本文主要是介绍全球260多个国家的年通货膨胀率数据集(1960-2021年),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
01、数据简介
全球年通货膨胀率是指全球范围内,在一年时间内,物价普遍上涨的比率。这种上涨可能是由于货币过度供应、需求过热、成本上升等原因导致的。通货膨胀率是衡量一个国家或地区经济状况和物价水平的重要指标,通常以消费者价格指数(CPI)或国内生产总值平减指数(GDP deflator)来衡量。
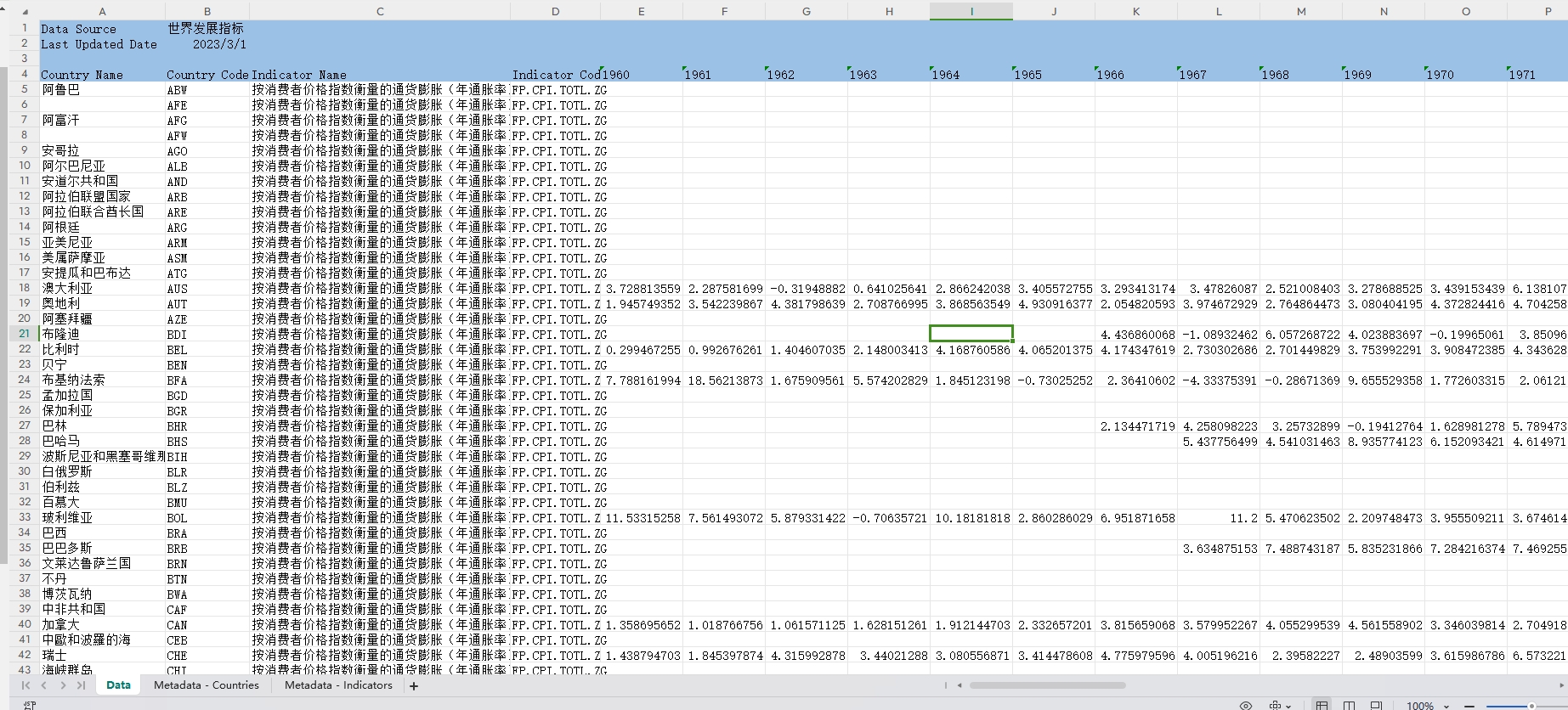
消费者价格指数(CPI):按消费者价格指数衡量的通货膨胀反映出普通消费者在指定时间间隔(如年度)内购买固定或变动的一篮子货物和服务的成本的年百分比变化。通常采用拉斯佩尔公式进行计算。
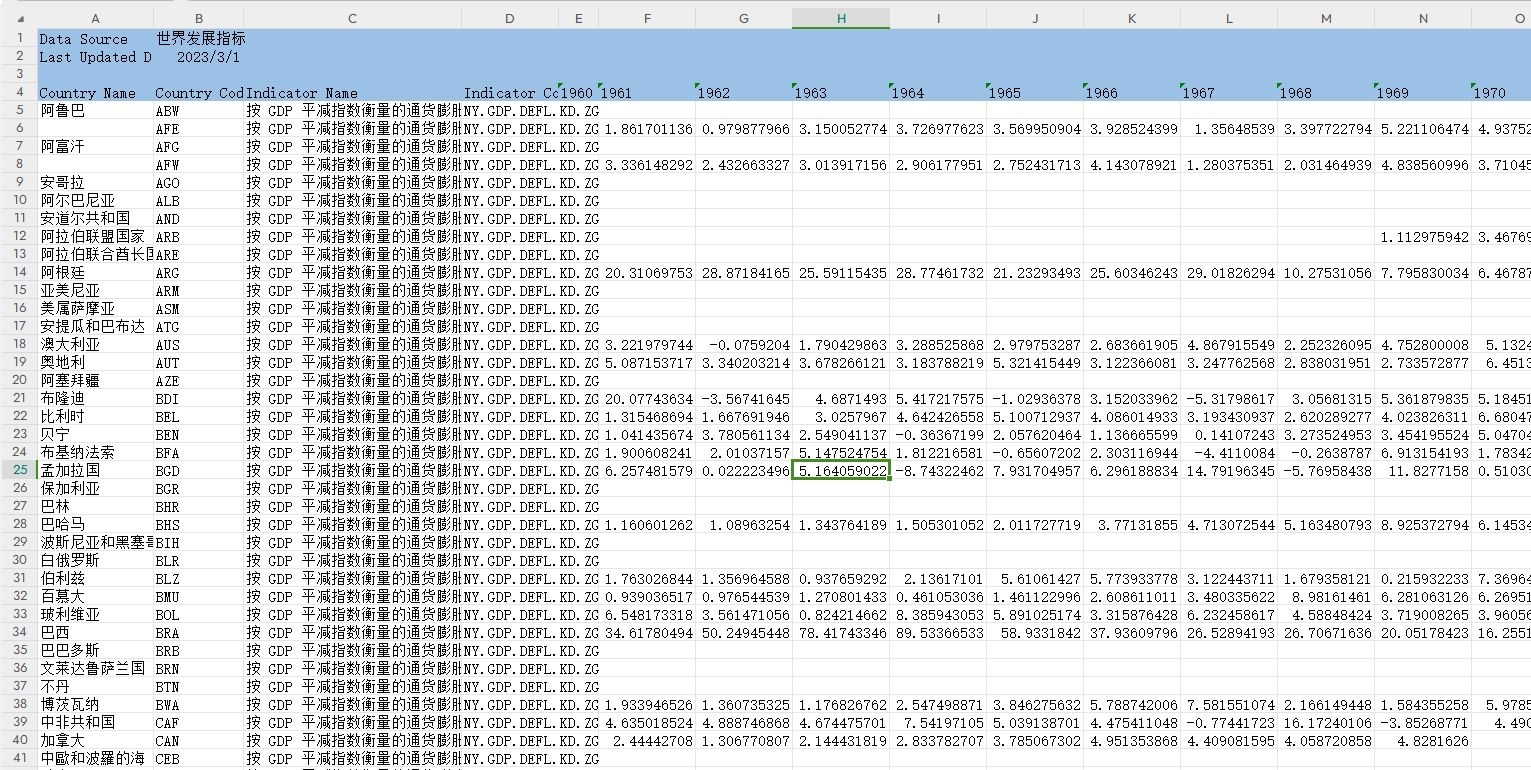
GDP平减指数:按 GDP 隐含价格平减指数年增长率衡量的通货膨胀显示的是整个经济体的价格变动率。GDP 隐含价格平减指数是按照现价本币计算的 GDP 与按照不变价本币计算的 GDP 之比。
数据名称:全球年通货膨胀率
数据年份:1960-2021年
数据来源:世界银行
02、相关数据
Country Name、Country Code、Indicator Name、Indicator Code、阿鲁巴、阿富汗、安哥拉、阿尔巴尼亚、安道尔共和国、阿拉伯联盟国家、阿拉伯联合酋长国、阿根廷、亚美尼亚、美属萨摩亚、安提瓜和巴布达、澳大利亚、奥地利、阿塞拜疆、布隆迪、比利时、贝宁布基纳法索等等260多个国家
03、数据截图
消费者价格指数(CPI):
GDP平减指数:
04、下载链接:
消费者价格指数下的年通货膨胀率:https://download.csdn.net/download/T0620514/89273066
GDP 平减指数下的年通货膨胀率:https://download.csdn.net/download/T0620514/89273067
这篇关于全球260多个国家的年通货膨胀率数据集(1960-2021年)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






