本文主要是介绍使用pytorch构建GAN网络并实现FID评估,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上一篇文章介绍了GAN的详细理论,只要掌握了GAN,对于后面各种GAN的变形都变得很简单,基础打好了,盖大楼自然就容易了。既然有了理论,实践也是必不可少的,这篇文章将使用mnist数据集来实现简单的GAN网络,并附带使用FID来评估生成质量。
1. FID评估方法
1.1 计算方法
Fréchet Inception Distance (FID),是一种用于评估生成模型生成图像质量的指标,通常用于比较生成图像与真实图像之间的相似度,FID的数值越低表示生成的图像质量越好。具体来源可自行百度一下,这里不在介绍。FID是通过计算两组图像的均值,方差的距离,从而计算两组图像分布的相似读。直接看公式:
F I D ( r e a l , g e n ) = ∣ ∣ μ r e a l − μ g e n ∣ ∣ 2 2 + T r ( C r e a l + C g e n − 2 ( C r e a l C g e n ) 1 / 2 ) FID(real,gen) = ||\mu_{real}-\mu_{gen}||_2^2 + Tr(C_{real} + C_{gen} - 2(C_{real}C_{gen})^{1/2}) FID(real,gen)=∣∣μreal−μgen∣∣22+Tr(Creal+Cgen−2(CrealCgen)1/2)
其中 μ r e a l , μ g e n \mu_{real},\mu_{gen} μreal,μgen是real数据和gen数据分布的均值, C r e a l , C g e n C_{real},C_{gen} Creal,Cgen表示real和gen各自特征向量的各自的协方差;Tr表示矩阵的迹 T r ( A ) = ∑ i = 1 n A i i Tr(A)=\sum_{i=1}^nA_{ii} Tr(A)=∑i=1nAii(方阵对角线元素之和)。
这里需要注意到是,一般情况real数据和gen数据是经过inception V3模型提取图像特征后的结果,并非真实输入图片。
1.2 代码实现
虽然有些库里面集成了FID函数,为了更好理解,我们手动来实现这个代码。
主要分为三个部分来计算:
- inception V3 特征提取
- 均值计算、协方差计算
- FID计算
具体我们来看一下完整代码实现。
import torch
import torchvision.models as models
import numpy as np
from scipy import linalg"""
FID 测试一般3000~5000张图片,
FID小于50:生成质量较好,可以认为生成的图像与真实图像相似度较高。
FID在50到100之间:生成质量一般,生成的图像与真实图像相似度一般。
FID大于100:生成质量较差,生成的图像与真实图像相似度较低。
"""# 加载预训练inception v3模型, 并移除top层,第一次运行会下载模型到cache里面
def load_inception():model = models.inception_v3(weights='IMAGENET1K_V1')model.eval()# 将fc用Identity()代替,即去掉fc层model.fc = torch.nn.Identity()return model# inception v3 特征提取
def extract_features(images, model):# images = images / 255.0with torch.no_grad():feat = model(images)return feat.numpy()# FID计算
def cal_fid(images1, images2):"""images1, images2: nchw 归一化,且维度resize到[N,3,299,299]"""model = load_inception()#1. inception v3 特征feats1 = extract_features(images1, model)feats2 = extract_features(images2, model)#2. 均值协方差feat1_mean, feat1_cov = np.mean(feats1, axis=0), np.cov(feats1, rowvar=False)feat2_mean, feat2_cov = np.mean(feats2, axis=0), np.cov(feats2, rowvar=False)#3. Fréchet距离sqrt_trace_cov = linalg.sqrtm(feat1_cov @ feat2_cov)fid = np.sum((feat1_mean - feat2_mean) ** 2) + np.trace(feat1_cov + feat2_cov - 2 * sqrt_trace_cov)return fid.realif __name__ == '__main__':f = cal_fid(torch.rand(1000, 3, 299, 299), torch.rand(1000, 3, 299, 299))print(f)2. 构建GAN网络
参考:
https://github.com/growvv/GAN-Pytorch/blob/main/README.md
2.1 使用全连接构建一个最简单的GAN网络
2.1.1 网络结构
import torch
import torch.nn as nn
