本文主要是介绍#####好好好##### 双端 LSTM 实现序列标注(分词),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
@author: huangyongye
@creat_date: 2017-04-19
前言
本例子主要介绍如何使用 TensorFlow 来一步一步构建双端 LSTM 网络(听名字就感觉好腻害的样子),并完成序列标注的问题。先声明一下,本文中采用的方法主要参考了【中文分词系列】 4. 基于双向LSTM的seq2seq字标注这篇文章。该文章用 keras 框架来实现的双端 LSTM,在本例中,实现思路和该文章基本上一样,但是用 TensorFlow 来实现的。这个例子中涉及到的知识点比较多,包括 word embedding, Viterbi 算法等,但是就算你对这些不是非常了解,依然能够很好地理解本文。
本例的主要目的是讲清楚基于 TensorFlow 如何来实现双端 LSTM。通过本例的学习,你可以知道 Bi-directional LSTM 是怎么样一步一步计算的。为了讲清楚这个,我把封装好的 static_bidirectional_rnn 接口进行展开,自己手写实现了一遍。如果你只是想急着用一下看看效果的话,我也提供了static_bidirectional_rnn 接口的用法(其实网上多了去)。但是既然用这个东西,当然还是希望把细节也理解透更好。否则的话,还不如直接用 keras 几行就把模型建好了,中间的变量维度也不需要你过多地考虑,keras 框架已经写好了自动匹配的功能。但是你用 keras 跑了几个网络以后,一问你细节,你啥也不知道。所以,抱着学习的心态,从 TensorFlow 这一比较底层的框架上手还是能有不少收获的。另外,因为比较底层,我们可以比较灵活的进行模型修改(假设已经到了要改模型这一步…)
由于这个例子的代码比较长,本文主要就网络结构部分进行分析。其余的比如数据处理这些在这里只是简单介绍,想理解具体内容的欢迎移步 鄙人 GitHub,代码,数据 什么的全都放上去了。
如果你还不知道什么是 LSTM 的话,建议先看一下 (译)理解 LSTM 网络 (Understanding LSTM Networks by colah) 这篇文章。在理解 LSTM 的基础上,再去理解 双端 LSTM (Bi-directional LSTM)还是非常容易的。关于双端 LSTM 的原理,这里不做详细解释,下面这张图显示了 双端 RNN 的结构。
fig.1 Bi-RNN 按时间展开的结构
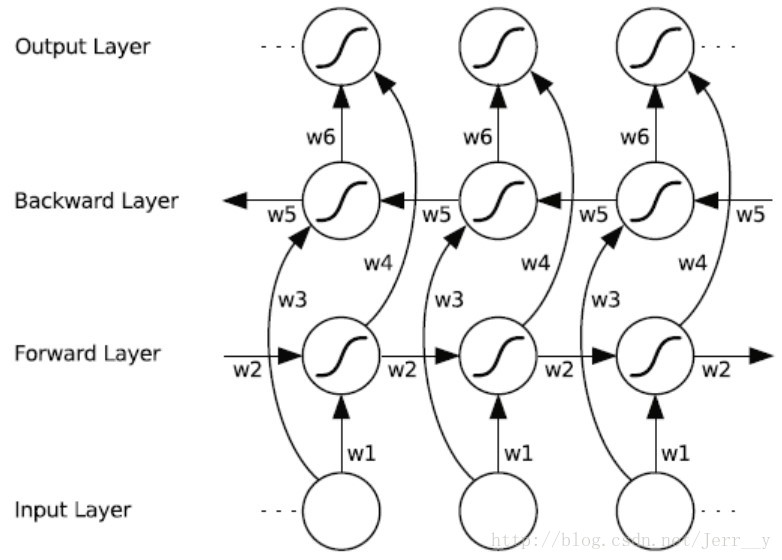
Bi-LSTM大致的思路是这样的,看图中最下方的输入层,假设一个样本(句子)有10个 timestep (字)的输入 x1,x2,...,x10
。 现在有两个相互分离的 LSTMCell:
- 对于前向 fw_cell ,样本按照x1,x2,...,x10
的顺序输入 cell 中,得到第一组状态输出 {h1,h2,...,h10
- } ;
- 对于反向 bw_cell ,样本按照 x10,x9,...,x1
- 的反序输入 cell 中,得到第二组状态输出 {h10,h9,...,h1
- };
- 得到的两组状态输出的每个元素是一个长度为 hidden_size 的向量(一般情况下,h1
- 和h1长度相等)。现在按照下面的形式把两组状态变量拼起来{[h1,h1], [h2,h2], … , [h10,h10
- ]}。
- 最后对于每个 timestep 的输入 xt
- , 都得到一个长度为 2*hidden_size 的状态输出 Ht= [ht,ht
- ]。然后呢,后面处理方式和单向 LSTM 一样。
1. 数据说明
下面大概说一下数据处理,但是这不影响对模型的理解,可以直接跳到
1.1 原始语料在txt文件中,长的下面这个样子
人/b 们/e 常/s 说/s 生/b 活/e 是/s 一/s 部/s 教/b 科/m 书/e ,/s 而/s 血/s 与/s 火/s 的/s 战/b 争/e 更/s 是/s 不/b 可/m 多/m 得/e 的/s 教/b 科/m 书/e ,/s 她/s 确/b 实/e 是/s 名/b 副/m 其/m 实/e 的/s ‘/s 我/s 的/s 大/b 学/e ’/s 。/s 心/s 静/s 渐/s 知/s 春/s 似/s 海/s ,/s 花/s 深/s 每/s 觉/s 影/s1.2 根据标点符号进行切分,下面是一个 sample
人/b 们/e 常/s 说/s 生/b 活/e 是/s 一/s 部/s 教/b 科/m 书/e1.3 把每个字和对应的tag转为一一对应的 id
在转为 id 之前,跟下表这样。这样的东西我们没办法塞到模型里去训练呀,必须先转为数值才行呀。
words tags sentence_len [人, 们, 常, 说, 生, 活, 是, 一, 部, 教, 科, 书] [b, e, s, s, b, e, s, s, s, b, m, e] 12 [而, 血, 与, 火, 的, 战, 争, 更, 是, 不, 可, 多, 得, 的, 教, …] [s, s, s, s, s, b, e, s, s, b, m, m, e, s, b, …] 17 Table.1 按标点切分后的片段
