本文主要是介绍【计组OS】访存过程以及存储层次化结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

苏泽
本专栏纯个人笔记作用 用于记录408 学习的笔记记录(敲了两年码实在不习惯手写笔记了)
如果能帮助到大家当然最好
但由于是工作后退下来备考 很多说法和想法都会结合实际开发的思想 可能不是那么的纯粹应试哈
希望大家挑选自己喜欢的口味食用 仅供参考
首先捋清楚 存储体系的层次化结构 我把知识整理成了这样的一张图
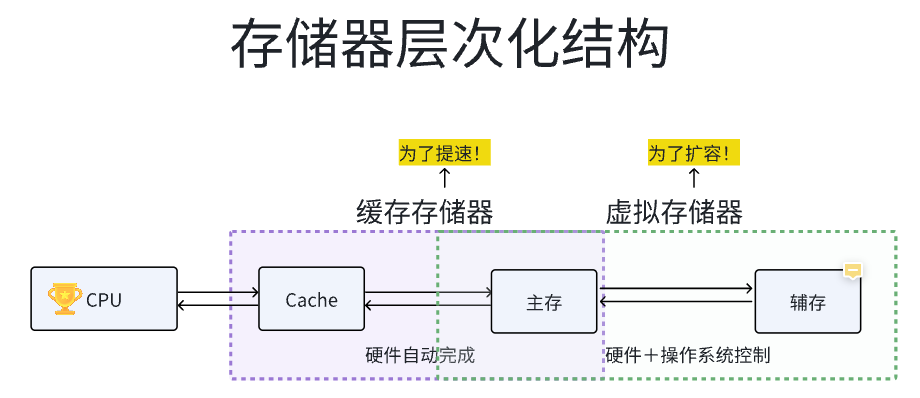
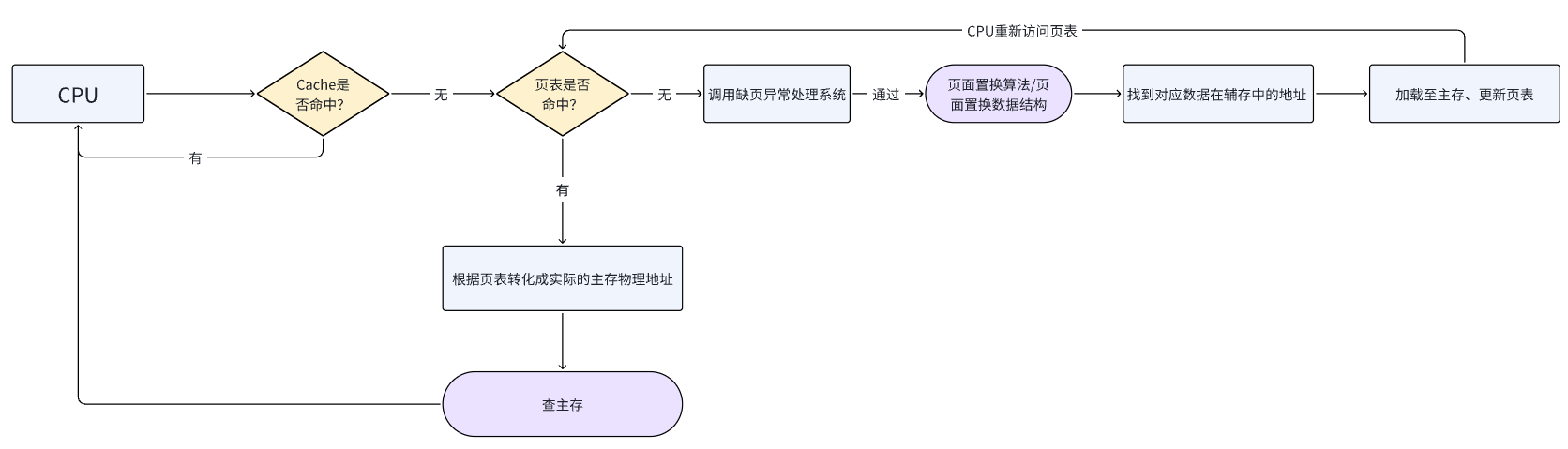
那么我们就能很清晰的在这张图上面理解到CPU在访问存储数据的过程
-
Cache 访问:
- CPU尝试从Cache中获取所需的数据。
- 如果Cache命中(Cache Hit),则直接从Cache中读取数据,完成访存操作。
-
TLB 查询:
- 如果Cache未命中(Cache Miss),CPU接下来会检查TLB(Translation Lookaside Buffer)。
- TLB是一种特殊的存储器,用于快速地址转换,存储最近访问的页表条目。
- 如果TLB命中(TLB Hit),则使用TLB中的信息完成地址转换。
-
页表查询:
- 如果TLB未命中(TLB Miss),CPU将访问页表进行地址转换。
- 页表存储逻辑地址到物理地址的映射关系。
- 操作系统维护页表,其中包含有效位,指示对应的页面是否在物理内存中。
-
有效位检查:
- 在页表中找到对应的页表项后,CPU检查该项的有效位。
- 如果有效位为1,表示数据在主存中,CPU可以继续访问主存以获取数据。
-
缺页异常处理:
- 如果有效位为0,表示数据不在主存中,即发生了缺页异常(Page Fault)。
- 缺页异常处理程序被调用,操作系统开始处理这一异常。
-
辅存访问:
- 操作系统确定辅存中数据的位置,通常通过页面置换算法的数据结构来选择一个页面进行置换。
-
数据加载与页表更新:
- 操作系统从辅存中加载缺失的数据到主存。
- 加载完成后,操作系统更新页表,将新的物理地址映射到原来的逻辑地址。
-
重新尝试访问:
- 页表更新后,操作系统会重新执行导致缺页异常的指令。
- CPU再次尝试访问数据,这次数据应该已经在主存中,可以成功访问。
-
继续执行程序:
- 一旦数据被加载到主存并且页表被更新,CPU可以继续执行程序,就像没有发生缺页异常一样。
这篇关于【计组OS】访存过程以及存储层次化结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





