本文主要是介绍【参赛总结】第二届云原生编程挑战赛-冷热读写场景的RocketMQ存储系统设计 - Nico,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关联比赛: 2021第二届云原生编程挑战赛1:针对冷热读写场景的RocketMQ存储系统设计
引子
在一个浑浑噩噩的下午,百无聊赖的我像往常一样点开了划水交流群,细细品味着老哥们关于量子力学的讨论。嬉戏间,平常水不拉几的群友张三忽然发了一张大大的橙图,我啪的一下点开了,很快啊,仔细观摩后发现原来是2021第二届云原生编程挑战赛报名的海报,暗暗的想起了被我鸽掉的前几届,小手不自觉地打开了链接并且一键三连。
每个人的心里都有一个童心未泯的自己,这次比赛就像一场游戏一样让我深陷其中,三岔路口,我选择了存储领域,谁承想这决定会让我在接下来的两个月里减少百分之N的发量。
读题
赛题目的是实现简单的消息读取与存储,程序需要实现append和getRange方法,并依次通过性能评测与正确性评测,性能评测耗时最少者居高。
评测环境
Linux下的4核8G服务器,配置400G ESSD PL1云盘,吞吐可达320MiB/s,60G Intel 傲腾持久内存PMem(Persistent Memory),由参考文档可推测为第一代持久内存,代号为AEP。
赛题编程语言限制为Java8,JVM配置为6G堆内+2G堆外。
性能评测
评测程序首先会创建10~50个不等的线程,每个线程随机分配若干个topic进行写入,topic总数量不超过100个。每个topic之下又分为若干个queue,总数量不超过5000个,调用append方法后返回当前数据在queue中的offset,由0开始。每次写入数据大小为100B-17KiB区间随机,当写满75G数据后,会挑选一半的queue由下标0(头)开始读取,另外一半从当前最大下标(尾)开始读取,并保持之前的写入压力继续写入50G数据,最后一条数据读取完毕后停止计时。
正确性评测
同样会使用N个线程写入数据,在写入过程中会重启ECS,之后再读取之前写入成功的数据(返回offset即视为成功),要求严格一致。
持久内存
本次比赛多了一个比较陌生的存储介质PMem,它结合了内存的读写性能和持久化的特性,可以在延迟可以控制在纳秒级。
目前主流的实现为非易失性双列直插式内存模块NVDIMM(Non-Volatile Dual In-Line Memory Module,NVDIMM),它是持久内存的一种实现,目前有三种实现标准:
- NVDIMM-N: 配置同等容量的DRAM和NAND Flash,另外还有一个超大电容,当主机断电后,PMem设备会使用电容中保留的电量保证DRAM的数据同步到闪存中。
- NVDIMM-F: 使用了适配DDR规格的NAND Flash,通过多个控制器和桥接器将DDR总线信息转化为SATA协议信息来操作闪存的读写。
- NVDIMM-P: 同样配置了DRAM和NAND Flash,只不过DRAM容量会比闪存少很多,DRAM在其中作为闪存上层的缓存以优化读写性能,同样使用超大电容来保障断电后的脏数据持久。
Intel傲腾第一代持久内存AEP遵循NVDIMM-P标准,实现了非易失性,可以按字节寻址(Byte Addressable)操作,小于1μs的延时,以及集成密度高于或等于DRAM等特性。不同于传统的NAND Flash实现,傲腾持久内存使用了新型非易失性存储器3D-XPoint,其内部是一种全新的存储介质。
Intel傲腾持久内存提供多种操作模式:
- 内存模式: 此模式下持久内存被当做超大容量的易失性内存使用,其中DRAM被称为近内存(Near Memory),持久化介质被称为远内存(Far Memory),读写性能取决于读写时命中近内存还是远内存。
