本文主要是介绍HNU-人工智能-实验1-A*算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
人工智能-实验1
计科210x 甘晴void

一、实验目的
-
掌握有信息搜索策略的算法思想;
-
能够编程实现搜索算法;
-
应用A*搜索算法求解罗马尼亚问题。
二、实验平台
- 课程实训平台https://www.educoder.net/shixuns/vgmzcukh/challenges
三、实验内容
3.0 题目要求
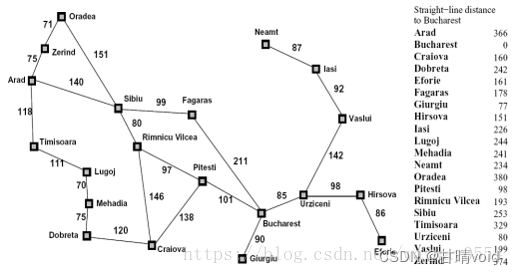
罗马尼亚问题:agent在罗马尼亚度假,目前位于 Arad 城市。agent明天有航班从Bucharest 起飞,不能改签退票。
现在你需要寻找到 Bucharest 的最短路径,在右侧编辑器补充void A_star(int goal,node &src,Graph &graph)函数,使用编写的搜索算法代码求解罗马尼亚问题:
3.1 A*算法原理
A*算法的原理是设计一个代价估计函数:其中 **评估函数F(n)**是从起始节点通过节点n的到达目标节点的最小代价路径的估计值,函数G(n)是从起始节点到n节点的已走过路径的实际代价,函数H(n)是从n节点到目标节点可能的最优路径的估计代价 。
函数 H(n)表明了算法使用的启发信息,它来源于人们对路径规划问题的认识,依赖某种经验估计。根据 F(n)可以计算出当前节点的代价,并可以对下一次能够到达的节点进行评估。
采用每次搜索都找到代价值最小的点再继续往外搜索的过程,一步一步找到最优路径。
3.2 算法实现
根据题目要求,实现A*算法,如下图。
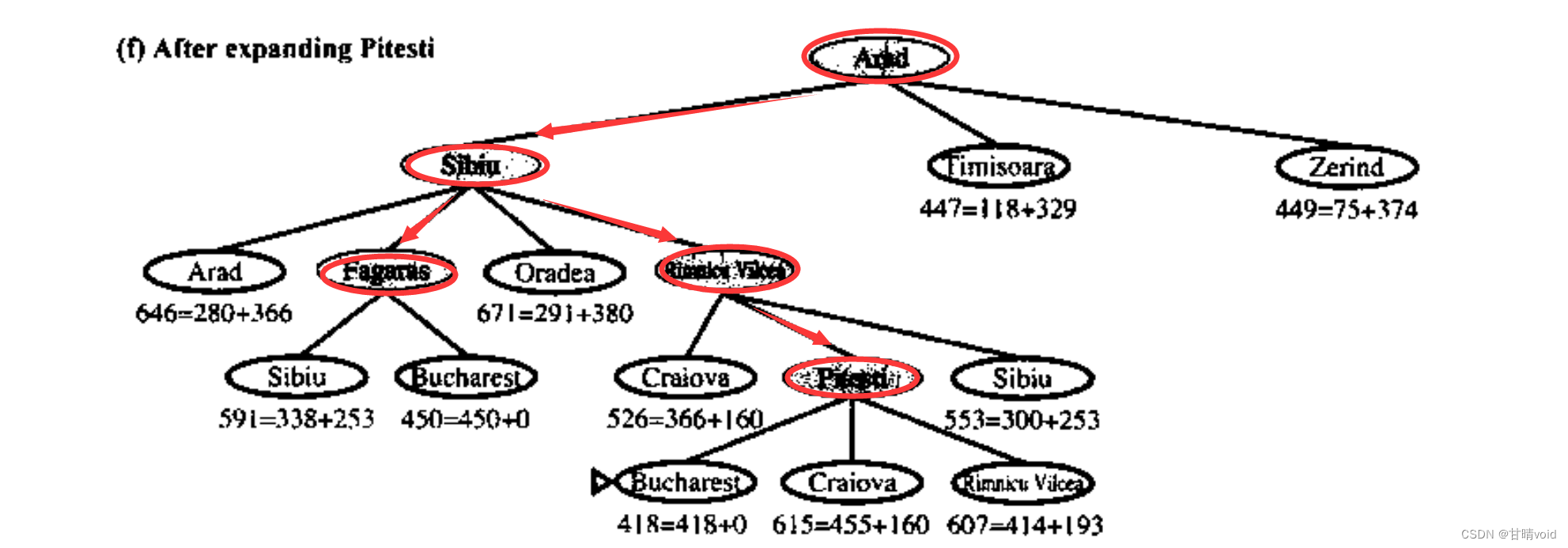
初始给定出发节点,放入openList队列,然后进行扩展操作
- 扩展操作:对于所有与该节点相连的节点,计算它们的g()值,然后加上h()值,得到f()值,并加入openList队列。
- openList队列:该队列本质是一个优先队列,以队列中各元素节点的f()值为键进行排序。给定的程序中使用sort+优先队列来实现,实际上这里直接使用优先队列来进行维护会效率更高,这是可以优化的一个点。
- 选定操作:在扩展,优先化(也就是题中的sort)之后,选定一个f()值最大的作为下一个访问的节点。
- 访问节点:任何节点的访问操作只能进行一次,但是扩展操作可以进行多次(这其实也可以理解,再次访问该节点显然比原来访问该节点的代价高)
- 终止条件:按照上述循环重复执行,直至访问到(不是扩展到)目标终点为止。
基本思路可以用下述伪代码展示
void A_star(int goal, node *src, Graph &graph)
{openList.push_back(src);sort(openList.begin(), openList.end(), cmp);while (!openList.empty()){node *now = new node;now = openList.front();openList.erase(openList.begin());// 选定操作(从优先的openList中获取第一个元素)if (now->name == goal){// 终止条件:到达终点,保存退出return;}for (int i = 0; i < 20; i++){if (graph.getEdge(now->name, i) != -1 && !visited[i])// 有边且未被访问过{node *expand = new node(i, now->g + graph.getEdge(now->name, i), h[i], now);openList.push_back(expand);// 执行扩展操作}}sort(openList.begin(), openList.end(), cmp);// 保证按照键优先化}
}
3.3 源码&分析
#include <algorithm>
#include <iostream>
#include <memory.h>
#include <stack>
#include <vector>
#define A 0
#define B 1
#define C 2
#define D 3
#define E 4
#define F 5
#define G 6
#define H 7
#define I 8
#define L 9
#define M 10
#define N 11
#define O 12
#define P 13
#define R 14
#define S 15
#define T 16
#define U 17
#define V 18
#define Z 19using namespace std;int h[20] ={366, 0, 160, 242, 161,178, 77, 151, 226, 244,241, 234, 380, 98, 193,253, 329, 80, 199, 374};struct node
{int g;int h;int f;int name;node(int name, int g, int h){this->name = name;this->g = g;this->h = h;this->f = g + h;};bool operator<(const node &a) const{return f < a.f;}
};class Graph
{
public:Graph(){memset(graph, -1, sizeof(graph));}int getEdge(int from, int to){return graph[from][to];}void addEdge(int from, int to, int cost){if (from >= 20 || from < 0 || to >= 20 || to < 0)return;graph[from][to] = cost;}void init(){addEdge(O, Z, 71);addEdge(Z, O, 71);addEdge(O, S, 151);addEdge(S, O, 151);addEdge(Z, A, 75);addEdge(A, Z, 75);addEdge(A, S, 140);addEdge(S, A, 140);addEdge(A, T, 118);addEdge(T, A, 118);addEdge(T, L, 111);addEdge(L, T, 111);addEdge(L, M, 70);addEdge(M, L, 70);addEdge(M, D, 75);addEdge(D, M, 75);addEdge(D, C, 120);addEdge(C, D, 