本文主要是介绍虚拟化界的强强联手:VirtIO与GPU虚拟化的完美结合,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
近距离了解 VirtIO 和 GPU 虚拟化
这是一篇 Linaro 开发团队项目组的科普文章。我们在处理器虚拟化项目中,经常会遇到 VirtIO 相关的问题;比如运行 Andriod 系统的时候需要运行 VirtIO 组件。随着 Cassini 项目和 SOAFEE(嵌入式边缘可扩展开放架构)等项目的开发,VirtIO 成为支持基于标准的云原生边缘开发/部署环境的关键构件,旨在实现这些高效的 EDGE 开发环境。GPU 虚拟化是 VirtIO 中较为复杂的组件之一。
本文将讨论其中的一些挑战以及 Linaro 开发团队在这一领域取得的进展。基于VirtIO的块和网络设备是相对简单的抽象,可以很好地映射到底层硬件。这些设备经过多轮优化,最大限度地减少了虚拟化开销。由于硬件种类繁多,图形处理器(GPU)更难抽象化。在简单的 2D 图形时代,任何特定的硬件都只能支持特定范围的内存布局和色深。随着技术的发展,图形引擎获得了复制内存区域、管理精灵或旋转纹理等各种不同的能力。随着 3D 技术的出现,情况并没有变得更简单。
现代 GPU 实际上是一种特殊用途处理器,经过优化后可以执行渲染现代场景所需的大量并行计算。很多现代超级计算机都以这些数字运算流水线为核心,这并不奇怪。然而,与大多数 CPU 不同的是,GPU 执行模型的细节往往不为用户所知。通常情况下,GPU 要么使用更高级别的 API 进行编程,然后由专有的二进制 Blob 将其翻译成秘密的隐藏指令流,再输送到 GPU。虽然有许多开放的 GPU 编程 API,旨在实现 GPU 之间的可移植性,但也有与特定硬件绑定的供应商专用库。所有这些都使得 GPU 虚拟化成为一个特别具有挑战性的领域。可以使用的方法大致有两种:虚拟函数和 API 转发。
虚拟功能
这种方法与其他高性能虚拟化硬件的做法类似,都是将单个物理卡划分为多个虚拟功能(VF)。然后,每个 VF 都可以与访客共享,访客可以直接驱动它,就像作为主机运行一样。在服务器领域,主要 GPU 厂商(英特尔、AMD、nVidia)的高端 GPU 卡都支持 SR-IOV。它使用成熟的 PCI 分区在客户机之间划分 VF。然而,面向汽车和工业市场的 GPU 面临两个挑战:
- VF 数量较少(可能只有 2 个,需要抽象化)- 平台特定的分区方案市场上支持 VF 分区的 GPU 仍然相当罕见,而且现有的 GPU 通常只支持有限的分割,这意味着仍然需要一个完全抽象的虚拟 GPU 来复用多个有图形需求的客户。由于这些设备通常是平台设备(即直接映射内存,而非 PCI 设备),因此需要在固件、平台和驱动程序之间协调,才能支持这些 VF 的分配。从简洁抽象的角度来看,这使得问题变得更加复杂。
软件辅助虚拟功能为了解决这些限制,我们采用了各种软件辅助方法来弥补纯硬件支持的不足。其最初形式是一种名为 "中介设备"(mdev)的扩展,在硬件允许的情况下,它允许主机内核对设备进行分区。目前,支持该功能的内核驱动程序只有英特尔 i915 驱动程序和一个 s390 加密驱动程序。