- AD模式: 此模式下持久内存直接暴露给用户态的应用程序直接调用,应用程序通过持久内存感知文件系统(PMEM-Aware File System)将用户态的内存空间直接映射到持久内存设备上,从而应用程序可以直接进行加载(Load)和存储(Store)操作。这种形式也被称作DAX,意为直接访问。目前主流的文件系统ext4, xfs 都支持Direct Access的选项(-o dax),英特尔也提供了用于在持久内存上进行编程的用户态软件库PMDK。
本次比赛使用AD模式。
分析
首先关注的是正确性评测,写入过程会重启ECS,那么就要保证在append方法return之前数据要落盘,也就是说每个写入请求都要fsync刷盘。另外在重启ECS之后,会清理PMem上的数据,所以数据肯定要在ESSD上保存一份。
总写入数据量为125G,而ESSD提供400G容量,正常写入的情况下不用考虑硬盘GC的问题。除了ESSD空间外,我们还有60G的PMem可用,而且文件系统通常会预留一部分文件空间作紧急情况使用,所以PMem可用容量会更高(实测真实容量为62G左右)。DRAM内存也要尽可能利用起来,首选不受JVM限制的2G堆外,剩下的6G堆内如何使用就要在GC和整体性能之间做抉择了。
文件写入
方案1: 每个queue一个文件,这样可以保证顺序读写,但最坏的情况下需要创建100 * 5000 = 500,000个文件,操作系统默认每个用户进程1024个句柄肯定会超限。
方案2: 每个topic一个文件,那么最坏只需要创建100个文件,可以接受,但这意味着多个queue的数据要写入同一个文件中,无法保证顺序读写,不过可以是使用稀疏索引来做块存储。另外因为正确性评测的限制,我们需要在每次写入后手动fsync,所以这种设计下会导致频繁的fsync,也就意味着用户态与内核态之间要频繁的切来切去,另外数据大小范围为100B~17KiB,ESSD在一次写入32K以上数据时才能发挥最优性能,很明显当前设计是打不满ESSD PL1的吞吐的。

方案3: 所有topic共用一个文件,通过对以上弊端的思考,我们应该尽可能每次fsync时写入更多的数据,由于N个线程并发写同一个文件,所以我们可以将N个线程的数据先写入聚合缓冲中后并挂起,等待将缓冲中的数据刷盘后再取消阻塞。这个方案可以保证顺序写随机读,每次写入数据足够多,并且减少了核态的切换次数,但是刷盘变成了串行,或许能得到一个不错的ESSD吞吐,但是对CPU造成了浪费。
在上一个假设上做优化,因为评测环境配置4核CPU,我们将所有线程分为4组,每组对应一个文件,这样既可以保证ESSD的性能,又可以在无法绑核的情况下尽可能压榨所有CPU的性能。
文件读写的API方面,首先放弃传统的FileWriter/FileRead,相比而言,FileChannel提供双向读写能力且更易操控读写数据精度。MMap是另外一种方案,因为它只在创建的时候需要切态,理论上它的读写速度会比FileChannel更快,但是由于种种原因,MMap映射大小受限,这无疑增加了程序设计上的维护成本,另外最终场景每次写入数据量平均在64KB左右,通过Benchmark,FileChannel在这种场景下性能总是优于MMap。最终选定使用FileChannel进行文件读写,另外为了减少用户与向内核态的内存复制,使用DirectByteBuffer用作写入缓冲。
最终方案: 将所有线程分为4组,充分利用多核CPU,每组对应一个AOF数据文件,每组线程的数据写入缓冲后并挂起,缓冲刷盘后再取消阻塞,返回offset。
缓存利用
