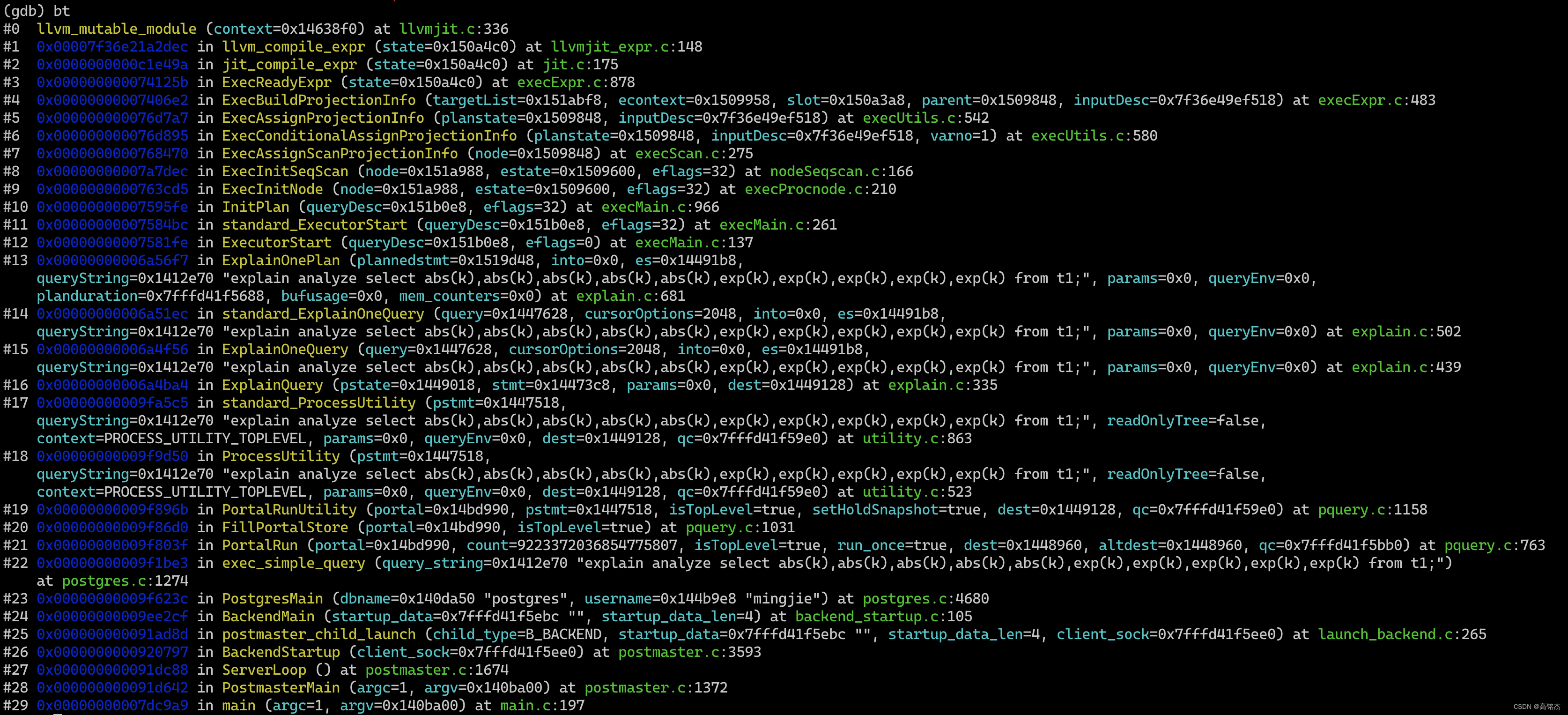
LLVMModuleRef
llvm_mutable_module(LLVMJitContext *context)
{llvm_assert_in_fatal_section();/** If there's no in-progress module, create a new one.*/if (!context->module){context->compiled = false;context->module_generation = llvm_generation++;context->module = LLVMModuleCreateWithNameInContext("pg", llvm_context);LLVMSetTarget(context->module, llvm_triple);LLVMSetDataLayout(context->module, llvm_layout);}return context->module;
}
然后再llvm_compile_expr中构造表达式计算函数,加到module里面:
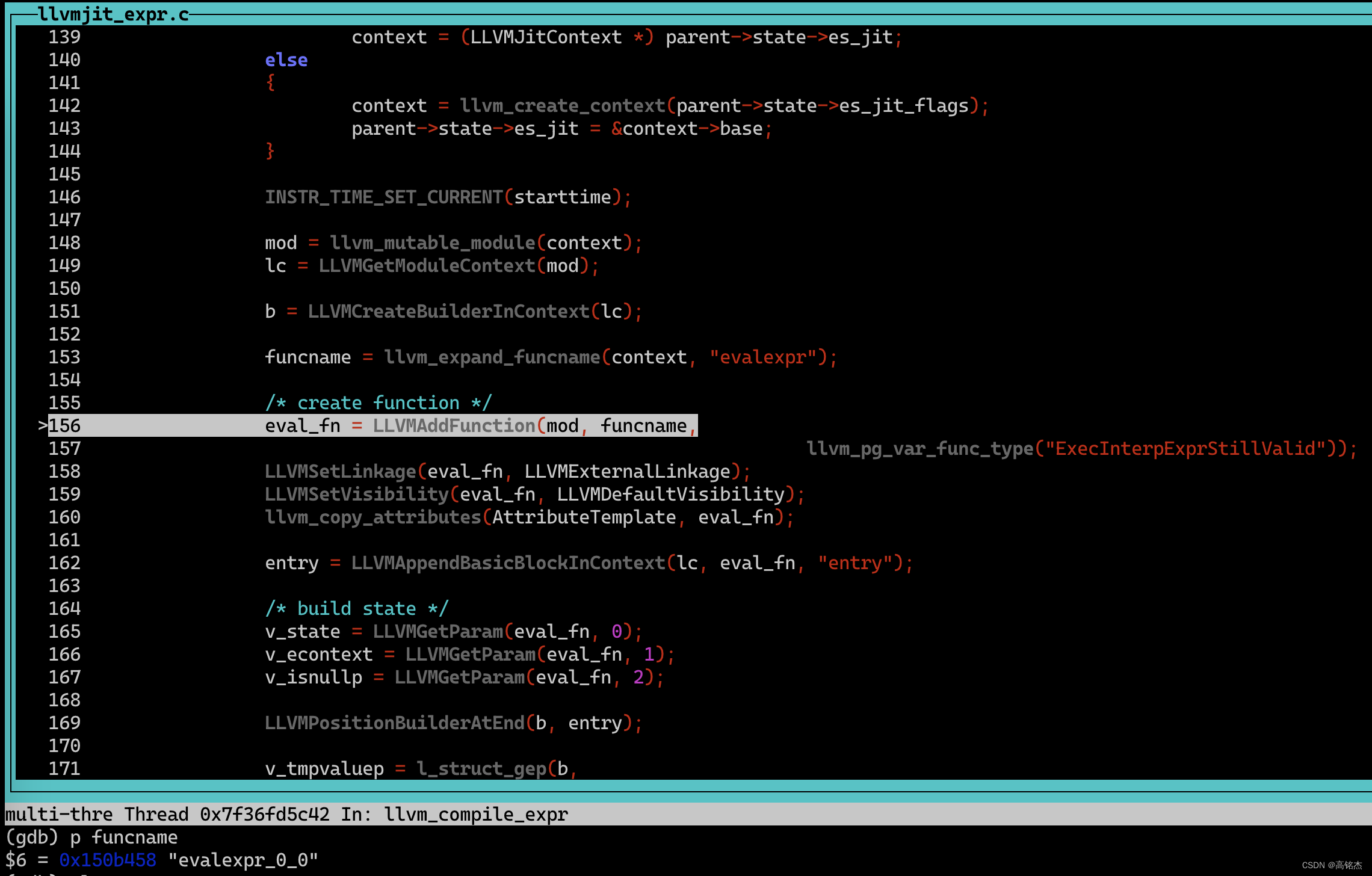
注意这里通过LLVMAddFunction会把表达式计算用到的函数都加进去(只加用到的)。
本例中:
explain analyze select abs(k),abs(k),abs(k),abs(k),abs(k),exp(k),exp(k),exp(k),exp(k),exp(k) from t1;
| llvm_compile_expr函数中LLVMAddFunction | LLVMAddFunction位置 |
|---|---|
| evalexpr_0_0 | llvm_compile_expr |
| slot_getsomeattrs_int | llvm_compile_expr case EEOP_SCAN_FETCHSOME |
| int4abs | llvm_compile_expr case EEOP_FUNCEXPR_STRICT |
| llvm.lifetime.end.p0i8 | llvm_compile_expr case EEOP_FUNCEXPR_STRICT |
| i4tod | llvm_compile_expr case EEOP_FUNCEXPR_STRICT |
