本文主要是介绍剁手党必看——转转红包使用规则与最优组合计算全解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
-
1、省钱攻略基础之“了解平台红包使用规则”
-
2、举个栗子
-
3、最优红包组合计算方法进化过程
-
3.1、初代“笛卡尔乘积”版
-
3.2、二代“边算边比较Map聚合”版
-
3.3、三代“边算边比较数组索引定位”版
-
-
4、总结
1、省钱攻略基础之“了解平台红包使用规则”
规则一:红包大类别分为“商品红包”、“叠加券”、“邮费红包”三种。
规则二:每个SKU(同一个商品ID),商品红包、叠加券、邮费红包最多每种使用一张。
规则三:商品红包和叠加券都有可能设定使用门槛金额,门槛金额是商品促销优惠后金额(如果有促销),邮费红包使用门槛基于商品红包和叠加券优惠后金额计算。
规则四:门槛金额高的红包优惠不一定高于门槛低的(虽然大概率如此)。
规则五:绝大多数红包都有使用限制条件,与商品相关的:分类、归属的业务、卖家、包含的服务、特定的商品范围、商品发布时间;与场景相关:终端类型、卖场;与买卖家相关:是否是“新客户”、买卖家是否被风控等等。
规则六:商品红包和叠加券小类分为:满额减和满额折,其中满额折红包又有最大优惠金额如满10元8.8折最多优惠1000元,此时如果商品10000元最多也只能减1000元;邮费红包分为定额红包和免邮红包。
2、举个栗子
在开始计算最大优惠前,我们先举个例子具象化实际场景,此处忽略“规则五”计算过程,直接给出符合红包使用限制的商品与红包关系;由于邮费红包门槛金额基于商品红包和叠加券后金额较为复杂,且不影响最优红包解题思路,此处忽略邮费红包,仅以商品红包为例。
场景如下:
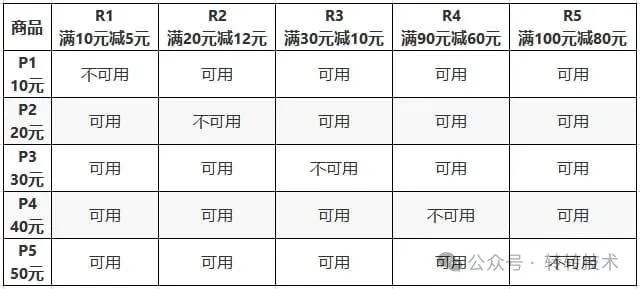
5个商品分别为:P1=10元、P2=20元、P3=30元、P4=40元、P5=50元。
5个商品红包:R1=满10元减5元、R2=满20元减12元、R3=满30元减10元、R4=满90元减60元、R5=满100元减80元。商品与红包的关系如下表格:
3、最优红包组合计算方法进化过程
3.1、初代“笛卡尔乘积”版
首先,将每个红包的可用商品聚合:
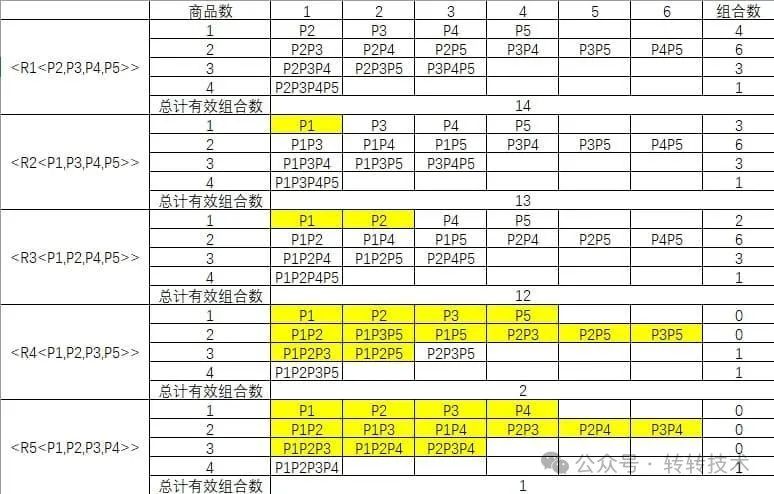
R1->P2、P3、P4、P5 R2->P1、P3、P4、P5 R3->P1、P2、P4、P5 R4->P1、P2、P3、P5 R5->P1、P2、P3、P4
将每个红包的可用商品进行排列组合得到下表(黄色为该组合不符合红包门槛):
将上表改写成矩阵:

计算纵列笛卡尔积:

计算各组合红包的优惠情况,按红包优惠金额倒序,取红包最大优惠组合情况, 得到:P5商品使用R2;P1P2P3P4使用R5,得到最大优惠金额80+12=92元。
该版本核心思想:计算出所有商品使用红包的组合情况,并行计算各组合的优惠金额,按优惠金额倒序取最大优惠。存在的问题:商品和红包数量增加时组合数呈指数级增长,计算笛卡尔积时很容易OOM。
3.2、二代“边算边比较Map聚合”版
一代算法最大的问题是将所有组合全部排列好后再进行价格计算和比较,导致内存占用过大;二代算法核心思想是“边排列组合边计算边比较”保留最优解,计算耗时到达规定阈值时停止,取已算组合中的最优。这一代算法中,用到了HashMap作为记录商品使用红包的标记指针,数据结构如下:
//用于记录每个商品上,各大类可用红包的列表
private Map<ERedMetaBigType, List<RedBaseInfoInput>> prodRed = Maps.newHashMap();//用于记录该商品在各大类红包列表List<RedBaseInfoInput>上使用红包的列表index位置private Map<ERedMetaBigType, Integer> pointer = Maps.newHashMap();
指针移动抽象示例(黄色为此轮组合指针位置):
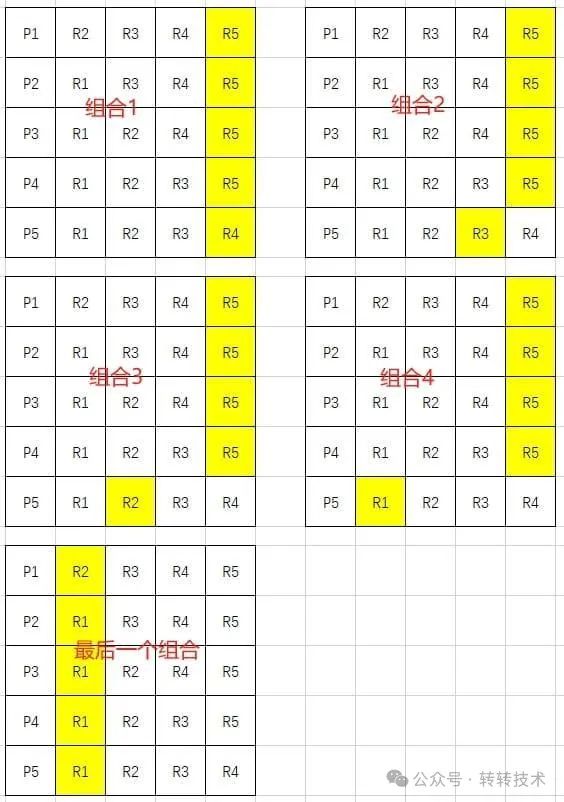
移动一次指针就形成一个新的组合,根据根据标记将使用相同红包的商品“聚合” 如组合2:R5<P1,P2,P3,P4> R3
//使用Map结构记录
Map<ERedMetaBigType, Map<Long, List<EngineInput>>> oneType2RedId2Prods = Maps.newEnumMap(ERedMetaBigType.class);优点:不需要将所有组合都排列出后再计算比较,超过规定时间可以中断降级处理。缺点:每次移动指针后,都需要使用Map结构将红包商品重新“聚合”后才能计算红包门槛和优惠,频繁生产销毁Map和List对象,GC压力大。
3.3、三代“边算边比较数组索引定位”版
三代主要通过数据结构与虚拟逻辑关系,减少上一代算法大量生成中间临时Map导致GC压力大问题。使用数组Long[] infoArray存储商品列表,此时infoArray数组下标就含有了商品ID的含义,同理,Long[] redArray存储红包列表,redArray数组下标就含有了红包ID的含义。使用byte[][] infoRedRel二维数组用于存储商品红包关系,数组值0表示此轮计算未使用,1表示此轮计算使用,-1表示该商品不可使用此红包。关系数组如下:
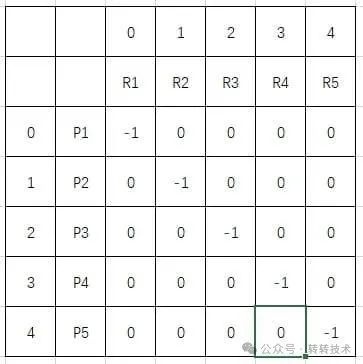
拥有这个二维数组后,就可以通过修改这个位数数组的值(不包含-1不可用的),实现红包使用组合的变更。
此时聚合商品不再需要使用Map生成新的结构存储,只需要遍历红包列表数组,根据数组下标去infoRedRel维数组中获取数组值,然后去infoArray取商品即可。
4、总结
本文简述了最优红包组合的整体演进,下表是二代和三代在不同红包总量、商品数量、商品可用红包数量时,200ms完成计算组合数的情况对比(30次均值)如下图:

通过二代三代的对比,我们不难发现,在面对大量计算时除了要注意JVM内存使用情况外(一代FullGC或溢出),还需要关注对象生成销毁的数量与频率,因为在面临大量计算时对象生成和GC也将成为性能瓶颈,三代相较二代,完成计算的组合数在5倍以上,这其间的差距都是因为二代Map对象的生成和销毁。
关于作者
马宝山, 转转交易中台Java开发工程师
这篇关于剁手党必看——转转红包使用规则与最优组合计算全解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