首先要明确一点,在本次赛题中,无论是DRAM还是PMem,都不能利用它们用来做数据的持久化(PMem正确性阶段重启后会做数据清理),ESSD是必须要求写入的。因此,缓存的主要利用方向在于提高读性能。
首先是性能最快但是容量最小的DRAM,官方不允许使用unsafe来额外分配堆外的堆外内存,所以可供我们使用的DRAM只有2G的堆外以及6G的堆内,又由于JVM的GC机制外加程序本身的业务流程需要一定的内存开销,所以6G的堆内可供我们用来做数据存储的部分大打折扣(实际测下来可以用到3.2G),而堆外内存会有一部分用于文件读写缓冲,所以堆外内存可用量也会小于2G。另外就是62G的持久内存PMem,由于其性能优于ESSD数百倍,容量远大于DRAM,且ext4支持dax模式,可直接用FileChannel操作读写,对于它的合理使用直接决定了最终成绩的好坏。
再回到性能评测上进行分析,我们将整个过程分为是三个阶段(重点,下文要考):
- 一阶段: 先写入
75G的数据。 - 二阶段: 评测程序随机挑选一半的queue从头开始读,另一半从结尾开始读,并在读的同时,继续写入
50G的数据。 - 三阶段: 随着时间的推移,最终读取的offset点位会慢慢追赶上当前写入的点位,此阶段中刚写入的数据有可能下一刻被读取。
经过分析,我们需要在一阶段尽可能的将数据写入缓存,这样二阶段读取时可以减少ESSD的命中率。由于二阶段会有一半的queue从结尾开始读数据,这也就意味着这些queue之前的数据可以被淘汰,淘汰后的缓存可以复用于之后写入的数据。另外由于二阶段的过程是边读边写,读后的缓存也可以投入复用。
所以理论上二阶段所有写入的数据全部可以复用到淘汰后的缓存。到了三阶段后,应该尽可能使用性能最高的DRAM来存储热数据。
最终方案: 一阶段首先将缓存写入大约5G的DRAM中,之后的数据写入62G的PMem中(此过程的ESSD一直保持着写入),每个记录的缓存信息保存在对应的queue中。来到二阶段后,将淘汰的缓存按介质类型及大小放入不同的缓存池,之后写入的数据会优先向DRAM缓存池申请缓存块,其次是PMem缓存池。
当然,前期的分析也只能基于理论,最终方案的背后是无数个日日夜夜的测试和思考(卷就完了。
整体方案
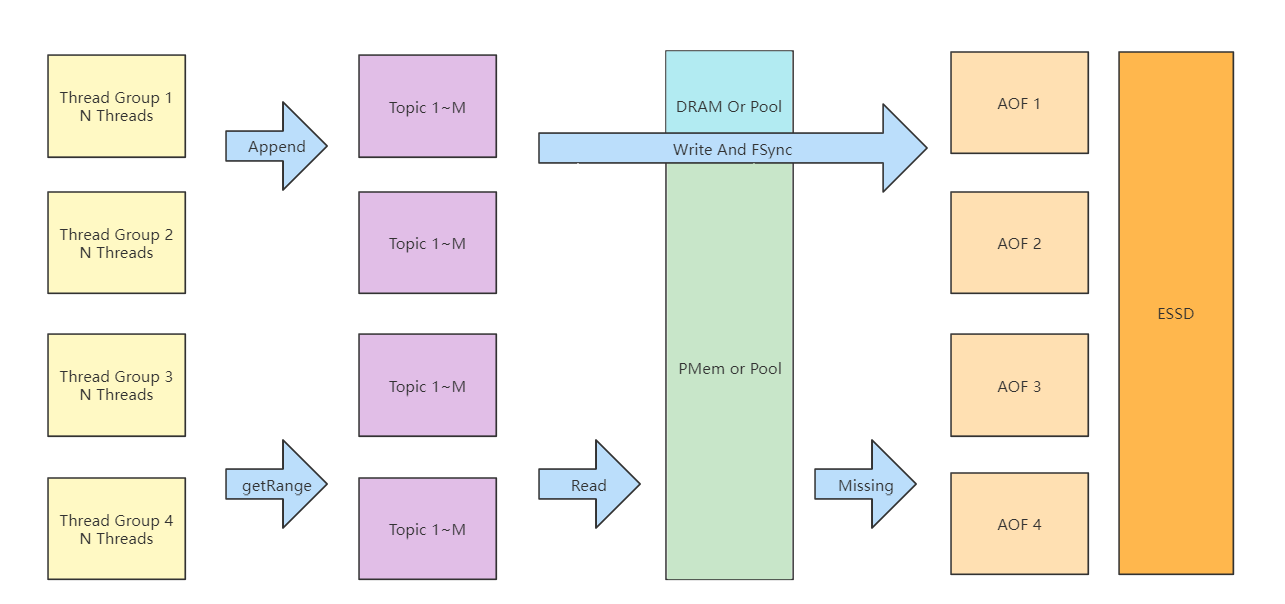
一阶段开始,将所有线程随机分为4组,每组对应1个AOF文件,在写入ESSD的同时,异步写入DRAM或PMem中。理论上在写入 5G + 62G = 67G 数据后缓存用尽,从此刻开始到写满75G之前都只是单纯写硬盘,所有的异步任务也将在此期间全部执行完毕。
二阶段开始,每次读取都会淘汰失效的缓存并放入缓存池中,写入过程中会优先按照记录大小从缓存池中获取到相应的缓存块,理想情况下每次都能申请到对应的缓存块并写入,Missing时记录数据在ESSD上的位置索引。
每次读取时,根据offset从获取对应的数据索引,到索引指定的介质中读取数据并返回。
缓存池
本次赛题一共有DRAM,PMem以及ESSD三种介质,而读写的最小颗粒度为100B-17KiB的数据,我们将之抽象为 Data 类,它提供单个数据读取功能,定义如下:
public abstract class Data {// 缓存块大小protected int capacity;// 数据在文件中开始存储的位置protected long position;// 从介质中读取public abstract void get(ByteBuffer buffer);// 从介质中写入public abstract void set(ByteBuffer buffer);// 从介质中清除public abstract void clear();
}