| dexp | llvm_compile_expr case EEOP_FUNCEXPR_STRICT |
只有上面5个函数被加到module了,所以后面inline只需要考虑这后四个个函数就好了,第一个是表达式计算入口。
3.3 llvm_inline
void
llvm_inline(LLVMModuleRef M)
{LLVMContextRef lc = LLVMGetModuleContext(M);// ? 下面有解释llvm::Module *mod = llvm::unwrap(M);
- llvm::unwrap 是一个辅助函数,用于将 C 语言风格的接口转换为 C++ 风格的接口。M是一个来自 LLVM C API 的类型(LLVMModuleRef),这是一个指向 LLVM 模块的指针,但它被封装为一个不透明的指针类型以便在 C 环境中使用。llvm::unwrap 函数将这个不透明的指针转换为一个指向 llvm::Module 的指针,这样就可以在 C++ 代码中使用 LLVM 的 C++ API 来操作这个模块了。
- (llvm::module 是 LLVM 中的一个类,它代表了一个完整的 LLVM IR模块,这个模块可以包含函数、全局变量、符号等。在 LLVM 的 C++ API 中可以直接使用 llvm::Module 类型的对象)
std::unique_ptr<ImportMapTy> globalsToInline = llvm_build_inline_plan(lc, mod);if (!globalsToInline)return;llvm_execute_inline_plan(mod, globalsToInline.get());
}
llvm_inline→llvm_build_inline_plan
llvm_build_inline_plan函数返回一个ImportMapTy类型,
static std::unique_ptr<ImportMapTy>
llvm_build_inline_plan(LLVMContextRef lc, llvm::Module *mod)
{std::unique_ptr<ImportMapTy> globalsToInline(new ImportMapTy());FunctionInlineStates functionStates;InlineWorkList worklist;InlineSearchPath defaultSearchPath;