from torchinfo import summaryclass Discriminator(nn.Module):def __init__(self, in_features):super().__init__()self.disc = nn.Sequential(nn.Linear(in_features, 256), # 784 -> 256nn.LeakyReLU(0.2), #nn.Linear(256, 256), # 256 -> 256nn.LeakyReLU(0.2),nn.Linear(256, 1), # 255 -> 1nn.Sigmoid(), # 将实数映射到[0,1]区间)def forward(self, x):return self.disc(x)class Generator(nn.Module):def __init__(self, z_dim, image_dim):super().__init__()self.gen = nn.Sequential(nn.Linear(z_dim, 256), # 64 升至 256维nn.ReLU(True),nn.Linear(256, 256), # 256 -> 256nn.ReLU(True),nn.Linear(256, image_dim), # 256 -> 784nn.Tanh(), # Tanh使得生成数据范围在[-1, 1],因为真实数据经过transforms后也是在这个区间)def forward(self, x):return self.gen(x)if __name__ == "__main__":gnet = Generator(64, 784)dnet = Discriminator(784)summary(gnet, input_data=[torch.randn(10, 64)])summary(dnet, input_data=[torch.randn(10, 784)])网络结构运行以上代码,可以查看模型结构:
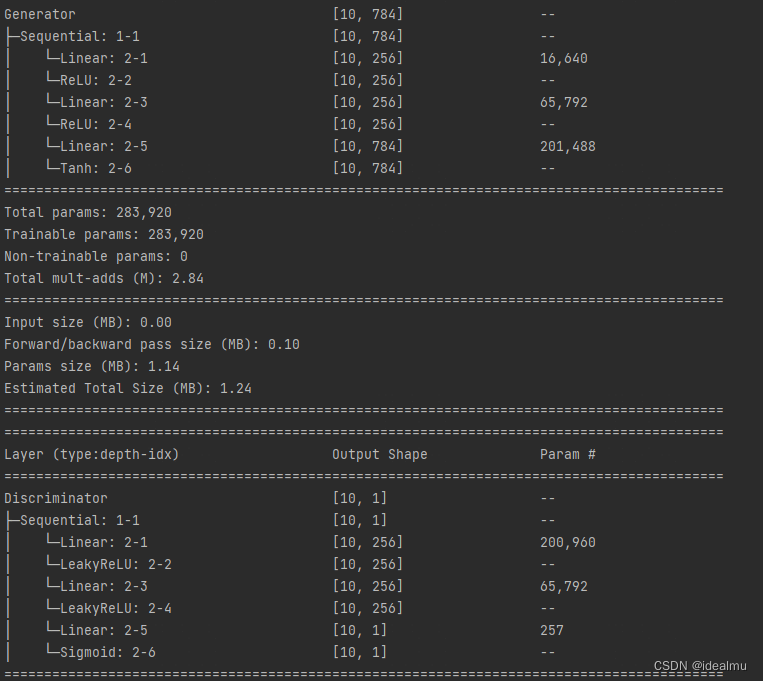
2.1.2 训练代码
以下是训练代码,直接可以运行
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
from simplegan import Generator, Discriminator# 超参数
device = "cuda" if torch.cuda.is_available() else "cpu"
lr = 3e-4
z_dim = 64
image_dim = 28 * 28 * 1
batch_size = 32
num_epochs = 100Disc = Discriminator(image_dim).to(device)
Gen = Generator(z_dim, image_dim).to(device)
opt_disc = optim.Adam(Disc.parameters(), lr=lr)
opt_gen = optim.Adam(Gen.parameters(), lr=lr)
criterion = nn.BCELoss() # 单目标二分类交叉熵函数transforms = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,)),]
)
dataset = datasets.MNIST(root="dataset/", transform=transforms, download=True)
loader = DataLoader(dataset=dataset, batch_size=batch_size, shuffle=True)fixed_noise = torch.randn((batch_size, z_dim)).to(device)
write_fake = SummaryWriter(f'logs/fake')
write_real = SummaryWriter(f'logs/real')
step = 0for epoch in range(num_epochs):for batch_idx, (real, _) in enumerate(loader):real = real.view(-1, 784).to(device)batch_size = real.shape[0]## D: 目标:真的判断为真,假的判断为假## 训练Discriminator: max log(D(x)) + log(1-D(G(z)))disc_real = Disc(real)#.view(-1) # 将真实图片放入到判别器中lossD_real = criterion(disc_real, torch.ones_like(disc_real)) # 真的判断为真noise = torch.randn(batch_size, z_dim).to(device)fake = Gen(noise) # 将随机噪声放入到生成器中disc_fake = Disc(fake).view(-1) # 识别器判断真假lossD_fake = criterion(disc_fake, torch.zeros_like(disc_fake)) # 假的应该判断为假lossD = (lossD_real + lossD_fake) / 2 # loss包括判真损失和判假损失Disc.zero_grad() # 在反向传播前,先将梯度归0lossD.backward(retain_graph=True) # 将误差反向传播opt_disc.step() # 更新参数# G: 目标:生成的越真越好## 训练生成器: min log(1-D(G(z))) <-> max log(D(G(z)))output = Disc(fake).view(-1) # 生成的放入识别器lossG = criterion(output, torch.ones_like(output)) # 与“真的”的距离,越小越好Gen.zero_grad()lossG.backward()opt_gen.step()# 输出一些信息,便于观察if batch_idx == 0:print(f"Epoch [{epoch}/{num_epochs}] Batch {batch_idx}/{len(loader)}' \loss D: {lossD:.4f}, loss G: {lossG:.4f}")with torch.no_grad():fake = Gen(fixed_noise).reshape(-1, 1, 28, 28)data = real.reshape(-1, 1, 28, 28)img_grid_fake = torchvision.utils.make_grid(fake, normalize=True)img_grid_real = torchvision.utils.make_grid(data, normalize=True)write_fake.add_image("Mnist Fake Image", img_grid_fake, global_step=step)write_real.add_image("Mnist Real Image", img_grid_real, global_step=step)step += 1