120);addEdge(C, R, 146);addEdge(R, C, 146);addEdge(S, R, 80);addEdge(R, S, 80);addEdge(S, F, 99);addEdge(F, S, 99);addEdge(F, B, 211);addEdge(B, F, 211);addEdge(P, C, 138);addEdge(C, P, 138);addEdge(R, P, 97);addEdge(P, R, 97);addEdge(P, B, 101);addEdge(B, P, 101);addEdge(B, G, 90);addEdge(G, B, 90);addEdge(B, U, 85);addEdge(U, B, 85);addEdge(U, H, 98);addEdge(H, U, 98);addEdge(H, E, 86);addEdge(E, H, 86);addEdge(U, V, 142);addEdge(V, U, 142);addEdge(I, V, 92);addEdge(V, I, 92);addEdge(I, N, 87);addEdge(N, I, 87);}private:int graph[20][20];
};bool list[20];
vector<node> openList;
bool closeList[20];
stack<int> road;
int parent[20];void A_star(int goal, node &src, Graph &graph)
{openList.push_back(src);sort(openList.begin(), openList.end());while (!openList.empty()){/********** Begin **********/node now = openList.front();if (now.name == goal)return;openList.erase(openList.begin());closeList[now.name] = 1;for (int i = 0; i < 20; i++){if (graph.getEdge(now.name, i) != -1 && !closeList[i]){node expand(i, now.g + graph.getEdge(now.name, i), h[i]);openList.push_back(expand);int flag = true;for (unsigned int j = 0; j < openList.size(); j++){if (openList[j].name == expand.name && openList[j].g < expand.g){flag = false;}}if (flag == true)parent[i] = now.name;}}sort(openList.begin(), openList.end());/********** End **********/}
}void print_result(Graph &graph)