- 注意这里的searchpath是什么,怎么来的请看这篇: 《LLVM的ThinLTO编译优化技术在Postgresql中的应用》
add_module_to_inline_search_path(defaultSearchPath, "$libdir/postgres");...for (const llvm::Function &funcDecl : mod->functions()){InlineWorkListItem item = {};FunctionInlineState inlineState = {};- 只ADD了还没BUILD所以有的函数只有定义,例如
evalexpr_0_0、llvm.lifetime.end.p0i8。 - 其他函数会正常加入worklist,例如
int4abs、dexp。
if (!funcDecl.isDeclaration())continue;...item.symbolName = funcDecl.getName();item.searchpath = defaultSearchPath;worklist.push_back(item);inlineState.costLimit = inline_initial_cost;inlineState.processed = false;inlineState.inlined = false;inlineState.allowReconsidering = false;functionStates[funcDecl.getName()] = inlineState;}
- 本案例中会有四个函数加入worklist:slot_getsomeattrs_int、int4abs、i4tod、dexp
while (!worklist.empty()){InlineWorkListItem item = worklist.pop_back_val();llvm::StringRef symbolName = item.symbolName;char *cmodname;char *cfuncname;FunctionInlineState &inlineState = functionStates[symbolName];llvm::GlobalValue::GUID funcGUID;llvm_split_symbol_name(symbolName.data(), &cmodname, &cfuncname);funcGUID = llvm::GlobalValue::getGUID(cfuncname);for (const auto &gvs : summaries_for_guid(item.searchpath, funcGUID)){