使用 tensorboard --logdir=./log/fake 查看生成的质量, 这个是41个epoch的结果,想要质量更好一点,可以继续训练。

2.2 DCGAN网络
DCGAN只是把全连接替换成全卷积的结构,思路完全一样,没什么变换
2.2.1 DCGAN网络结构
"""
Discriminator and Generator implementation from DCGAN paper
"""import torch
import torch.nn as nn
from torchinfo import summaryclass Discriminator(nn.Module):def __init__(self, channels_img, features_d):super().__init__()self.disc = nn.Sequential(self._block(channels_img, features_d, kernel_size=4, stride=2, padding=1),self._block(features_d, features_d * 2, 4, 2, 1),self._block(features_d * 2, features_d * 4, 4, 2, 1),self._block(features_d * 4, features_d * 8, 4, 2, 1),nn.Conv2d(features_d * 8, 1, kernel_size=4, stride=2, padding=0),nn.Sigmoid(),)def _block(self, in_channels, out_channels, kernel_size, stride, padding):return nn.Sequential(nn.Conv2d(in_channels,out_channels,kernel_size,stride,padding,bias=False),nn.LeakyReLU(0.2),)def forward(self, x):return self.disc(x)class Generator(nn.Module):def __init__(self, channels_noise, channels_img, features_g):super().__init__()self.gen = nn.Sequential(self._block(channels_noise, features_g * 16, 4, 1, 0),self._block(features_g * 16, features_g * 8, 4, 2, 1),self._block(features_g * 8, features_g * 4, 4, 2, 1),self._block(features_g * 4, features_g * 2, 4, 2, 1),nn.ConvTranspose2d(features_g * 2, channels_img, 4, 2, 1),nn.Tanh(),)def _block(self, in_channels, out_channels, kernel_size, stride, padding):return nn.Sequential(nn.ConvTranspose2d(in_channels,out_channels,kernel_size,stride,padding,bias=False,),nn.ReLU(),)def forward(self, x):return self.gen(x)def initialize_weights(model):## initilialize weight according to paperfor m in model.modules():if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d,)):nn.init.normal_(m.weight.data, 0.0, 0.02)def test():N, in_channels, H, W = 8, 1, 64, 64noise_dim = 100x = torch.randn(N, in_channels, H, W)disc = Discriminator(in_channels, 8)initialize_weights(disc)assert disc(x).shape == (N, 1, 1, 1), "Discriminator test failed"gen = Generator(noise_dim, in_channels, 8)initialize_weights(gen)z = torch.randn(N, noise_dim, 1, 1)assert gen(z).shape == (N, in_channels, H, W), "Generator test failed"if __name__ == "__main__":gnet = Generator(100, 1, 64)dnet = Discriminator(1, 64)summary(gnet, input_data=[torch.randn(10, 100, 1, 1)])summary(dnet, input_data=[torch.randn(10, 1, 64, 64)])2.2.2 训练代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from dcgan import Generator, Discriminator, initialize_weights
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
