本文主要是介绍mysql的数据结构及索引使用情形,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
先来说下数据的一般存储方式:内存(适合小数据量)、磁盘(大数据量)。
磁盘的运转方式:速度 + 旋转,磁盘页的概念:每一页大概16KB。
1、存储结构
哈希
是通过hash函数计算出一个hash值的,哈希的优点就是查找的时间复杂度是O(1),哈希不支持部分索引查询以及范围查找。
红黑树
存储的数据量大的时候,红黑树的节点层数多,也就是树的高度比较高,查找的底层数据时,查找次数就比较多,即对磁盘IO使用比较频繁。总结为以下两点:
- 读取浪费太多:通过计算本来树的每一层大概需要分配16KB的数据,但是对于红黑树来说,实际存的节点数比较少,即存的数据大小远远小于16KB,从而造成存储空间的浪费
- 读取磁盘的次数过多:树的层数越多,查找数据时读取磁盘的次数也就越多
如下图所示,如果需要查找数字4的话,需要查找三次,即对磁盘IO操作三次:

针对红黑树以上总结的两点,我们可以从以下两点出发:
- 增加树每层的节点数量,这样可以对分配的16KB充分利用,即解决上面的读取浪费的问题
- 尽可能的让树的高度减小,使得树显得比较“矮胖”,这样可以减少读取磁盘的次数
那么怎么样才可以实现以上的方法呢?这就需要用到B+树了,实际上MySql的底层数据结构就是用的B+树。
BTree
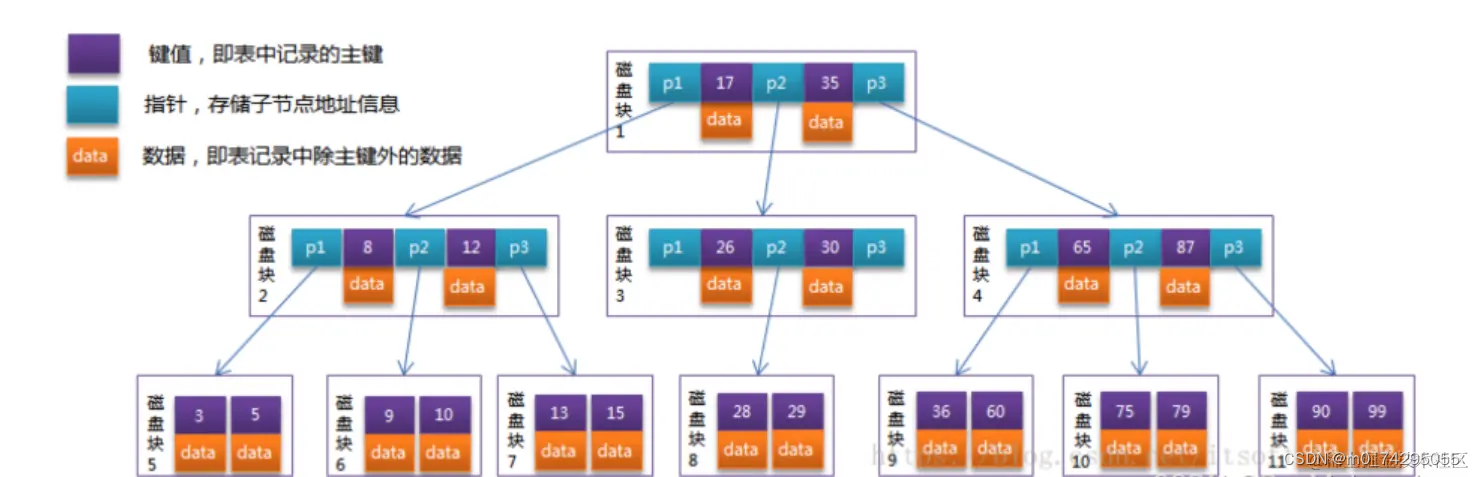
BTree的问题有以下这几点:
- 因为BTree不适合范围查找。就拿上面的来举例,比如我要查找小于6的数据,则先找到6的节点,然后需要遍历一遍6节点(索引)的左子树,不遍历的话,就拿不到小于6的这些数据了,也就说索引失效了,所以说不适合范围查找。
- BTree的节点除了存储索引之外,还存储了数据本身,占用空间较大,但是磁盘的页大小是有限的(16KB左右),因此,存储同样大小的数据,BTree显得比较高(相对B+Tree),稳定性弱一些。
综上两个主要原因,MySql最终选择了B+Tree的数据结构来存储数据。
B+Tree
B+Tree和BTree的分裂过程类似,只是B+Tree的非叶子节点不会存储数据,只存储索引值(指针地址),所有的数据都是存储在叶子节点,如下图所示:

由上图可以看出B+Tree有以下几个特点:
- 叶子节点连起来了,是一条有序的双向链表,目的是为了解决范围查找。比如需要查找小于9的数据,只要找到等于9的数据,然后将9的左边数据全部拿出来即可。
- 非叶子节点不存数据,只存索引,空间利用更高效。
- 数据的个数和节点一样多,换句话说,非叶子节点存的是其子树的最大或最小值。
2、索引
2.1、索引功能类型
主键索引:一张表只能有一个主键索引,不允许重复、不允许为 NULL;
唯一索引:数据列不允许重复,允许为 NULL 值,一张表可有多个唯一索引,索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
普通索引:一张表可以创建多个普通索引,一个普通索引可以包含多个字段,允许数据重复,允许 NULL 值插入;
全文索引:它查找的是文本中的关键词,主要用于全文检索。
2.2、索引物理类型
聚簇索引(clustered index):聚簇索引也可理解为将数据存储与索引放到了一块,找到索引也就找到了数据。
非聚簇索引:数据和索引是分开的,B+树叶子节点存放的不是数据表的行记录。