- 从searchpath也就是postgresql.index.bc里面搜索funcGUID,找到modPath。
- 例如
modPath=postgres/utils/adt/float.bc
const llvm::FunctionSummary *fs;llvm::StringRef modPath = gvs->modulePath();llvm::Module *defMod;llvm::Function *funcDef;fs = llvm::cast<llvm::FunctionSummary>(gvs);if ((int) fs->instCount() > inlineState.costLimit){ilog(DEBUG1, "ineligibile to import %s due to early threshold: %u vs %u",symbolName.data(), fs->instCount(), inlineState.costLimit);inlineState.allowReconsidering = true;continue;}
- modPath是函数所在的bc文件路径。
- 在load_module_cached中调用load_module,调用LLVMCreateMemoryBufferWithContentsOfFile、LLVMGetBitcodeModuleInContext2拿到module。
defMod = load_module_cached(lc, modPath);if (defMod->materializeMetadata())elog(FATAL, "failed to materialize metadata");funcDef = defMod->getFunction(cfuncname);
- 到这里,通过thinlto生成的index文件的指引,找到函数所在的bc文件,最后拿到了func的bitcode。
...llvm::StringSet<> importVars;llvm::SmallPtrSet<const llvm::Function *, 8> visitedFunctions;int running_instcount = 0;- 拿到了函数的bitcode后确认是否能inline?
- 能否inline是一系列规则、成本决定的,具体分析在这篇:《Postgresql中JIT函数能否inline的依据function_inlinable》
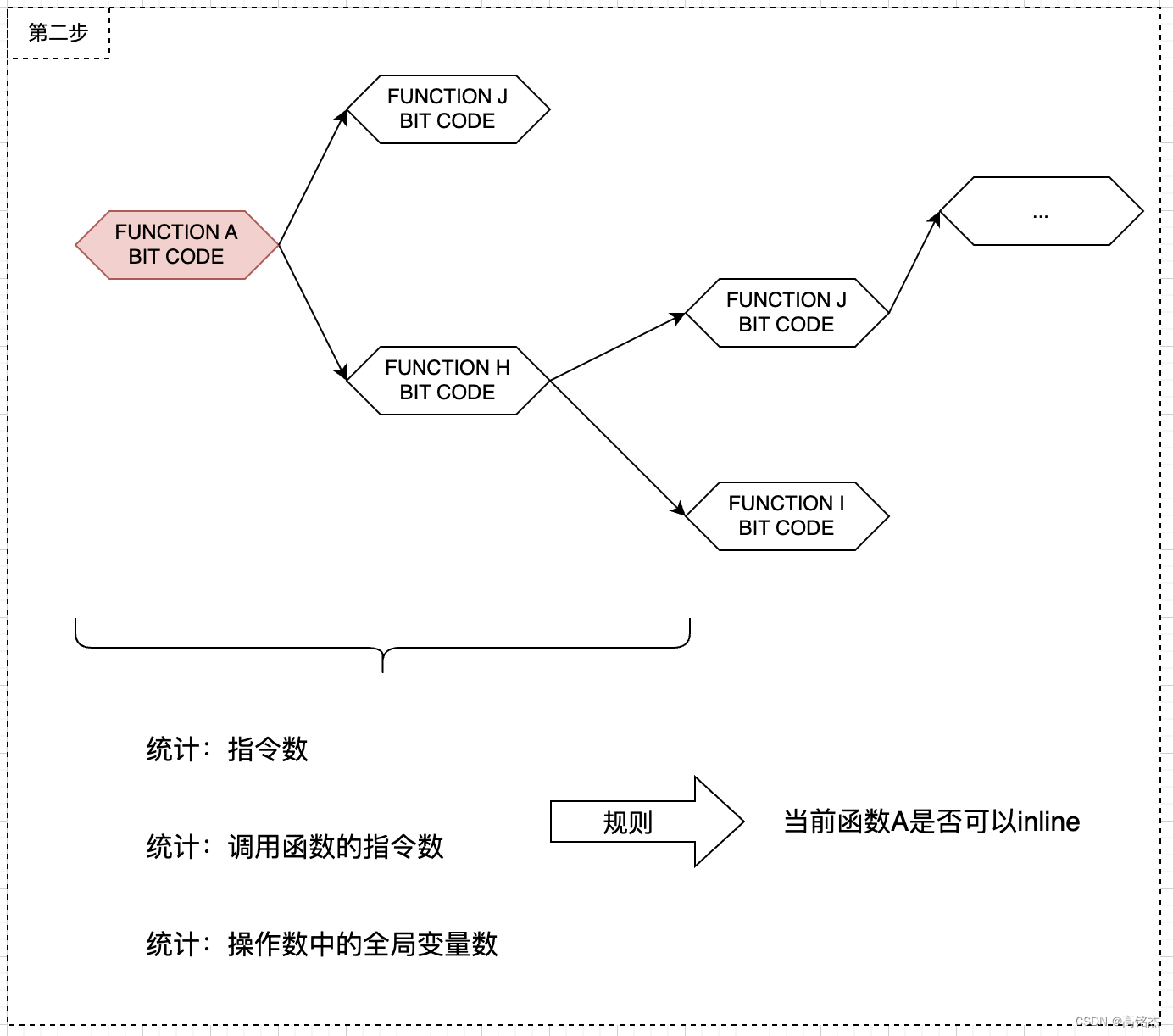
if (function_inlinable(*funcDef,inlineState.costLimit,functionStates,worklist,item.searchpath,visitedFunctions,running_instcount,importVars)){
- 整体指令数不能超过150个,超过就不在inline了,Inline太多会造成代码膨胀。
if (running_instcount > inlineState.costLimit){ilog(DEBUG1, "skipping inlining of %s due to late threshold %d vs %d",symbolName.data(), running_instcount, inlineState.costLimit);inlineState.allowReconsidering = true;continue;}ilog(DEBUG1, "inline top function %s total_instcount: %d, partial: %d",symbolName.data(), running_instcount, fs->instCount());- 这里把当前函数,例如dexp放到数组中。
- function_inlinable中没放吗?因为function_inlinable只把dexp调用到的函数放进去了。
- 把全部需要inline的函数名、全局变量名记录到modGlobalsToInline中。
importVars.insert(symbolName);{llvm::StringSet<> &modGlobalsToInline = (*globalsToInline)[modPath];for (auto& importVar : importVars)modGlobalsToInline.insert(importVar.first());}
- 标记已经Inline