在一阶段中,会按照写入大小创建对应介质的Data,它记录了这条数据在当前介质中的索引信息(如果是DRAM则直接存放ByteBuffer指针),例如当DRAM和PMem写满时,Data记录的是当前数据在ESSD中的position以及capacity。
二阶段开始时,随着queue的读写会淘汰无效的DRAM和PMem Data并放入对应的缓存池中,二阶段过程中的写入会优先从DRAM缓存池中获取闲置的Data,如果获取失败则从PMem缓存池获取,如果依然失败会降级为SSD Data(相当于不走缓存)。如果获取成功,则将数据写入到当前缓存块中并记录在Queue索引中。
由于二阶段中的缓存块都是从缓存池中获取,因此缓存块大小是固定的,会出现块大小 小于当前写入数据大小的情况,当发生此类情况时,不足的大小会使用预留的堆外内存补救,这块数据被称为 ext,调用clear()方法同时会释放 ext 。
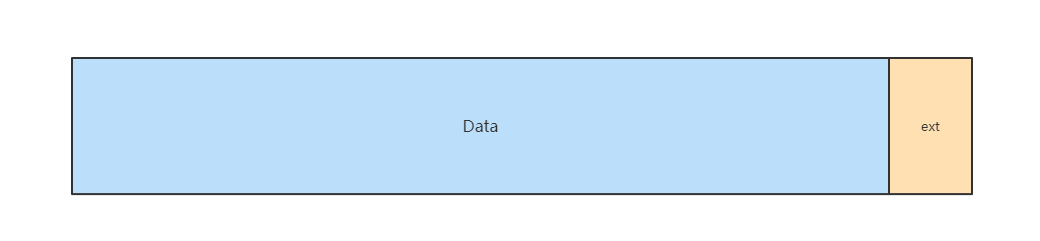
而且,为了减少使用额外的 ext ,缓存池会根据 Data 的capacity大小将之进行分组,当从缓存池获取闲置缓存块时,会根据写入数据的大小到缓存池分组中进行匹配,取出合适区间中的缓存块进行使用。
// 17K / 5 五组内存回收池
public LinkedBlockingQueue<Data> getReadBuffer(int cap){return cap < Const.K * 3.4 ? null : cap < Const.K * 6.8 ? readBuffers2 : cap < Const.K * 10.2 ? readBuffers3 : cap < Const.K * 13.6 ? readBuffers4: readBuffers5;
}
数据索引
程序执行过程中,数据写入后会记录一条索引到具体的queue中,由于offset从0开始并有序的特性,每个queue中会实例化一个 ArrayList 来记录该索引,下标即是offset,value的话则为 Data :
private final List<Data> records;
AOF中的数据格式
由于准确性阶段需要数据的recover,所以直接存储在AOF中的数据需要记录一些额外的索引信息:

当recover时,首先会读取9个Byte来获取头信息,当校验通过后,会根据Data Len来继续读取真实的数据,之后根据TopicId,QueueId,Offset等信息找到目标队列预先建立索引。
文件预分配
根据官方渠道得知,评测环境使用的文件系统为ext4,在ext4文件系统下,每次创建一个物理文件会子啊系统中注册一个inode来记录文件的元数据信息以及block索引树的根节点。
当我们对文件进行读写时,首先会从extent tree中寻找合适的block逻辑地址,再从block中拿到硬盘设备中的物理地址方可操作。如果找不到合适的extent或block则需要创建,此过程还涉及到inode中元数据的变动,对内核代码简单追踪可知,最终会调用 ext4_do_update_inode 方法完成inode的更新。
ext4_write_begin__block_write_beginget_block -> ext4_get_block_unwritten_ext4_get_blockext4_map_blocksext4_ext_map_blocksext4_ext_insert_extentext4_ext_dirtyext4_mark_inode_dirtyext4_mark_iloc_dirty ext4_do_update_inode