因为一般情况下,我们训练网络的时候都喜欢把输入 padding 到固定的长度,这样子计算更快。可是切分之后的句子长短不一,因此我们取 32 作为句子长度,超过 32 个字的将把多余的字去掉,少于 32 个字的将用特殊字符填充。处理之前,每个字 word <-> tag,处理完后变成 X <-> y。长度不足 32 的补0填充。(下面编码问题显示就这样,凑合着看吧。)
words: [u'\u4eba' u'\u4eec' u'\u5e38' u'\u8bf4' u'\u751f' u'\u6d3b' u'\u662f' u'\u4e00' u'\u90e8' u'\u6559' u'\u79d1' u'\u4e66'] tags: [u'b' u'e' u's' u's' u'b' u'e' u's' u's' u's' u'b' u'm' u'e'] X: [ 8 43 320 88 36 198 7 2 41 163 124 245 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] y: [2 4 1 1 2 4 1 1 1 2 3 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]跳到这里!!!
总之,上面这些都不重要,重要的是我们模型的输入 shape 是下面这样子的。第一维表示样本个数,第二维是 timestep_size。其实还有个第三维大小是 1, 因为每个时刻就只输入一个字,确切地说就是一个数字,因为我们已经把它转为数值 id 的形式了。
X_train.shape=(205780, 32), y_train.shape=(205780, 32); X_valid.shape=(51446, 32), y_valid.shape=(51446, 32); X_test.shape=(64307, 32), y_test.shape=(64307, 32)2. Bi-directional lstm 模型
2.1 模型分析
import tensorflow as tf config = tf.ConfigProto() config.gpu_options.allow_growth = True sess = tf.Session(config=config) from tensorflow.contrib import rnn import numpy as np''' For Chinese word segmentation. ''' # ##################### config ###################### decay = 0.85 max_epoch = 5 max_max_epoch = 10 timestep_size = max_len = 32 # 句子长度 vocab_size = 5159 # 样本中不同字的个数,根据处理数据的时候得到 input_size = embedding_size = 64 # 字向量长度 class_num = 5 hidden_size = 128 # 隐含层节点数 layer_num = 2 # bi-lstm 层数 max_grad_norm = 5.0 # 最大梯度(超过此值的梯度将被裁剪)lr = tf.placeholder(tf.float32) keep_prob = tf.placeholder(tf.float32) batch_size = tf.placeholder(tf.int32) # 注意类型必须为 tf.int32 model_save_path = 'ckpt/bi-lstm.ckpt' # 模型保存位置def weight_variable(shape):"""Create a weight variable with appropriate initialization."""initial = tf.truncated_normal(shape, stddev=0.1)return tf.Variable(initial)def bias_variable(shape):"""Create a bias variable with appropriate initialization."""initial = tf.constant(0.1, shape=shape)return tf.Variable(initial)X_inputs = tf.placeholder(tf.int32, [None, timestep_size], name='X_input') y_inputs = tf.placeholder(tf.int32, [None, timestep_size], name='y_input')如果你看过我上一篇文章 TensorFlow入门(五)多层 LSTM 通俗易懂版 的话,应该已经知道 LSTM 是怎么实现的了(如果不懂的话请先把上篇文章看懂再继续往下看了)。
下面重点终于来啦!!!