{int p = openList[0].name;int lastNodeNum;road.push(p);while (parent[p] != -1){road.push(parent[p]);p = parent[p];}lastNodeNum = road.top();int cost = 0;cout << "solution: ";while (!road.empty()){cout << road.top() << "-> ";if (road.top() != lastNodeNum){cost += graph.getEdge(lastNodeNum, road.top());lastNodeNum = road.top();}road.pop();}cout << "end" << endl;cout << "cost:" << cost;
}int main()
{Graph graph;graph.init();for (int i = 0; i < 20; i++)parent[i] = -1;node src(0, 0, h[0]);A_star(1, src, graph);print_result(graph);
}具体分析如下:
- 结构体定义:结构体
node定义了节点的属性,包括节点名称name,从起点到该节点的路径长度g,该节点到目标节点的估计距离h,以及综合路径长度和估计距离的总代价f。重载了小于操作符,以便在优先队列中进行排序。 - 图的表示:使用二维数组
graph[20][20]表示图,数组大小为 20x20,即有 20 个节点。数组中存储了节点之间的边的权值。 - 初始化图:在
Graph类的init()方法中,添加了节点之间的边及对应的权值。 - A*搜索算法:
A_star函数实现了A*搜索算法。它通过优先队列openList来管理待扩展的节点,并且利用数组closeList来记录已经访问过的节点。parent数组用于记录每个节点的父节点,方便后续回溯路径。算法首先将起始节点加入到openList中,并进行排序。然后,循环进行以下步骤:- 取出
openList中的首节点now,如果该节点是目标节点,则搜索结束。 - 将
now加入到closeList中,表示已经访问过。 - 遍历与当前节点相邻的节点,如果相邻节点未被访问过,则将其加入到
openList中,并更新其父节点为当前节点,并根据当前节点到该相邻节点的路径长度以及该节点到目标节点的估计距离计算总代价f。 - 最后对
openList进行排序,以保证优先扩展代价较小的节点。
- 取出
- 打印结果:
print_result函数用于打印搜索结果,即输出找到的最短路径以及路径的总代价。- 将起始节点压入栈中。
- 从目标节点开始,通过
parent数组逐步向上回溯,将经过的节点依次压入栈中,直到回溯到起始节点。 - 在压入栈的过程中,同时计算路径的总代价。因为 A* 算法是一种启发式搜索算法,搜索到的路径并不一定是最优的,但它会在每一步中选择一个启发性最好的节点进行扩展,因此得到的路径一般是较优的。
- 最后,从栈中依次弹出节点,打印出完整的路径,并输出路径的总代价。
- 主函数:在主函数中,首先初始化图,然后调用
A_star函数进行搜索,并最终打印搜索结果。【注意】主函数是在线平台中没有的,在线平台应该指定了程序入口并做了变量初始化的工作。因此我们用主函数来实现这个工作。
综上所述,这段代码实现了使用A*算法在给定图中寻找从起点到目标点的最短路径,并输出了路径以及路径的总代价。
3.4 基于题目的代码:算法分析
时间复杂度可能趋近于O(n^3),主要原因与维护parent数组的最新性有关,这个后面在讲想法的时候会具体说明。