其内部实现过程中会先上文件内全局的自旋锁spin_lock(),在设置完新的block并更新inode元数据后调用spin_unlock()解锁,之后处理脏元数据,这个过程需要记录journal日志。
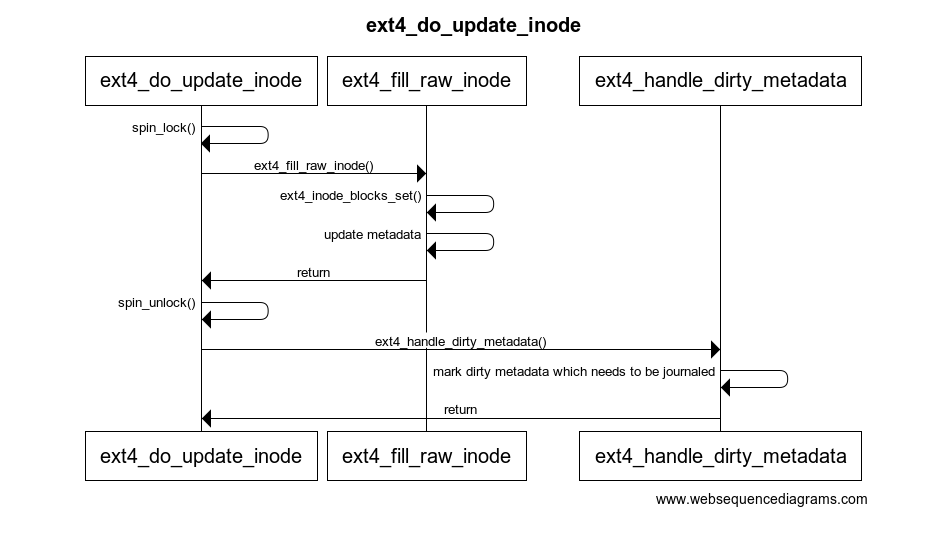
对于一个空文件进行持续的写入,每当 ext4_map_blocks() 获取block失败,就会执行复杂的流程来创建新的逻辑空间到物理空间的block映射,这种开销对于性能的影响是非常致命的,对于分秒必争的比赛更是如此。
为了避免这段开销,我们可以在写入空白文件之前预先写入足够多的数据,让inode预热一下,之后再从position 0开始写入。这种方法称为 预分配 ,Linux中提供 fallocate 命令完成这种操作,在Java中可以手动完成:
void fallocate(FileChannel channel, long allocateSize) throws IOException {if (channel.size() == 0){int batch = (int) (Const.K * 4);int size = (int) (allocateSize / batch);ByteBuffer buffer = ByteBuffer.allocateDirect(batch);for (int i = 0; i < batch; i ++){buffer.put((byte) 0);}for (int i = 0; i < size; i ++){buffer.flip();channel.write(buffer);}channel.force(true);channel.position(0);Utils.recycleByteBuffer(buffer);}}
当然,预分配不是适用于所有场景,本次赛题的计时从第一次append开始,所以有足够的时间在程序初始化过程中完成预分配。再者就是SSD硬盘空间的容量最好足够大,如果容量与要写入的数据相当,预分配后再进行写入时,会导致SSD内部频繁的Foreground GC,性能下降。
4K对齐
传统HDD扇区单位一直习惯于512Byte,有些文件系统默认保留前63个扇区,也就是前512 * 63 / 1024 = 31.5KB,假设闪存Page和簇(OS读写基本单位)都大小为4KB,那么一个Page对应着8个扇区,用户数据将于第8个Page的第3.5KB位置开始写入,导致之后的每一个簇都会跨两个Page,读写处于超界处,这对于闪存会造成更多的读损及读写开销。
除了OS层的4K对齐至关重要以外,在文件写入过程中仍然需要关注4K对齐的问题。假设Page大小仍然为4KB,向一个空白文件写入5KB数据,此时需要2个Page来存储数据,Page 1写满了4KB,而Page2只写入1KB,当再次向文件顺序写入数据时,需要将Page2数据预先读出来,然后与新写入数据在内存中合并后再写入新的Page 3中,之前的Page 2则标记为 stale 等待被GC。这种带来的开销被称为写入放大WA(Write Amplification)。
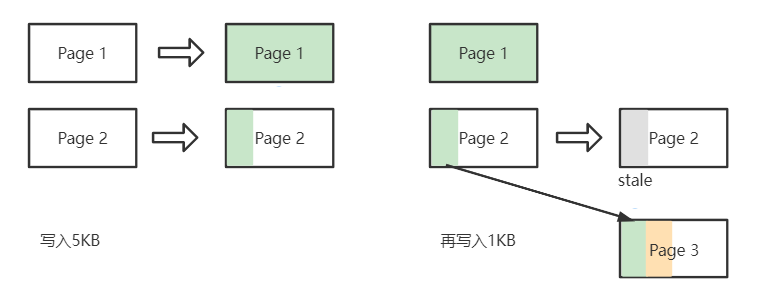
为了减小WA,我们可以人工补充缺少的数据。对于本次赛题,当写入缓冲刷盘前,将写入Buffer的position右移至最近的4KB整数倍点位即可。
预读取
二阶段中,我们需要做的是从queue中获取请求区间所有的 Data ,并根据 Data 中的索引信息将真实数据从对应介质中读取出来,而且这个过程通常是批量的,具体数量由入参 fetchNum 控制。