在这里,为了那些不懂 embedding 的朋友能够看懂下面的代码,我必须啰嗦几句说明一下什么是 word embedding。这是自然语言处理的一个大杀器,我们平时口口声声说的词向量就是这东西。在这个例子中我们指的是字向量,原理完全是一样的。刚才我们已经说过,每个 timestep 输入的是一个字对应的 id, 也就是一个整数。经过 embedding 操作之后,就变成了一个长度为 embedding_size(我们可以自己指定字向量的长度) 的实数向量。具体它是怎么做的呢?如果你是做自然语言处理的应该已经知道了,如果你不是做自然语言处理的呢,那就不用管了。反正,真正输入到 LSTMCell 中的数据 shape 长这样 [ batchsize, timestep_size, input_size ]。 input_size 是每个 timestep 输入样本的特征维度,如上个例子中就是MNIST字符每行的28个点,那么就应该 input_size=28。把你要处理的数据整理成这样的 shape 就可以了,管它什么 embedding。def bi_lstm(X_inputs):"""build the bi-LSTMs network. Return the y_pred"""# ** 0.char embedding,请自行理解 embedding 的原理!!做 NLP 的朋友必须理解这个embedding = tf.get_variable("embedding", [vocab_size, embedding_size], dtype=tf.float32)# X_inputs.shape = [batchsize, timestep_size] -> inputs.shape = [batchsize, timestep_size, embedding_size]inputs = tf.nn.embedding_lookup(embedding, X_inputs) # ** 1.LSTM 层lstm_fw_cell = rnn.BasicLSTMCell(hidden_size, forget_bias=1.0, state_is_tuple=True)lstm_bw_cell = rnn.BasicLSTMCell(hidden_size, forget_bias=1.0, state_is_tuple=True)# ** 2.dropoutlstm_fw_cell = rnn.DropoutWrapper(cell=lstm_fw_cell, input_keep_prob=1.0, output_keep_prob=keep_prob)lstm_bw_cell = rnn.DropoutWrapper(cell=lstm_bw_cell, input_keep_prob=1.0, output_keep_prob=keep_prob)# ** 3.多层 LSTMcell_fw = rnn.MultiRNNCell([lstm_fw_cell]*layer_num, state_is_tuple=True)cell_bw = rnn.MultiRNNCell([lstm_bw_cell]*layer_num, state_is_tuple=True)# ** 4.初始状态initial_state_fw = cell_fw.zero_state(batch_size, tf.float32)initial_state_bw = cell_bw.zero_state(batch_size, tf.float32) # 下面两部分是等价的# **************************************************************# ** 把 inputs 处理成 rnn.static_bidirectional_rnn 的要求形式# ** 文档说明# inputs: A length T list of inputs, each a tensor of shape# [batch_size, input_size], or a nested tuple of such elements.# *************************************************************# Unstack to get a list of 'n_steps' tensors of shape (batch_size, n_input)# inputs.shape = [batchsize, timestep_size, embedding_size] -> timestep_size tensor, each_tensor.shape = [batchsize, embedding_size]# inputs = tf.unstack(inputs, timestep_size, 1)# ** 5.bi-lstm 计算(tf封装) 一般采用下面 static_bidirectional_rnn 函数调用。# 但是为了理解计算的细节,所以把后面的这段代码进行展开自己实现了一遍。 # try: # outputs, _, _ = rnn.static_bidirectional_rnn(cell_fw, cell_bw, inputs, # initial_state_fw = initial_state_fw, initial_state_bw = initial_state_bw, dtype=tf.float32) # except Exception: # Old TensorFlow version only returns outputs not states # outputs = rnn.static_bidirectional_rnn(cell_fw, cell_bw, inputs, # initial_state_fw = initial_state_fw, initial_state_bw = initial_state_bw, dtype=tf.float32) # output = tf.reshape(tf.concat(outputs, 1), [-1, hidden_size * 2])# ***********************************************************# ***********************************************************# ** 5. bi-lstm 计算(展开)with tf.variable_scope('bidirectional_rnn'):# *** 下面,两个网络是分别计算 output 和 state # Forward directionoutputs_fw = list()state_fw = initial_state_fwwith tf.variable_scope('fw'):for timestep in range(timestep_size):if timestep > 0:tf.get_variable_scope().reuse_variables()(output_fw, state_fw) = cell_fw(inputs[:, timestep, :], state_fw)outputs_fw.append(output_fw)# backward