本文主要是介绍Python3网络爬虫(三):Python3使用Cookie-模拟登陆获取妹子联系方式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转载请注明作者和出处:http://blog.csdn.net/c406495762
运行平台:Windows
Python版本:Python3.x
IDE:Sublime text3
一、为什么要使用Cookie
Cookie,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)。
比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容,登陆前与登陆后是不同的,或者不允许的。
使用Cookie和使用代理IP一样,也需要创建一个自己的opener。在HTTP包中,提供了cookiejar模块,用于提供对Cookie的支持。

http.cookiejar功能强大,我们可以利用本模块的CookieJar类的对象来捕获cookie并在后续连接请求时重新发送,比如可以实现模拟登录功能。该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系: CookieJar–派生–>FileCookieJar–派生–>MozillaCookieJar和LWPCookieJar
工作原理:创建一个带有cookie的opener,在访问登录的URL时,将登录后的cookie保存下来,然后利用这个cookie来访问其他网址。查看登录之后才能看到的信息。
同样,我们以实例进行讲解,爬取伯乐在线的面向对象的漂亮MM的邮箱联系方式。
二、实战
1.背景介绍
在伯乐在线有这么一个有趣的模块,面向对象,它说白了就是提供了一个程序员(媛)网上相亲的平台。
URL:http://date.jobbole.com/
它的样子是这样的:
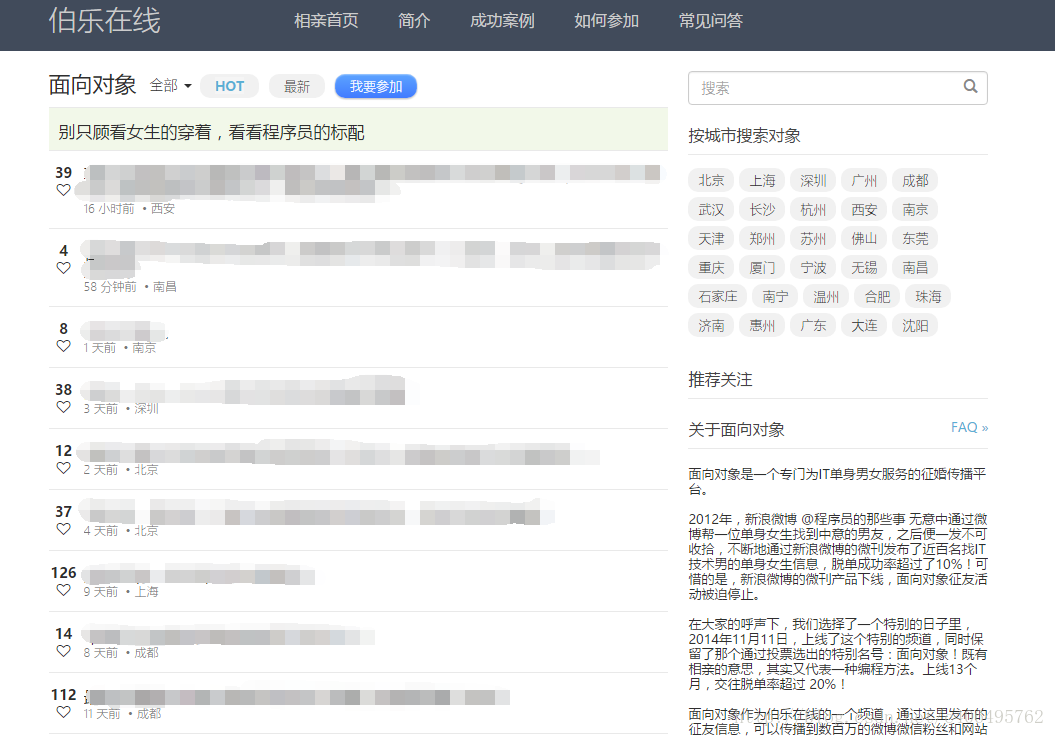
可以看到,这里有很多的相亲贴,随便点进去就会有网上相亲MM的详细信息,想获取MM的联系方式,需要积分,积分可以通过签到的方式获取。如果没有登陆账户,获取联系方式的地方是这个样子的:

如果登陆了账号,获取联系方式的地方是这个样子的:

想要爬取MM的联系邮箱,就需要用到我们本次讲到的知识,Cookie的使用。当然,首先你积分也得够。
在讲解之前,推荐一款抓包工具–Fiddler,可以在Google Chrome的Google商店下载这个插件,它的样子是这样的:
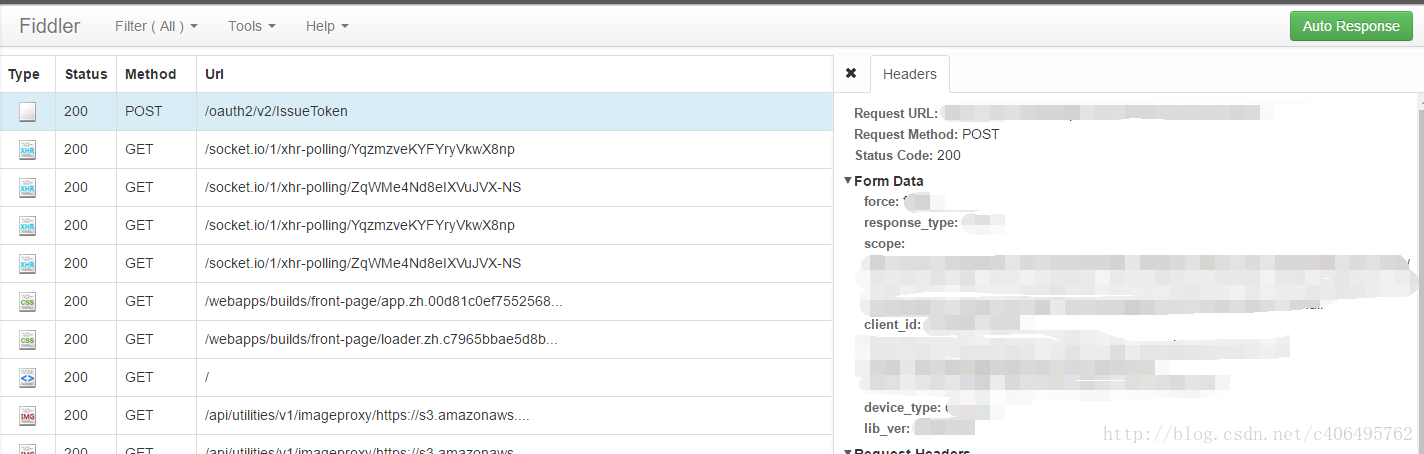
可以看到,通过这个插件,我们可以很容易找到Post的Form Data等信息,很方便,当然也可以用之前讲得浏览器审查元素的方式查看这些信息。
2.过程分析
在伯乐在线首页点击登陆的按钮,Fiddler的抓包内容如下:

从上图可以看出,真正请求的url是
http://www.jobbole.com/wp-admin/admin-ajax.php
Form Data的内容记住,这些是我们编程需要用到的。user_login是用户名,user_pass是用户密码。
在点击取得联系邮箱按钮的时候,Fiddler的抓包内容如下:
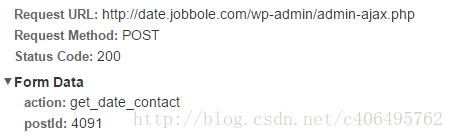
从上图可以看出,此刻真正请求的url是
http://date.jobbole.com/wp-admin/admin-ajax.php
同样Form Data中内容要记下来。postId是每个帖子的id。例如,打开一个相亲贴,它的URL是http://date.jobbole.com/4128/,那么它的这个postId就是4128。为了简化程序,这里就不讲解如何自动获取这个postId了,本实例直接指定postId。如果想要自动获取,可以使用beautifulsoup解析http://date.jobbole.com/返回的信息。beautifulsoup的使用。有机会的话,会在后面的爬虫笔记中进行讲解。
3.测试
1)将Cookie保存到变量中
首先,我们先利用CookieJar对象实现获取cookie的功能,存储到变量中,先来感受一下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
我们使用以上方法将cookie保存到变量中,然后打印出了cookie中的值,运行结果如下:

2)保存Cookie到文件
在上面的方法中,我们将cookie保存到了cookie这个变量中,如果我们想将cookie保存到文件中该怎么做呢?方便以后直接读取文件使用,这时,我们就要用到FileCookieJar这个对象了,在这里我们使用它的子类MozillaCookieJar来实现Cookie的保存,编写代码如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
cookie.save的参数说明:
-
ignore_discard的意思是即使cookies将被丢弃也将它保存下来;
-
ignore_expires的意思是如果在该文件中cookies已经存在,则覆盖原文件写入。
在这里,我们将这两个全部设置为True。
运行之后,cookies将被保存到cookie.txt文件中。我们可以查看自己查看下cookie.txt这个文件的内容。
3)从文件中获取Cookie并访问
我们已经做到把Cookie保存到文件中了,如果以后想使用,可以利用下面的方法来读取cookie并访问网站,感受一下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
了解到以上内容,我们那就可以开始正式编写模拟登陆伯乐在线的程序了。同时,我们也可以获取相亲MM的联系方式。
4.编写代码
我们利用CookieJar对象实现获取cookie的功能,存储到变量中。然后使用这个cookie变量创建opener,使用这个设置好cookie的opener即可模拟登陆,同笔记四中讲到的IP代理的使用方法类似。
创建cookie_test.py文件,编写代码如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
5.运行结果如下:

三、总结
获取成功!如果看过之前的笔记内容,我想这些代码应该很好理解吧。
PS:伯乐在线的面向对象模块就是单身狗的福音!还在犹豫什么?赶快拿起键盘,coding吧!同时,如果您觉得本篇文章对您的学习有所帮助,欢迎关注、评论、顶!
这篇关于Python3网络爬虫(三):Python3使用Cookie-模拟登陆获取妹子联系方式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