最开始我使用 Semaphore 对批量数据多线程并发读,并且得到了不错的效果。但是背后却埋着不小的坑,由于每次getRange要频繁的对多个线程阻塞和取消阻塞,线程上下文切换带来开销非常严重,有兴趣的读者可以运行以下测试代码(并把 我不能接受打在弹幕里):
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
import java.util.concurrent.ThreadPoolExecutor;
public class Test {public static void main(String[] args) throws InterruptedException {int count = 100 * 10000;int batch = 1;ThreadPoolExecutor pools = (ThreadPoolExecutor) Executors.newFixedThreadPool(batch);Semaphore semaphore = new Semaphore(0);long start = System.currentTimeMillis();for (int i = 0; i < count; i ++){for (int j = 0; j < batch; j ++){pools.execute(semaphore::release);}semaphore.acquire(batch);}long end = System.currentTimeMillis();System.out.println(end - start);}
}
我不能接受,但是又要保证getRange阶段尽可能并发读取,于是乎我将思路转向了预读取,方法与Page Cache预读类似,举个栗子:当getRange读第0 ~ 10条数据的时候,从线程池中取个线程预读取第10 ~ 20条数据,并将这些数据存储在缓存块中,实际测试中,足够多的PMem缓存块使我们不用担心缓存池匮乏的问题。
顺带一提
- 评测阶段线程数量不固定,好在所有线程几乎同时执行,所以在写入时阻塞一段时间获取到线程数量,之后再对其进行分组。
- 每个线程要持续运行,所以将线程内数据存入ThreadLocal中,并尽可能复用。
- 数据格式中的offset或许可以拿掉,每条记录可以省去4 Byte的空间。
- 两个方法的入参中,Topic的类型为String,但是格式固定为TopicN,可以搞个超大switch方法将其转为int类型,方便之后的存储与读取。
结束
不知不觉,比赛已经结束,写这篇文章的时候明天就要上交的PPT还未开工,这次比赛收获很多,遗憾也不少,收获了很多卷友,遗憾自己未能如心。
从第一个方案出分的惊喜若狂到优化过程中的绞尽脑汁,每一秒的进步都带来了无与伦比的成就感。从为了给女朋友买个电瓶车代步的决心下定开始,仿佛就以注定要在这条道路上一卷无前。
来年,希望张三再发一次橙图(也不一定是橙色),到时候如果我心有余力,肯定很快点进来,然后一键三连。
仓库地址:GitHub - awesome-competitions/tianchi-race-mq-2021: rank 2.
参考
- Ext4
- 持久内存架构与工程实践
- 深入浅出SSD - 固态存储核心技术原理与实战
查看更多内容,欢迎访问天池技术圈官方地址:【参赛总结】第二届云原生编程挑战赛-冷热读写场景的RocketMQ存储系统设计 - Nico_天池技术圈-阿里云天池
这篇关于【参赛总结】第二届云原生编程挑战赛-冷热读写场景的RocketMQ存储系统设计 - Nico的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





