本文主要是介绍缓存菜品操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一:问题说明
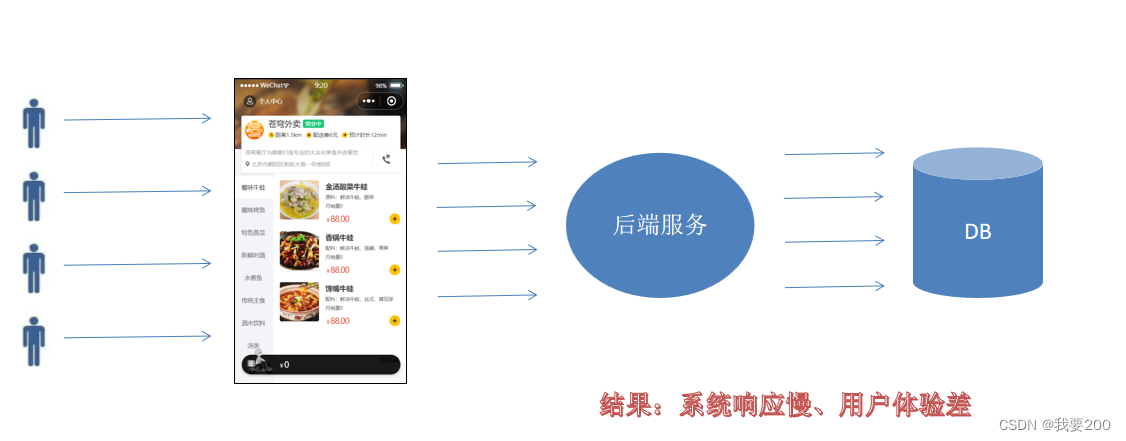
用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大。
二:实现思路
通过Redis来缓存菜品数据,减少数据库查询操作。

缓存逻辑分析:
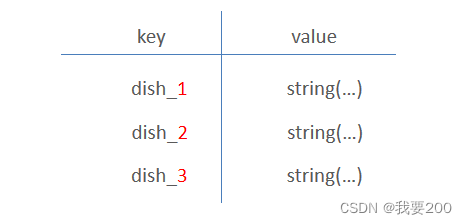
- 每个分类下的菜品保存一份缓存数据
- 数据库中菜品数据有变更时清理缓存数据
三:具体的代码实现:
DishControll层(用户端):
我们需要在dishcontrol层加入缓存处理
- 注入redis
- 构造redis的key(根据我们上面的规则,redis中的key是为dish_ + 分类的id)
- 查询redis中是否有这个菜品
- 如果有,直接返回
- 如果没有,请求数据库,并且把这个菜品放到redis中
package com.sky.controller.user;import com.sky.constant.StatusConstant;
import com.sky.entity.Dish;
import com.sky.result.PageResult;
import com.sky.result.Result;
import com.sky.service.DishService;
import com.sky.vo.DishVO;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;import java.util.List;@RestController("userDishController")
@RequestMapping("/user/dish")
@Api(tags = "菜品相关接口")
@Slf4j
public class DishController {@Autowiredprivate DishService dishService;@Autowiredprivate RedisTemplate redisTemplate;/*** 根据分类id查询菜品* @param categoryId* @return*/@GetMapping("/list")@ApiOperation("根据分类id查询菜品")public Result<List<DishVO>> selectById(Long categoryId){log.info("根据分类id查询菜品:{}",categoryId);//构造redis中的key ,规则:dish_分类idString key = "dish_" + categoryId;//查询redis中是否又菜品数据List<DishVO> dishVOList = (List<DishVO>) redisTemplate.opsForValue().get(key);if(dishVOList != null|| dishVOList.size()>0){//如果存在,直接返回,不用查询数据库return Result.success(dishVOList);}Dish dish = new Dish();dish.setCategoryId(categoryId);dish.setStatus(StatusConstant.ENABLE);/*这里的dish对象的作用就是充当一个判断条件我们返回的是一个List<DishVO>对象,那这个对象的条件是什么呢?是:这个dish的分类id和这个categoryId相等,并且呢,还得是在起售的产品*/List<DishVO> list = dishService.listWithFlavor(dish);//如果不存在,查询数据库,将查询到的数据放到redis中redisTemplate.opsForValue().set(key,list);return Result.success(list);}
}
清理缓存:
上面的操作有一个很大的问题就是,如果我们修改了数据库里面的数据,怎么同步到redis中
这就涉及到这个请求缓存的操作了
我们的解决方法是在服务端DishControll层(因为客户肯定不可能修改我的数据,只有客户端可以)进行清理缓存的操作。
那这个时候又要具体分析了,什么样的方法需要清理缓存,是不是对数据库能进行修改的操作嘞
(增删改)
所以我们在dishcontroll层对这三类方法采用的方法是:
只要你对这个数据库进行了操作,我们直接把相关的缓存全部删掉
DishControll层(服务端):
package com.sky.controller.admin;import com.github.pagehelper.Page;
import com.sky.dto.DishDTO;
import com.sky.dto.DishPageQueryDTO;
import com.sky.entity.Dish;
import com.sky.result.PageResult;
import com.sky.result.Result;
import com.sky.service.DishService;
import com.sky.vo.DishVO;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.*;import java.util.ArrayList;
import java.util.List;
import java.util.Set;@RestController("adminDishController")
@RequestMapping("/admin/dish")
@Api(tags = "菜品相关接口")
@Slf4j
public class DishController {@Autowiredprivate DishService dishService;@Autowiredprivate RedisTemplate redisTemplate;/*** 新增菜品操作* @param dishDTO* @return*/@PostMapping@ApiOperation("新增菜品操作")public Result save(@RequestBody DishDTO dishDTO){log.info("新增菜品:{}",dishDTO);dishService.insert(dishDTO);//清理缓存数据String pattern = "dish_"+dishDTO.getCategoryId();cleanCache(pattern);return Result.success();}/*** 分页查询菜品* @param dishPageQueryDTO* @return*/@GetMapping("/page")@ApiOperation("分页查询菜品操作")public Result<PageResult> page(DishPageQueryDTO dishPageQueryDTO){log.info("分页查询菜品");PageResult pageresult = dishService.page(dishPageQueryDTO);return Result.success(pageresult);}/*** 批量删除菜品* @param ids* @return*/@DeleteMapping@ApiOperation("批量删除菜品")public Result delete(@RequestParam List<Long> ids){log.info("批量删除菜品:{}",ids);dishService.deletebatch(ids);//清理缓存数据String pattern = "dish_*";cleanCache(pattern);return Result.success();}/*** 根据id查询菜品* @param id* @return*/@GetMapping("/{id}")@ApiOperation("根据id查询菜品接口")public Result<DishVO> selectById(@PathVariable Long id){log.info("根据id查询菜品:{}",id);DishVO dishVO = dishService.selectById(id);return Result.success(dishVO);}/*** 修改菜品* @param dishDTO* @return*/@PutMapping@ApiOperation("修改菜品接口")public Result update(@RequestBody DishDTO dishDTO){log.info("修改菜品:{}",dishDTO);dishService.updateWithFlavor(dishDTO);//清理缓存数据String pattern = "dish_*";cleanCache(pattern);return Result.success();}/*** 菜品起售停售* @param status* @param id* @return*/@PostMapping("/status/{status}")@ApiOperation("菜品起售停售")public Result<String> startOrStop(@PathVariable Integer status, Long id){dishService.startOrStop(status,id);//清理缓存数据String pattern = "dish_*";cleanCache(pattern);return Result.success();}/*** 清理缓存* @param pattern*/private void cleanCache(String pattern){final Set keys = redisTemplate.keys(pattern);redisTemplate.delete(keys);}
}
四:Spring Cache框架:
Spring Cache 是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能
Spring Cache中的常用注解:

Spring Cache入门小程序:
@EnableCaching注解:
直接加在启动类上就行。
@Slf4j
@SpringBootApplication
@EnableCaching//启动缓存注解
public class CacheDemoApplication {public static void main(String[] args) {SpringApplication.run(CacheDemoApplication.class,args);log.info("项目启动成功...");}
}
@CachePut注解:
(cacheput这个注解一般加在插入数据的方法上)
@PostMapping@CachePut(cacheNames = "userNames",key = "#user.id")public User save(@RequestBody User user){userMapper.insert(user);return user;}这里的cacheNames其实就是这个缓存的名字。
key的生成:cacheNames::#user.id

我们这个使用的时候这个返回值的id,
@Insert("insert into spring_cache_demo.user(name,age) values (#{name},#{age})")@Options(useGeneratedKeys = true,keyProperty = "id")void insert(User user);这里需要注意的是,我们需要在mapper层中的插入方法下加入将id返回这个一个选项功能。
因为id是自增的,所以不一定要从前端传。
@Cacheable注解:
@GetMapping@Cacheable(cacheNames = "userNames",key = "#id")public User getById(Long id){User user = userMapper.getById(id);return user;}这里的两个参数就和刚刚的@CachePut的参数一样就行。
下面是我查询了一个id为1的数据,因为id为1的数据还没放到缓存中,所以还是从数据库里面查的

然后我查询了一个id为2的数据,控制台没有任何反应。
并且这个Cacheable注解还会把数据直接插入缓存中:
下面是我又查了一次id为1的数据。
控制台没有任何的反应
@Cacheable 这个注解使用了一个代理对象的技术(AOP),
就是当你给controller层的方法加了这个Cacheable注解,其实这个框架就会创建一个代理对象,我们查询的数据会先被这个代理对象接收,如果这个代理对象没查到,才会交给这个方法来查。
具体的体现就是,如果这个数据在这个缓存中,就连这个select的方法都不会调用(用断点的方式可以测出)
@CacheEvict注解:
@DeleteMapping@CacheEvict(cacheNames = "userNames",key = "#id")public void deleteById(Long id){userMapper.deleteById(id);}这个注解主要的作用就是帮我们清楚缓存,我们直接在发一条sql语句,同时能删除数据库中和redis中的数据。
@CacheEvict(cacheNames = "setmealCache",allEntries = true)
如果指定这个allEntries = true,那就代表把所有的缓存都给删掉
Spring Cache缓存套餐具体思路:
具体的实现思路如下:
- 导入Spring Cache和Redis相关maven坐标
- 在启动类上加入@EnableCaching注解,开启缓存注解功能
- 在用户端接口SetmealController的 list 方法上加入@Cacheable注解
- 在管理端接口SetmealController的 save、delete、update、startOrStop等方法上加入CacheEvict注解
这篇关于缓存菜品操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