directionoutputs_bw = list()state_bw = initial_state_bwwith tf.variable_scope('bw') as bw_scope:inputs = tf.reverse(inputs, [1])for timestep in range(timestep_size):if timestep > 0:tf.get_variable_scope().reuse_variables()(output_bw, state_bw) = cell_bw(inputs[:, timestep, :], state_bw)outputs_bw.append(output_bw)# *** 然后把 output_bw 在 timestep 维度进行翻转# outputs_bw.shape = [timestep_size, batch_size, hidden_size]outputs_bw = tf.reverse(outputs_bw, [0])# 把两个oupputs 拼成 [timestep_size, batch_size, hidden_size*2]output = tf.concat([outputs_fw, outputs_bw], 2) # output.shape 必须和 y_input.shape=[batch_size,timestep_size] 对齐output = tf.transpose(output, perm=[1,0,2])output = tf.reshape(output, [-1, hidden_size*2])# ***********************************************************softmax_w = weight_variable([hidden_size * 2, class_num]) softmax_b = bias_variable([class_num]) logits = tf.matmul(output, softmax_w) + softmax_breturn logitsy_pred = bi_lstm(X_inputs) # adding extra statistics to monitor # y_inputs.shape = [batch_size, timestep_size] correct_prediction = tf.equal(tf.cast(tf.argmax(y_pred, 1), tf.int32), tf.reshape(y_inputs, [-1])) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) cost = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels = tf.reshape(y_inputs, [-1]), logits = y_pred))# ***** 优化求解 ******* # 获取模型的所有参数 tvars = tf.trainable_variables() # 获取损失函数对于每个参数的梯度 grads, _ = tf.clip_by_global_norm(tf.gradients(cost, tvars), max_grad_norm) # 优化器 optimizer = tf.train.AdamOptimizer(learning_rate=lr) # 梯度下降计算 train_op = optimizer.apply_gradients( zip(grads, tvars),global_step=tf.contrib.framework.get_or_create_global_step()) print 'Finished creating the bi-lstm model.'过多的解释也没有了,都在上面的代码中!但还是得说一声,在这个双端 LSTM 模型中,重点要理解两点:
1. 两个 LSTM (cell_fw, cell_bw)的计算是各自独立的,只是最后输出的时候把二者的状态向量结合起来。 2. 本例中每个 timestep 都有结果输出,而上篇的分类问题中我们只拿最后一个 h_state 来计算最后的输出(注意这不是 Bi-LSTM 和 单向 LSTM 的区别, 单向的也可以每个 timestep 都输出)。注意本例中的 y_input 也对应的每个 timestep 对应一个 tag(id)。2.2 实验结果
看一下结果吧,不放结果都是耍流氓 :
(1) 先是分类准确率**Test 64307, acc=0.948665, cost=0.139884(2)实际分词
人们 / 思考 / 问题 / 往往 / 不是 / 从 / 零开始 / 的 / 。 / 就 / 好 / 像 / 你 / 现在 / 阅读 / 这 / 篇 / 文章 / 一样 / , / 你 / 对 / 每个 / 词 / 的 / 理解 / 都会 / 依赖 / 于 / 你 / 前面 / 看到 / 的 / 一些 / 词 / , / / 而 / 不是 / 把 / 你 / 前面 / 看 / 的 / 内容 / 全部 / 抛弃 / 了 / , / 忘记 / 了 / , / 再去 / 理解 / 这个 / 单词 / 。 / 也 / 就 / 是 / 说 / , / 人们 / 的 / 思维 / 总是 / 会 / 有 / 延续 / 性 / 的 / 。 /结论:本例子使用 Bi-directional LSTM 来完成了序列标注的问题。本例中展示的是一个分词任务,但是还有其他的序列标注问题都是可以通过这样一个架构来实现的,比如 POS(词性标注)、NER(命名实体识别)等。在本例中,单从分类准确率来看的话差不多到 95% 了,还是可以的。可是最后的分词效果还不是非常好,但也勉强能达到实用的水平 (详细请看全部代码及说明: https://github.com/yongyehuang/Tensorflow-Tutorial/blob/master/Tutorial_6%20-%20Bi-directional%20LSTM%20for%20sequence%20labeling%20(Chinese%20segmentation).ipynb),而且模型也只是粗略地跑了一遍,还没有进行任何的参数优化。最后的维特比译码中转移概率只是简单的用了等概分布,如果能根据训练语料以统计结果作为概率分布的话相信结果能够进一步提高。
3.reference
[1] 【中文分词系列】 4. 基于双向LSTM的seq2seq字标注 http://spaces.ac.cn/archives/3924/
[2] https://github.com/yongyehuang/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/bidirectional_rnn.py
[3] https://github.com/yongyehuang/deepnlp/blob/master/deepnlp/pos/pos_model_bilstm.py
这篇关于#####好好好##### 双端 LSTM 实现序列标注(分词)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