inlineState.inlined = true;break;}else{ilog(DEBUG1, "had to skip inlining %s",symbolName.data());}}- 更新FunctionInlineState。
- 注意:
- functionStates数组存放了所有inline的函数的信息。
- globalsToInline是map结构{modPath, StringSet},根据"postgres/utils/adt/float.bc"找到StringSet,在StringSet中保存了dexp、dexp函数调用到的其他函数、dexp和调用到函数所有使用到的全局变量。
inlineState.processed = true;}return globalsToInline;
}
3.4 llvm_inline→llvm_execute_inline_plan
遍历上述结果集中的函数,配置AvailableExternallyLinkage标记。
static void
llvm_execute_inline_plan(llvm::Module *mod, ImportMapTy *globalsToInline)
{...for (const auto& toInline : *globalsToInline){const llvm::StringRef& modPath = toInline.first();const llvm::StringSet<>& modGlobalsToInline = toInline.second;std::unique_ptr<llvm::Module> importMod(std::move((*module_cache)[modPath]));module_cache->erase(modPath);for (auto &glob: modGlobalsToInline){llvm::StringRef SymbolName = glob.first();llvm::GlobalValue *valueToImport = importMod->getNamedValue(funcname);if (llvm::isa<llvm::Function>(valueToImport)){llvm::Function *F = llvm::dyn_cast<llvm::Function>(valueToImport);typedef