import torchvisionLEARNING_RATE = 2e-4
BATCH_SIZE = 128
IMAGE_SIZE = 64
NUM_EPOCHS = 5
CHANNELS_IMG = 1
NOISE_DIM = 100
FEATURES_DISC = 64
FEATURES_GEN = 64transforms = transforms.Compose([transforms.Resize(IMAGE_SIZE),transforms.ToTensor(),transforms.Normalize([0.5 for _ in range(CHANNELS_IMG)], [0.5 for _ in range(CHANNELS_IMG)]),]
)write_fake = SummaryWriter(f'log/fake')
write_real = SummaryWriter(f'log/real')def train(NUM_EPOCHS, gpuid):device = torch.device(f"cuda:{gpuid}")# 数据load# dataset = datasets.ImageFolder(root="celeb_dataset", transform=transforms)dataset = MNIST(root='./data', train=True, download=True, transform=transforms)dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)gen = Generator(NOISE_DIM, CHANNELS_IMG, FEATURES_GEN).to(device)disc = Discriminator(CHANNELS_IMG, FEATURES_DISC).to(device)initialize_weights(gen)initialize_weights(disc)opt_gen = optim.Adam(gen.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))opt_disc = optim.Adam(disc.parameters(), lr=LEARNING_RATE, betas=(0.5, 0.999))criterion = nn.BCELoss()fixed_noise = torch.randn(32, NOISE_DIM, 1, 1).to(device)writer_real = SummaryWriter(f"logs2/real")writer_fake = SummaryWriter(f"logs2/fake")step = 0gen.train()disc.train()for epoch in range(NUM_EPOCHS):# 不需要目标的标签,无监督for batch_id, (real, _) in enumerate(dataloader):real = real.to(device)noise = torch.randn(BATCH_SIZE, NOISE_DIM, 1, 1).to(device)fake = gen(noise)# Train Discriminator: max log(D(x)) + log(1 - D(G(z)))disc_real = disc(real).reshape(-1)loss_real = criterion(disc_real, torch.ones_like(disc_real))disc_fake = disc(fake.detach()).reshape(-1)loss_fake = criterion(disc_fake, torch.zeros_like(disc_fake))loss_disc = (loss_real + loss_fake) / 2disc.zero_grad()loss_disc.backward()opt_disc.step()# Train Generator: min log(1 - D(G(z))) <-> max log(D(G(z)), 先训练一个epoch 的Dif epoch >= 0:output = disc(fake).reshape(-1)loss_gen = criterion(output, torch.ones_like(output))gen.zero_grad()loss_gen.backward()opt_gen.step()if batch_id % 20 == 0:print(f'Epoch [{epoch}/{NUM_EPOCHS}] Batch {batch_id}/{len(dataloader)} Loss D: {loss_disc}, loss G: {loss_gen}')with torch.no_grad():fake = gen(fixed_noise)img_grid_real = torchvision.utils.make_grid(real[:32], normalize=True)img_grid_fake = torchvision.utils.make_grid(fake[:32], normalize=True)writer_real.add_image("Real Image", img_grid_real, global_step=step)writer_fake.add_image("Fake Image", img_grid_fake, global_step=step)step += 1if __name__ == "__main__":train(100, 0)同样使用tensorboard --logdir=./logs2/fake 查看生成的质量,大概10个epoch的结果
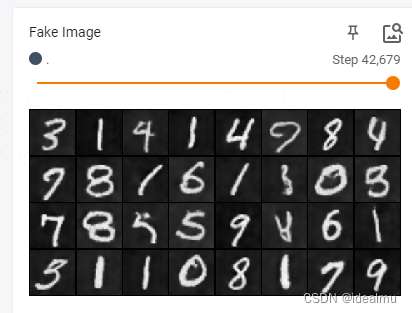
结论
FID指标可自行测试。GAN的基本训练思路是完全按照论文来做的,包括损失函数设计完全跟论文一致。具体理论可仔细看上一篇博客。如有不足,错误请指出。
这篇关于使用pytorch构建GAN网络并实现FID评估的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