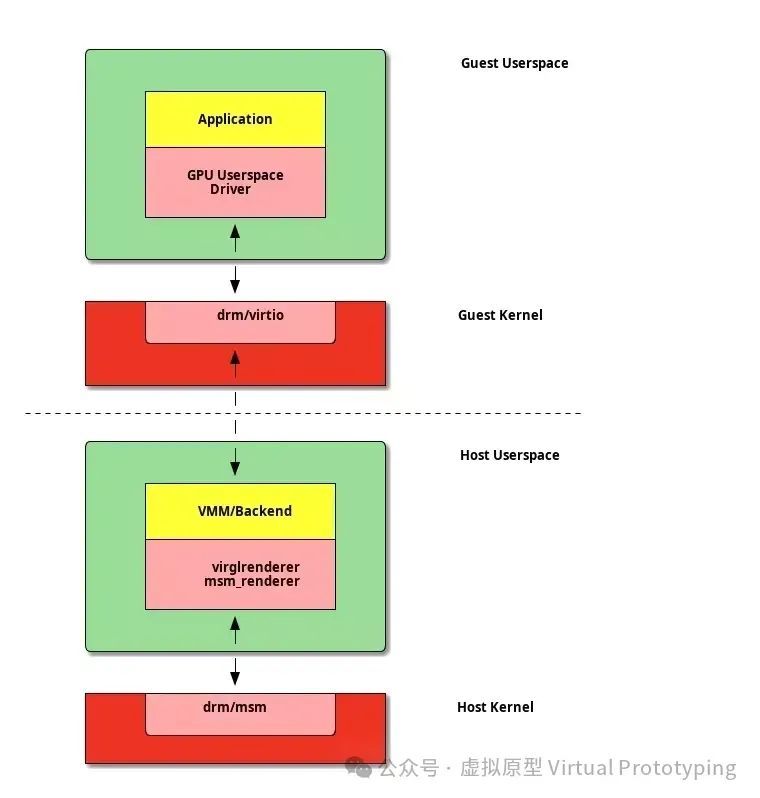
利用 virtIO-gpu 的扩展(本地上下文)优化 GPU 虚拟化。
此方法:
- 利用 VirtIO 机制实现常用功能
- 直接向客户机提供原生上下文
- 客户机运行经过修改的原生 GPU 驱动程序,支持:
- VirtIO 感知
- 针对特定 GPU 的自定义协议
应用程序接口转发GPU 虚拟化的另一种方法是 API 转发。它的工作原理是为客户提供一个理想化的虚拟硬件,该硬件与共享库抽象的要求密切相关。VirtIO GPU 最初的 3D 加速基于 OpenGL。
该设备提供了一个名为 VirGL 的虚拟 OpenGL 设备,它基于 Gallium3D 接口。这样,访客只需向设备输入一系列 OpenGL 命令和通用的独立于 GPU 的着色器中间语言。在后端,这些命令被输入 virglrenderer,然后通过主机 GPU 进行渲染。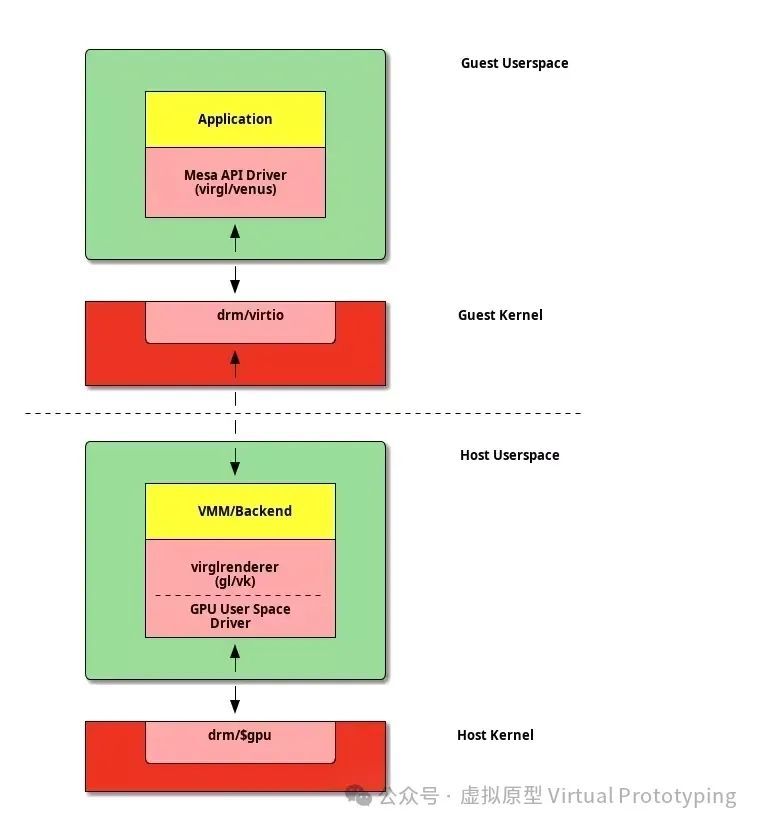 对 VirGL 方法的主要不满在于效率。虽然可以运行流畅的桌面体验,但性能却远低于直接在主机上运行的预期。其中一个原因可能是古老的 OpenGl 编程模型与现代 GPU 的编程方式相比过于抽象。再加上不可避免的虚拟化开销,加剧了其性能问题。为了取代 OpenGL,我们开发了一种名为 Vulkan 的更现代的 API,它是一种更低级的编程 API,更贴近现代图形硬件的工作方式。它还将图形与计算工作流(GPUS 的一个重要用例)统一在一个 API 下。
对 VirGL 方法的主要不满在于效率。虽然可以运行流畅的桌面体验,但性能却远低于直接在主机上运行的预期。其中一个原因可能是古老的 OpenGl 编程模型与现代 GPU 的编程方式相比过于抽象。再加上不可避免的虚拟化开销,加剧了其性能问题。为了取代 OpenGL,我们开发了一种名为 Vulkan 的更现代的 API,它是一种更低级的编程 API,更贴近现代图形硬件的工作方式。它还将图形与计算工作流(GPUS 的一个重要用例)统一在一个 API 下。
虽然虚拟 GPU 对 Vulkan 的支持尚未在 QEMU 等项目中实现,但一些替代虚拟机监控器(VMM)能够使用这种模式提供更高效的虚拟 GPU 实现。最后还有第三种协议,即 Wayland 协议,它并不直接针对 GPU,而是用于与支持 3D 的显示服务器进行对话。这样,在客户机中运行的客户程序就能与主机显示管理器无缝集成。最初的用例是让 CrosVM 客户端中的 Linux 应用程序与 ChromeOS 主机集成。有趣的是,该协议还针对车载娱乐系统进行了扩展。
两种方法的比较对于那些希望通过保持尽可能轻量级的抽象来尽可能提高图形硬件性能的用户来说,虚拟函数似乎是未来的发展方向。此外,通过将复杂的图形栈隔离在客户域库中,还可以降低开发风险,这也是一个很好的安全论据。GPU 就其本质而言,必须处理大量不受信任的访客数据。
