本文主要是介绍书生浦语训练营第2期-第7节笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、为什么要研究大模型的评测?
- 首先,研究评测对于我们全面了解大型语言模型的优势和限制至关重要。尽管许多研究表明大型语言模型在多个通用任务上已经达到或超越了人类水平,但仍然存在质疑,即这些模型的能力是否只是对训练数据的记忆而非真正的理解。例如,即使只提供LeetCode题目编号而不提供具体信息,大型语言模型也能够正确输出答案,这暗示着训练数据可能存在污染现象。
- 其次,研究评测有助于指导和改进人类与大型语言模型之间的协同交互。考虑到大型语言模型的最终服务对象是人类,为了更好地设计人机交互的新范式,我们有必要全面评估模型的各项能力。
- 最后,研究评测可以帮助我们更好地规划大型语言模型未来的发展,并预防未知和潜在的风险。随着大型语言模型的不断演进,其能力也在不断增强。通过合理科学的评测机制,我们能够从进化的角度评估模型的能力,并提前预测潜在的风险,这是至关重要的研究内容。
- 对于大多数人来说,大型语言模型可能似乎与他们无关,因为训练这样的模型成本较高。然而,就像飞机的制造一样,尽管成本高昂,但一旦制造完成,大家使用的机会就会非常频繁。因此,了解不同语言模型之间的性能、舒适性和安全性,能够帮助人们更好地选择适合的模型,这对于研究人员和产品开发者而言同样具有重要意义。
想象一下,你是一名超级英雄,拥有一本神奇的百科全书,里面包含了所有的问题和答案。每当你遇到问题时,只需翻开这本百科全书,就能找到答案。但问题是,你并不知道这些答案是如何得来的。
现在,虽然你可以轻松地回答问题,但是其他人开始质疑你是真的理解了问题还是只是记住了答案。他们担心,如果你只是记住了答案而不是理解问题,那么在面对一些新的、不在百科全书里的问题时,你可能无法给出正确的答案。
为了证明你的能力,人们开始对你进行测试,看看你是否真正理解了问题。他们提出一些与百科全书中的问题类似但不同的问题,以便判断你是否只是背诵了答案。如果你能正确回答这些新问题,那么就能证明你不仅是背诵了答案,而且真正理解了问题。
同样,评估大型语言模型就像对超级英雄进行测试一样。我们想知道这些模型是否真正理解了问题,而不仅仅是背诵了答案。通过评估,我们可以更好地了解这些模型的能力,并确保它们能够在面对新问题时表现良好。
二、OpenCompass介绍
上海人工智能实验室科学家团队正式发布了大模型开源开放评测体系 “司南” (OpenCompass2.0),用于为大语言模型、多模态模型等提供一站式评测服务。其主要特点如下:
- 开源可复现:提供公平、公开、可复现的大模型评测方案
- 全面的能力维度:五大维度设计,提供 70+ 个数据集约 40 万题的的模型评测方案,全面评估模型能力
- 丰富的模型支持:已支持 20+ HuggingFace 及 API 模型
- 分布式高效评测:一行命令实现任务分割和分布式评测,数小时即可完成千亿模型全量评测
- 多样化评测范式:支持零样本、小样本及思维链评测,结合标准型或对话型提示词模板,轻松激发各种模型最大性能
- 灵活化拓展:想增加新模型或数据集?想要自定义更高级的任务分割策略,甚至接入新的集群管理系统?OpenCompass 的一切均可轻松扩展
三、评测对象
本算法库的主要评测对象为语言大模型与多模态大模型。我们以语言大模型为例介绍评测的具体模型类型。
- 基座模型:一般是经过海量的文本数据以自监督学习的方式进行训练获得的模型(如OpenAI的GPT-3,Meta的LLaMA),往往具有强大的文字续写能力。
- 对话模型:一般是在的基座模型的基础上,经过指令微调或人类偏好对齐获得的模型(如OpenAI的ChatGPT、上海人工智能实验室的书生·浦语),能理解人类指令,具有较强的对话能力。
四、工具架构
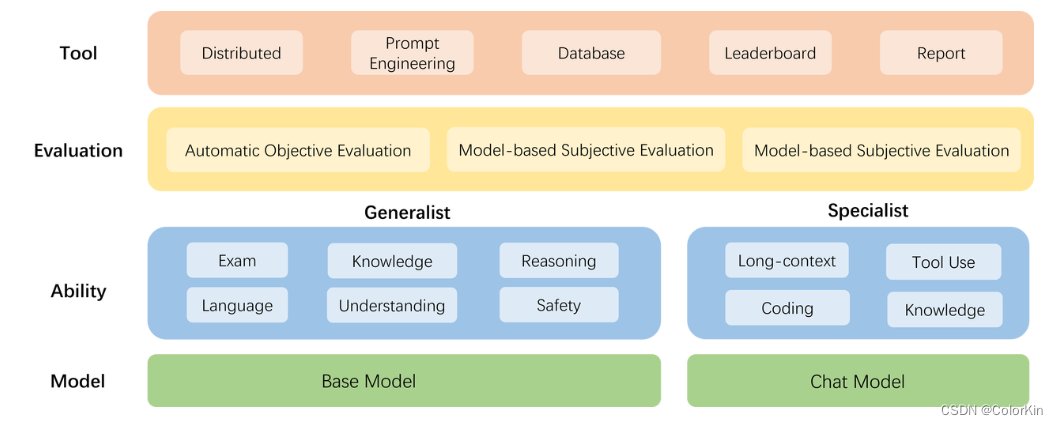
- 模型层:大模型评测所涉及的主要模型种类,OpenCompass 以基座模型和对话模型作为重点评测对象。
- 能力层:OpenCompass 从本方案从通用能力和特色能力两个方面来进行评测维度设计。在模型通用能力方面,从语言、知识、理解、推理、安全等多个能力维度进行评测。在特色能力方面,从长文本、代码、工具、知识增强等维度进行评测。
- 方法层:OpenCompass 采用客观评测与主观评测两种评测方式。客观评测能便捷地评估模型在具有确定答案(如选择,填空,封闭式问答等)的任务上的能力,主观评测能评估用户对模型回复的真实满意度,OpenCompass 采用基于模型辅助的主观评测和基于人类反馈的主观评测两种方式。
- 工具层:OpenCompass 提供丰富的功能支持自动化地开展大语言模型的高效评测。包括分布式评测技术,提示词工程,对接评测数据库,评测榜单发布,评测报告生成等诸多功能。
