本文主要是介绍Hass哈斯数控数据采集网络IP配置设置,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
机床数据采集(MDC)允许你使用Q和E命令通过网络接口或选项无线网络从控制系统提取数据。设置143支持该功能,并且指定控制器使用这个数据端口。MDC是一个需要一台附加计算机发送请求,解释说明和存储机床数据的软件功能。这个远程计算机也可以设置一些宏变量的值。
HAAS控制器使用一个TCP服务器在网络中进行通讯。在远程电脑中,你可以使用任何支持TCP的终端程序;实例中使用了PuTTy。允许(2)个及以上的连接。输出请求由一个连接发送给所有的连接。
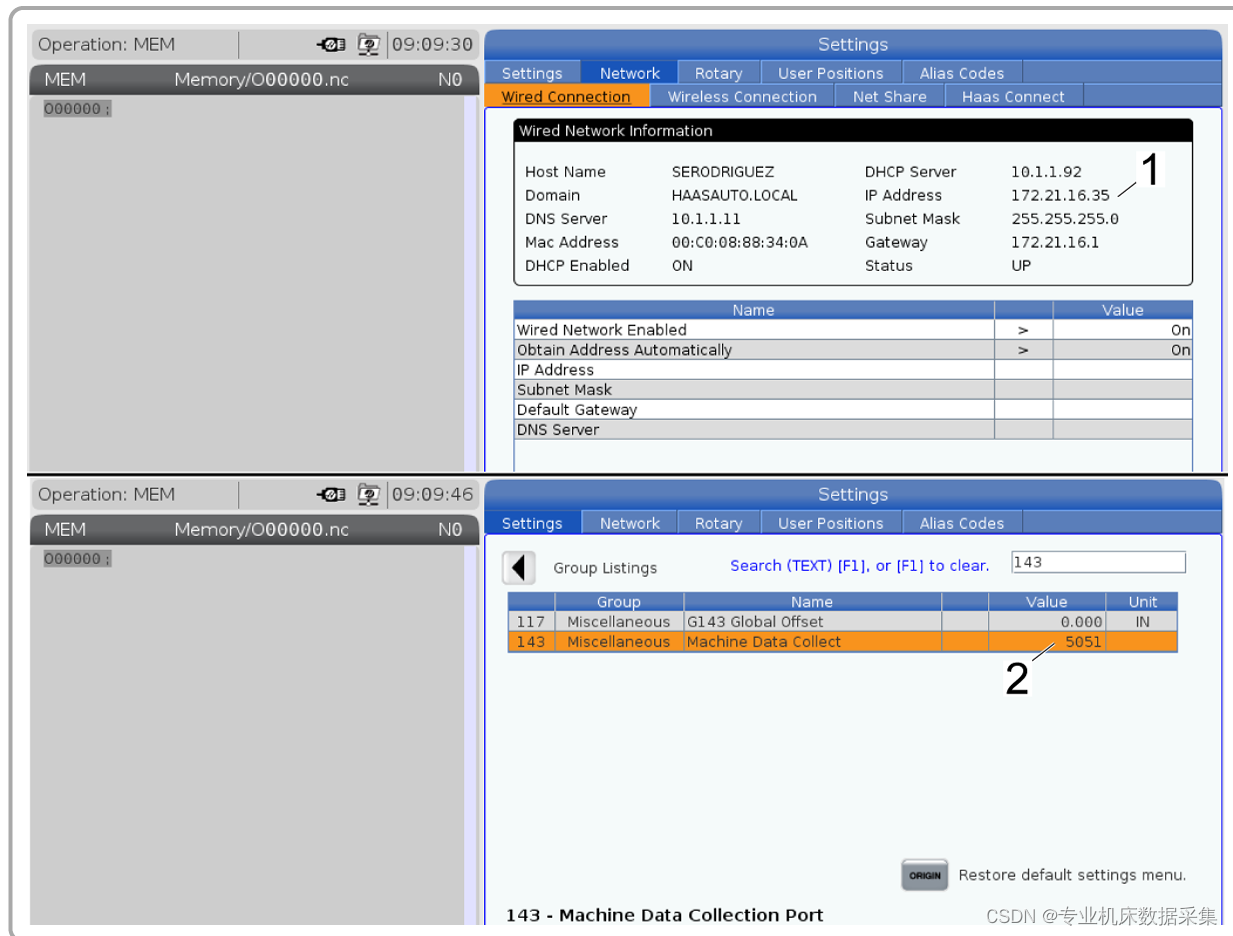
在网络设置中找到机床IP地址[1]
在设置143中键入一个可找到的端口号。在这个例子中我们使用的端口号为5051。
将这些数字记下将来在PUTTY程序中会用到他们。
我该使用哪一个端口号?
这些端口号的工作类似电话的分机。作为一个商业电话的接线总机,可以用一个主电话号码并分配给每个员工一个分机号码(类似X100,X101等),因此一台电脑有一个主地址并设置一个端口去处理进来和出去连接。端口号设置范围从0到65535。
重要提示:不要使用端口号1-1023,5900,6000,8082和9090-9999因为这些端口号已经被HAAS CNC控制系统作为其他功能使用了。不要随意使用端口号,一些端口号可以能已经被网络中的系统,服务器和其他设备占用。
这篇关于Hass哈斯数控数据采集网络IP配置设置的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