llvm::GlobalValue::LinkageTypes LinkageTypes;...if (valueToImport->hasExternalLinkage()){valueToImport->setLinkage(LinkageTypes::AvailableExternallyLinkage);}}}}
}
- 在LLVM中,有几种编译连接类型,默认会使用ExternalLinkage,表示函数在不同的编译单元之间是可见的,可以被其他单元引用。
- 如果主动配置为AvailableExternallyLinkage,直观的理解是 把函数转换成一个全局可用的函数,定义只编译一次, 其他模块不会重复编译当前函数。
GlobalValue.h
class GlobalValue : public Constant {
public:/// An enumeration for the kinds of linkage for global values.enum LinkageTypes {ExternalLinkage = 0,///< Externally visible functionAvailableExternallyLinkage, ///< Available for inspection, not emission.LinkOnceAnyLinkage, ///< Keep one copy of function when linking (inline)LinkOnceODRLinkage, ///< Same, but only replaced by something equivalent.WeakAnyLinkage, ///< Keep one copy of named function when linking (weak)WeakODRLinkage, ///< Same, but only replaced by something equivalent.AppendingLinkage, ///< Special purpose, only applies to global arraysInternalLinkage, ///< Rename collisions when linking (static functions).PrivateLinkage, ///< Like Internal, but omit from symbol table.ExternalWeakLinkage,///< ExternalWeak linkage description.CommonLinkage ///< Tentative definitions.};