五、设计思路
为准确、全面、系统化地评估大语言模型的能力,OpenCompass 从通用人工智能的角度出发,结合学术界的前沿进展和工业界的最佳实践,提出一套面向实际应用的模型能力评价体系。OpenCompass 能力维度体系涵盖通用能力和特色能力两大部分。
六、评测方法
6.1 客观评测
针对具有标准答案的客观问题,我们可以通过使用定量指标比较模型的输出与标准答案的差异,并根据结果衡量模型的性能。同时,由于大语言模型输出自由度较高,在评测阶段,我们需要对其输入和输出作一定的规范和设计,尽可能减少噪声输出在评测阶段的影响,才能对模型的能力有更加完整和客观的评价。 为了更好地激发出模型在题目测试领域的能力,并引导模型按照一定的模板输出答案,OpenCompass 采用提示词工程 (prompt engineering)和语境学习(in-context learning)进行客观评测。 在客观评测的具体实践中,我们通常采用下列两种方式进行模型输出结果的评测:
- 判别式评测:该评测方式基于将问题与候选答案组合在一起,计算模型在所有组合上的困惑度(perplexity),并选择困惑度最小的答案作为模型的最终输出。例如,若模型在 问题? 答案1 上的困惑度为 0.1,在 问题? 答案2 上的困惑度为 0.2,最终我们会选择 答案1 作为模型的输出。
- 生成式评测:该评测方式主要用于生成类任务,如语言翻译、程序生成、逻辑分析题等。具体实践时,使用问题作为模型的原始输入,并留白答案区域待模型进行后续补全。我们通常还需要对其输出进行后处理,以保证输出满足数据集的要求。
你是一名年轻的魔法学徒,你的任务是通过问问题来向一本神奇的魔法书询问魔法咒语。但是,这本书有点调皮,有时候它会给出一些奇怪或者错误的答案,所以你需要一种方法来判断哪个答案是正确的。
现在,我们来介绍两种方法来评估这本魔法书的表现:
1. 判别式评测:就像你要向书中询问问题并选择最符合你要求的答案一样。例如,你问书中一个问题:“如何让青蛙变成王子?”书中可能给出两个答案:“用魔法棒”和“唱歌”。然后,你会计算每个答案的可信程度,选择那个让你感觉最合理的答案。
2. 生成式评测:这个评测方法更像是玩一个填空游戏。你会给书中提出一个问题,比如“如果我要变出一只小猫,我应该念什么咒语?”然后,书中会留下一些空白,你需要填入正确的咒语。但是有时候书会给出一些奇怪的答案,比如“香蕉”或者“火箭”,所以你需要一个方法来判断哪个咒语是正确的。
通过这两种评测方法,我们可以更好地了解这本魔法书的表现,并且找出哪些答案是正确的。就像你在选择魔法咒语时一样,我们需要一种方法来判断哪个答案是最合适的,这样我们就可以更好地利用这本神奇的魔法书了!
6.2 主观评测
语言表达生动精彩,变化丰富,大量的场景和能力无法凭借客观指标进行评测。针对如模型安全和模型语言能力的评测,以人的主观感受为主的评测更能体现模型的真实能力,并更符合大模型的实际使用场景。 OpenCompass 采取的主观评测方案是指借助受试者的主观判断对具有对话能力的大语言模型进行能力评测。在具体实践中,我们提前基于模型的能力维度构建主观测试问题集合,并将不同模型对于同一问题的不同回复展现给受试者,收集受试者基于主观感受的评分。由于主观测试成本高昂,本方案同时也采用使用性能优异的大语言模拟人类进行主观打分。在实际评测中,本文将采用真实人类专家的主观评测与基于模型打分的主观评测相结合的方式开展模型能力评估。 在具体开展主观评测时,OpenComapss 采用单模型回复满意度统计和多模型满意度比较两种方式开展具体的评测工作。
你是一位美食评审员,而你的任务是评价一家餐厅的菜品。但是,你会发现有些菜品很难用客观的指标来评价,比如美味程度或者菜品的创意。有时候,你需要依靠自己的感觉和体验来做出评价。
这就好像在评价大型语言模型时一样。有些方面,比如模型的安全性和语言能力,很难用客观指标来衡量。所以,我们需要依靠人们的主观感受来评价模型的真实能力,这更符合实际使用场景。
OpenCompass 采取的主观评测方案就像是你作为美食评审员一样。他们提前准备了一系列问题,然后展示给受试者不同模型对于相同问题的回答,然后收集受试者基于主观感受的评分。由于这种主观测试成本高昂,他们也使用性能优异的大型语言模拟人类来进行主观打分。
在具体的评测中,他们结合了真实人类专家的主观评测和基于模型打分的主观评测。这就像是在评价一家餐厅的菜品时,既依靠专业的美食评审员的意见,又考虑了普通食客的反馈一样。通过这种方式,我们可以更全面地评价大型语言模型的能力。
这篇关于书生浦语训练营第2期-第7节笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