不过,这种直通方法也有一些缺点。在云原生开发中,最大的问题是将客户代码绑定到特定的 GPU 架构上,这意味着云和边缘部署之间的可移植性较差。此外,对于 Linaro 这家主要使用开源技术的公司来说,增加支持需要访问遍布整个堆栈的专有代码,而不是处理开源抽象。我们认为,通过使用 Rust 等更安全的语言编写 VirtIO 后端,图形堆栈的一些安全问题可以得到改善。 但需要注意的是,大部分后端最终仍将使用普通 C 语言库进行处理。要降低特权主机被攻击的风险,一种方法是将图形后端转移到单独的虚拟机(有时称为驱动域)中。这样,如果守护进程被攻破,攻击者仍会被控制在一个相对有限的环境中。
与 Orko 项目的关系
Orko 项目是我们之前的虚拟化项目 Stratos 的精神继承者。我们正在努力将一些 VirtIO 设备集成到 SOAFEE 参考平台中,以加快其应用。多媒体是汽车工作负载的主要驱动力,因此拥有一个实用的 GPU 解决方案非常重要。最初有两项工作计划用于支持 GPU。
衡量抽象成本
虽然有一些关于 VirGL 在某些系统上的性能的轶事,但我们还没有看到对这些抽象在 ARM 硬件上的成本进行全面测量。我们想知道这些较新的图形管线是否可用于处理像运行 AAA 级游戏一样的繁重工作负载,而不会产生过多的开销。
对于 QEMU,有几个小组提出了各种补丁,通过各种扩展来增强 virtio-gpu 设备。我们打算在帮助审查的同时,将这些补丁与 QEMU 最近的 xenpvh 支持集成,并开始在实际硬件上测量每个抽象的成本。我们还想探索使用 CrosVM Wayland 后端(它在引擎盖下使用 vhost-user),看看与 QEMU 的 xenpvh 模式和我们的 Xen vhost-user 前端集成有多少工作量。
独立的 virtio-gpu 守护进程
虽然我们在 SOAFEE 平台中使用 QEMU 来帮助启动 VirtIO 设备,但我们的愿景仍然是利用 rust-vmm 组件,使用 Rust 编写独立于管理程序的独立守护进程。独立守护进程之所以有用,还有很多其他原因:
- 通过 rust-vmm 特质和 vhost-user 扩展,我们隐藏了 Xen 中映射内存和通知的底层实现,实现了跨管理程序的抽象层。这种方法简化了管理程序的交互,并提高了虚拟机管理的灵活性。
- 如果没有独立于核心 VMM 的后端,我们就无法尝试我之前讨论过的驱动域概念
最好的办法是扩展 CrosVM 的 Wayland 实现以支持其他 GPU 命令流,还是从头开始编写一个新的后端,还有待观察。我们目前正在进行准备工作,测量各种抽象的开销,以帮助我们了解未来的发展方向。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
这篇关于虚拟化界的强强联手:VirtIO与GPU虚拟化的完美结合的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