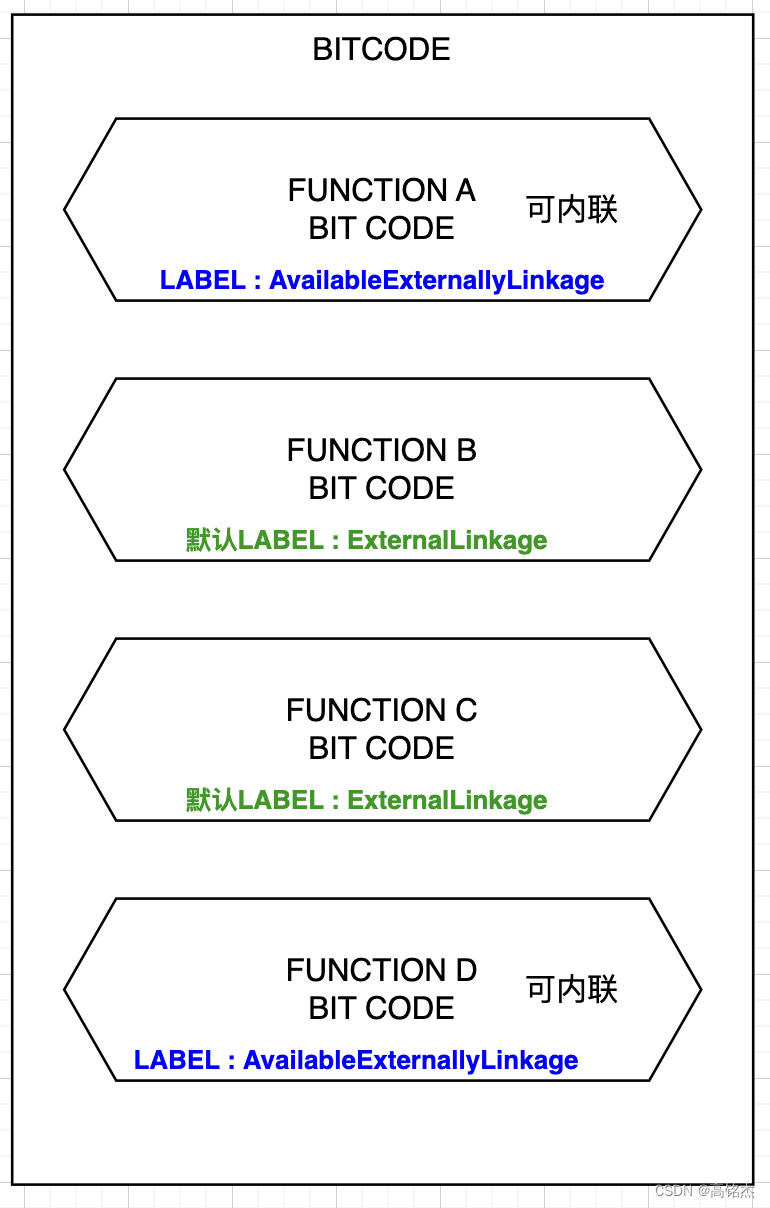
当函数被标记为AvailableExternallyLinkage时,LLVM优化器有可能会内联这些函数。但不是一定会发生,内联决策是llvm内联启发式算法做出的,会考虑很多因素:函数的大小、复杂性、调用频率、调用上下文等等。如果llvm决定内联一个函数,它会将函数的代码直接插入到每个调用点。
从module里面读取一下inline后的IR代码,发现函数已经有了available_externally标记。
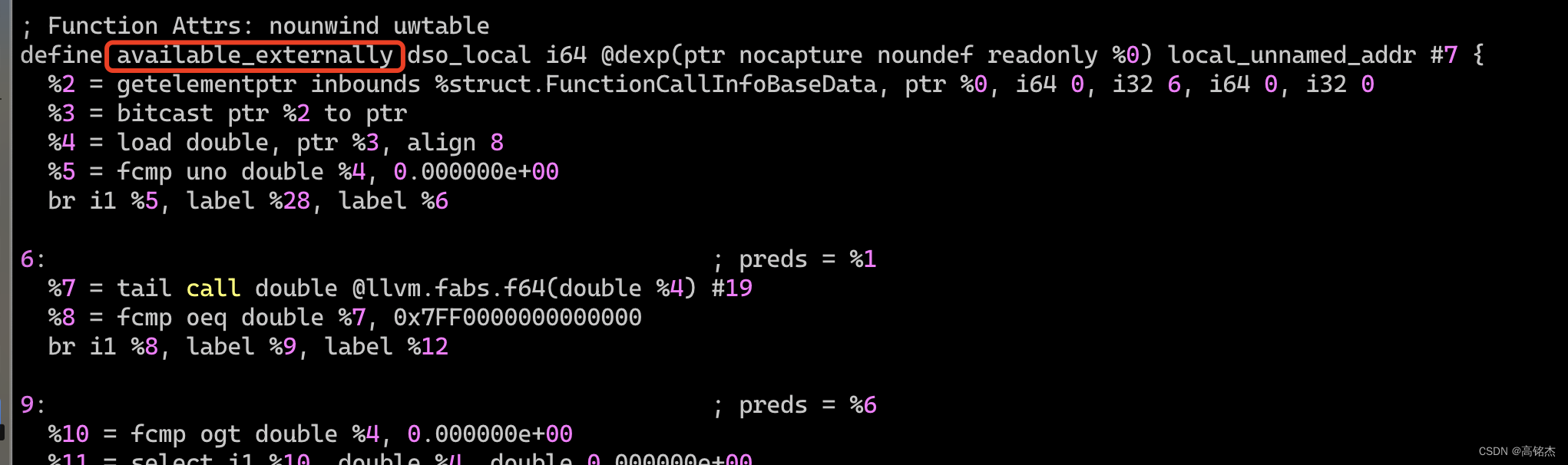
4 内联后的效果
4.1 llvm决定不做内联
例如dexp函数:
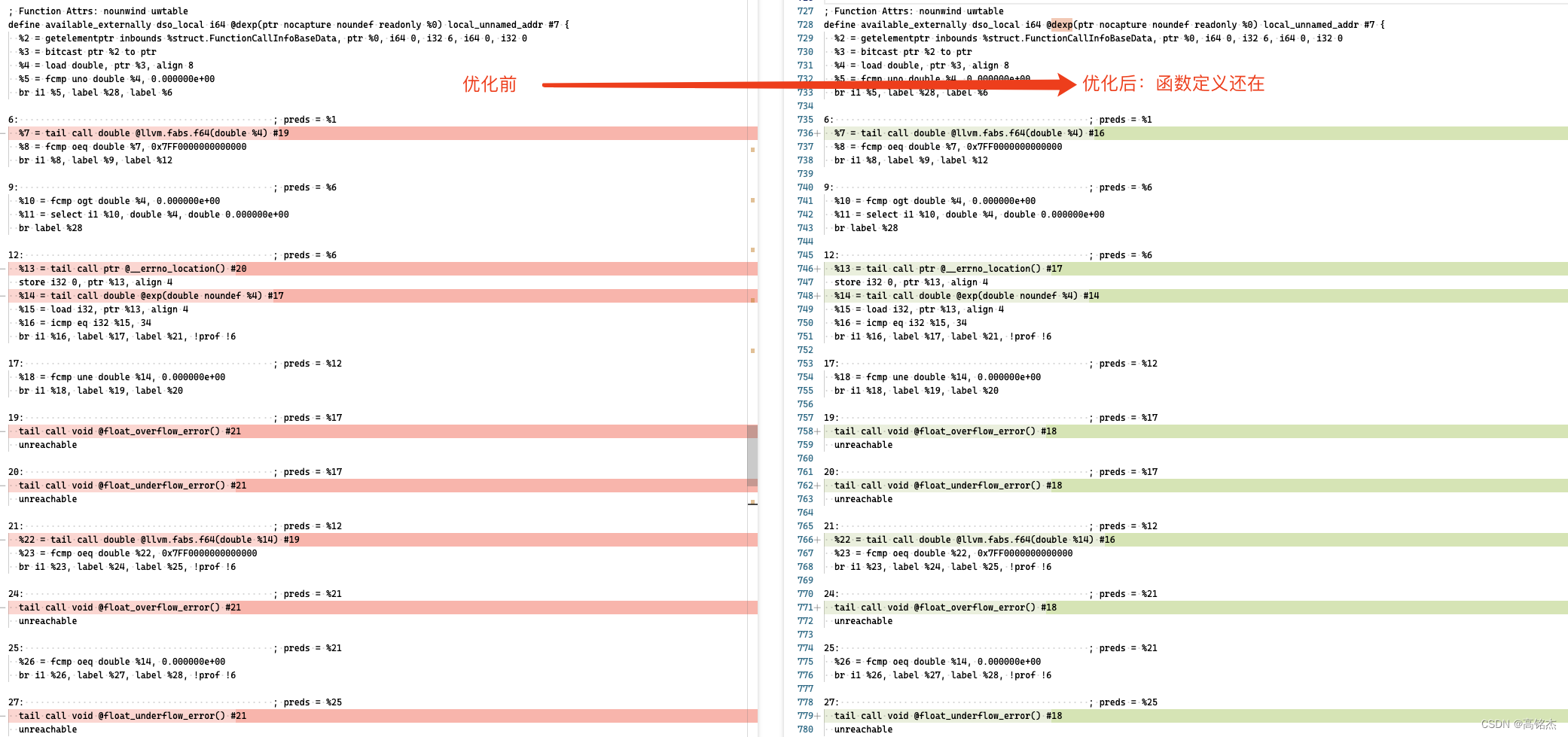
优化后,还是正常调用:

4.2 llvm决定内联

原来调用的位置变成什么了?

(备忘)clang编译PG源码的方式
clang编译生成.bc文件
cd src/backend/utils/adtclang \
-Wno-ignored-attributes -fno-strict-aliasing \
-fwrapv -fexcess-precision=standard \
-Xclang -no-opaque-pointers -Wno-unused-command-line-argument \
-Wno-compound-token-split-by-macro -O2 \
-I. -I. -I../../../../src/include \
-D_GNU_SOURCE -I/usr/include/libxml2 -flto=thin -emit-llvm \
-c -o int8.bc int8.c
生成可读的ll文件:
llvm-dis int8.bc
其他编译相关的在这篇: 《LLVM的ThinLTO编译优化技术在Postgresql中的应用》
这篇关于Postgresql源码(128)深入分析JIT中的函数内联llvm_inline的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






