本文主要是介绍#####好好好#####GAN 在文本生成上的一些体会,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
先抛出我的结论:
SeqGAN 这一框架下的 GAN-based 文本生成模型,work 很大程度上是 training trick 的堆砌,并不适合工程应用,但依旧值得探索,或者蹭热点发 Paper。
这段时间做用 GAN 做文本生成还是蛮多的,这里指的是 SeqGAN 这一框架,其简要特点如下:
- RNN-based Generator + Classifier-based Discrminator:用一个 RNN 来建模 language model; CNN 之类分类器来对生成的文本/真实文本进行判别,或者是对文本的某种属性进行判定
- 利用 MLE 进行 Pretrain:让 G 和 D 具备初始的能力
- 利用 Monte Carlo 来得到 reward,通过 Policy Gradient 指导 Generator 更新
起初我也是为止着迷,认为这一框架非常 fancy,但是随着时间推移,跑了不少实验之后发现,adversarial training 在其中起到的作用实在是微不足道(对比之前的 MLE pretrain,adversarial training 并不会带来生成文本质量的显著提升),为什么呢?接下来谈一下 Adversarial Training 在 Text Generation 中的两个主要的问题。
Problem
Sparse reward
adversarial training 没起作用很大的一个原因就在于,discriminator 提供的 reward 具备的 guide signal 太少,Classifier-based Discriminator 提供的只是一个为真或者假的概率作为 reward,而这个 reward 在大部分情况下,是 0。这是因为对于 CNN 来说,分出 fake text 和 real text 是非常容易的,CNN 能在 Classification 任务上做到 99% 的 accuracy,而建模 Language Model 来进行生成,是非常困难的。除此以外,即使 generator 在这样的 reward 指导下有一些提升,此后的 reward 依旧很小。从这一点出发,现有不少工作一方法不再使用简单的 fake/true probability 作为 reward,我在之前的 GAN in NLP Notes 中也提到了有 LeakyGAN(把 CNN 的 feature 泄露给 generator),RankGAN (用 IR 中的排序作为 reward)等工作来提供更加丰富的 reward;另一个解决的思路是使用 language model-based discriminator,以提供更多的区分度,北大孙栩老师组的 DP-GAN 在使用了 Languag model discrminator 之后,在 true data 和 fake data 中间架起了一座桥梁:
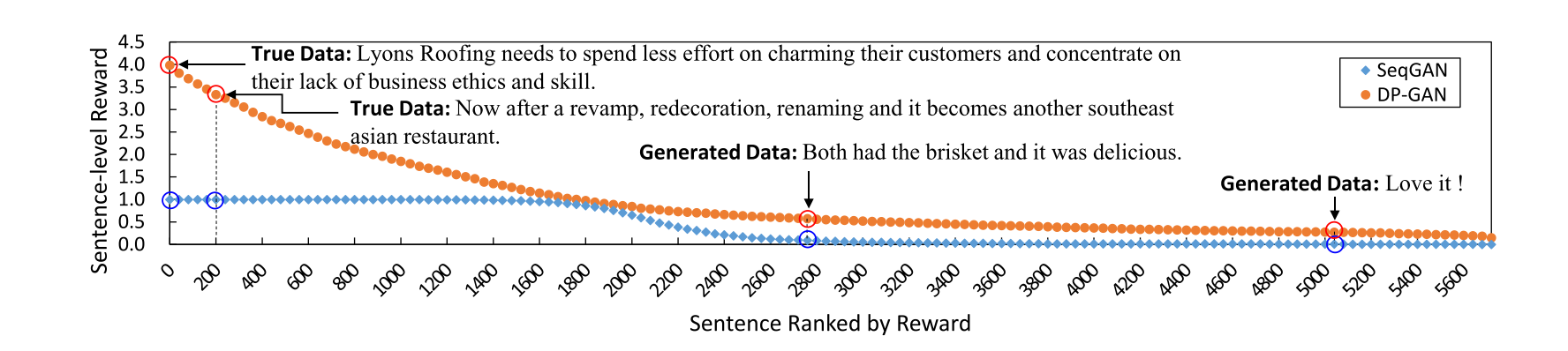
从而 discriminator 不再是非 0 即 1。据其他同学的一些经验,DP-GAN 的实验效果也是非常不错的,这一点或许可以和之前的两个数据流型分布中间没有交集有关,使用了更 distinguishable 的 reward 之后,fake data 的分布和 true data 的分布加大了,GAN 的距离度量才有了变化。
Monte Carlo Search
在 SeqGAN 以及后续的很多工作之中,对于 Reward 的评估都是基于句级别的,也就是会先使用 Monte Carlo Search 的方法将句子进行补全再交给 Discriminator,但是这个采样方法的时间复杂度是 $O(n mL^2)$,其中 $n$ 是 batch size,$m$ 是采样的次数,$L$ 是句子的 max len。就 SeqGAN 的实验来说,$m = 16$ 并且 $L=20$ ,速度尚且可以接受,但是如果我们需要去生成一篇文章 $L=200$,那么每次计算 reward 就会来带很大的开销,我个人的体验是在 Tesla M40 上 $L$ 在 100 左右,$m = 16, n = 64$ 一个 batch 需要 230 s。对于常见的万级别的 corpus,一个 Epoch 的训练时间就到了一天,而最终对于性能的提升还不如 MLE 一个 epoch 来的显著,这也是我为什么不建议在工程上使用的很大程度的一个原因。
Solution
- Sparse Reward:这里可以用的除了 DP-GAN 以外,SentiGAN 也是一个不错的尝试,其 Penalty-based objective function 效果还是很不错的,可以尝试着使用一下;另外,我们也可以从 discriminator 的角度,适当地减弱其能力,像 GAN 中的一些 trick 比如
label smothing也可以尝试。 - Monte Carlo Search:这一点的解决方法比较困难,MaskGAN 提出用 Actor-Critic 的结构来对 word level 给出 reward,并且在其“完形填空”的任务上效果不错,但对于语言模型来说, word-level reward 还是不怎么符合 intuition。降低 sample time 并不是一个可取的方案,因为本身 MC 带来的 variance 已经很大了,再降低 sample time 只能是雪上加霜;或许搜索的剪枝是一个可以考虑的方向,会去看看有没有一些方案。
Future
展望一下未来,只能说 SeqGAN 这个坑不出意外还会吸引很多同学义无反顾地往里跳,想要做出一些东西,还是很有挑战性的。但是 RL 和 NLP 结合的思路是没什么大毛病的,Jiwei Li 最近的几篇 Dialogue 的文章也都是用着 RL,我觉得这一点很 fancy 的一个原因是我们可以通过设计 reward 来指导生成,这其实是蛮 hand-crafted 的,把规则比较隐式地放进神经网络里,或许 RL 是一条可以走的路;IRL 在 Text Generation 上的应用邱锡鹏老师也有一篇文章。希望自己也能够在这条路上走地更远一些~
这篇关于#####好好好#####GAN 在文本生成上的一些体会的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