虽然InnoDB和MyISAM存储引擎都默认使用B+树结构存储索引,但是只有InnoDB的主键索引才是聚簇索引,InnoDB中的辅助索引以及MyISAM使用的都是非聚簇索引。每张表最多只能拥有一个聚簇索引。
2.3、索引使用的不同情形
回表
若有student表如下
id(主键) name age
1 路飞 18
2 索隆 20
我们对id建立索引,然后再对name建立索引。那么当我们执行select * from student where name=?时
由于索引底层数据结构的B+Tree,对name列建立的索引为非聚簇索引,这个索引存储的是id
那么我们执行完SQL时,会从name的B+Tree中拿到id,再回到id的B+Tree中去搜索所对应的数据,这个过程就叫做回表
索引覆盖
还是,假设有一条语句
select id from student where name=?
此时,就不会再去再去id的对应索引的那颗B+Tree上再去搜索一遍了,这就是索引覆盖
最左匹配原则
一帮情况下和组合索引一起使用,例如吧name,age共同建立索引(name,age),假设现在有下面四条sql语句
select * from student where name=? and age=?
select * from student where name=?
select * from student where age=?
select * from student where age=? and name=?
现在问题来了,那个会走组合索引(name,age)?
答案是1,2,4,而3会进行全表扫描,看下图
听名知意,就是最左边开始匹配呗,也就是先匹配name,再来age。虽然2只有name,但是也会走索引。
你可能的疑惑就是4为啥会走索引,其实mysql中有个叫做优化器的东西,他会对这个age和name的顺序进行优化。这样就可以走索引了
优化器简单的说一下,有两种:CBO(基于成本的优化),RBO(基于规则的优化)MySQL默认用的是CBO。
索引下推
数据是存储在磁盘的、MySQL有自己的服务,MySQL服务要跟磁盘发生交互。这样能从磁盘拿到数据
没有索引下推时:
存储引擎先从磁盘中筛选出name符合条件的数据,全部取出,MySQL server再根据age条件筛选一次。这样就得到了符合条件的值。
这样会有大量的IO操作,所以浪费时间和资源
有存索引下推时:
存储引擎先从磁盘中直接筛选出name,age同时都符合条件的数据,不需要server再去做任何的数据筛选
索引下推需要在磁盘上进行数据筛选,原来的筛选是在内存中进行,现在放到了磁盘上进行查找数据的环节,但是,虽然这样看起来成本更高了,可别忘了,索引数据是排序的,所有数据是聚集存放的,所以性能并不会有影响,而且还会减少IO次数,反而会提升性能
参考文献:
一文吃透MySql的底层数据结构(满满都是干货) - 掘金 (juejin.cn)
https://www.zhihu.com/question/26398102
https://blog.csdn.net/wangfeijiu/article/details/113409719
MySQL索引:回表、索引覆盖,最左匹配原则、索引下推_回表底层索引数据结构-CSDN博客
这篇关于mysql的数据结构及索引使用情形的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