空间复杂度应该有O(n^2),因为使用邻接矩阵来存储图。
3.5 基于题目的代码:困惑思考
基于题目做这道题的时候,我感觉很困惑。
A*算法不是一个非常复杂的算法,但题目中的一些操作让我感觉有点迷。
①parent数组问题
题目使用openList中保存被扩展的节点,然后用closeList来标记被访问的节点,用parent来存储每个节点的父亲这种方式。
这会带来一个挑战:在一个节点被扩展之后,它不一定被立即访问。
如下面这张图,Sibiu节点的四个子节点中,最右子节点Rimnicu Vilcca先被访问,但后来Sibiu的左起第二个子节点Fagaras又被访问到了。此时若该两个子节点都有相同的另一个子节点M,则M可能同时具有Rimnicu Vilcca和Fagaras两个父节点。这样用一个parent数组显然是没办法表示的(注意这里不能是覆盖关系,因为这两个子节点都是“被扩展”的状态而不是“已被访问”的状态,真正被访问的节点有可能从它们之一产生)
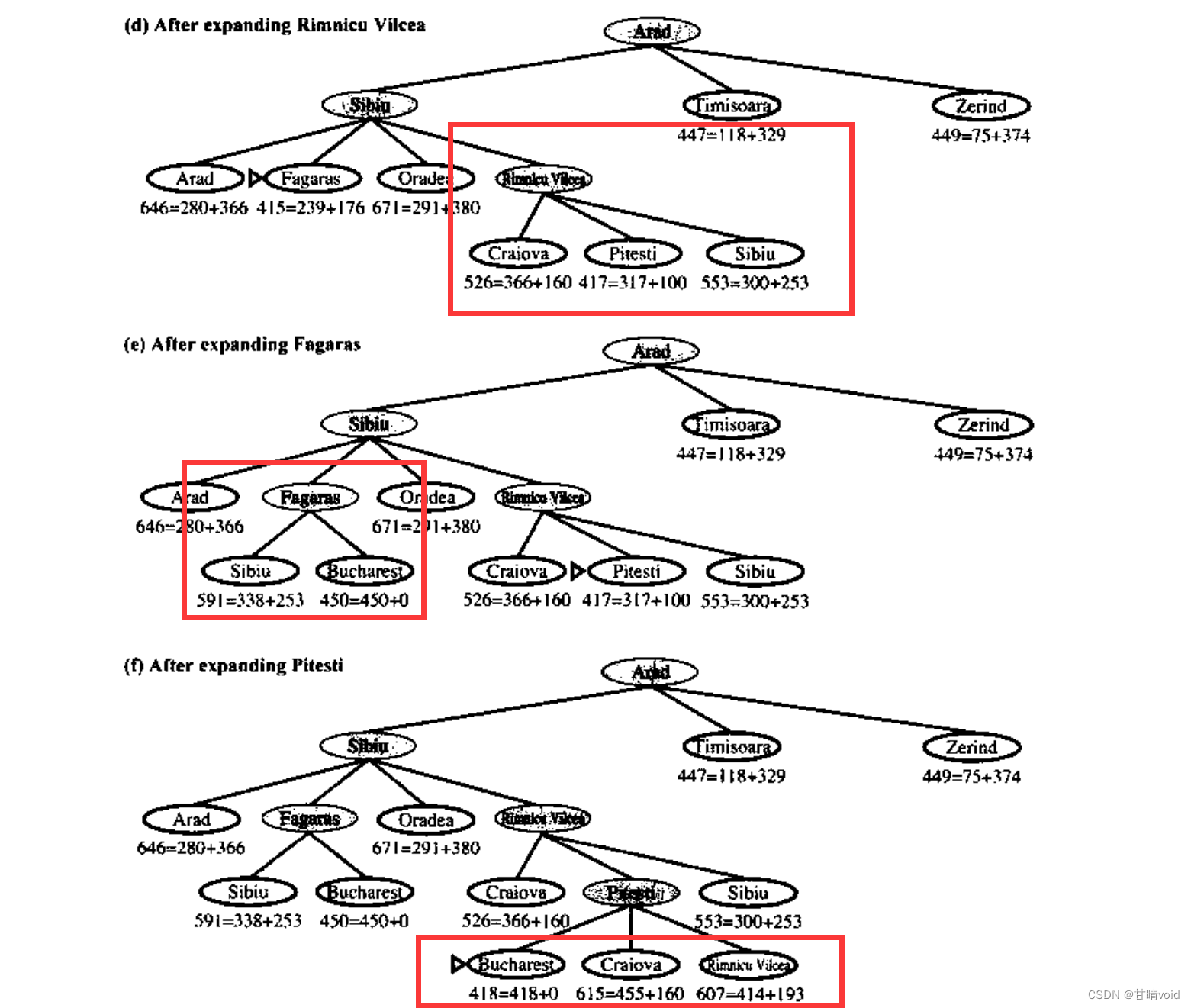
比如,出现下图所示情况。若Bucharest不是最终节点,则它同时又两个parent,这显然无法用一个parent数组存下。
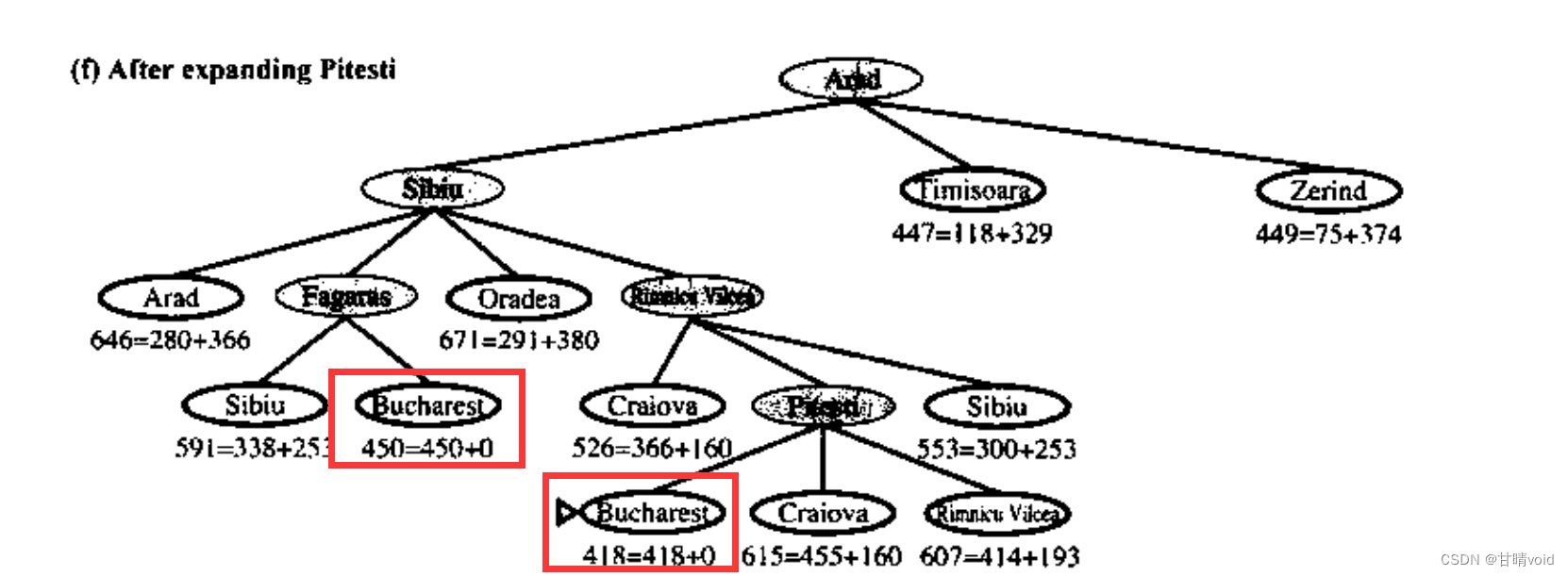
因此理想的方法是将parent作为一个属性写入该节点的node结构体中去。但这样还没解决一个问题,输出结果会有点烦。
或者使用后面改进的方法,直接用指针来作为属性。这样只需要指针走一遍,就可以把顺序给呈现出来了。
但是,原题中我也想办法解决了,其实观察或者是从题目中可以发现,一个节点如果发现有比它g()值更小的节点,实际上g()值较大的那个显然就没有用了,即使予以保留,最终也会在较低优先级而不会被调用(这个实际上看的是f()值,事实上是一样的,因为f()=g()+h(),h()显然只与节点有关系)。故我直接略去g()值较大的节点,默认它们直接被淘汰掉了,parent数组只保存g()值最小的那个所对应的。
②vector+sort替代priority_queue
题目中使用了vector来保存访问节点的结构体,再加上sort来保证优先级,其实可以直接用priority_queue来实现,效率更高。
3.6 改进代码-结构体
只展示核心代码,略去重复的宏定义部分和graph类。
使用结构体和指针绕开了parent数组的问题
#include <algorithm>
#include <iostream>
#include <memory.h>
#include <stack>
#include <vector>
#define A-Z (略)using namespace std;int h[20] ={366, 0, 160, 242, 161,178, 77, 151, 226, 244,241, 234, 380, 98, 193,253, 329, 80, 199, 374};struct node
{int g;int h;int f;int name;node *parent;node() {}node(int name, int g, int h, node *parent){this->name = name;this->g = g;this->h = h;this->f = g + h;this->parent = parent;};bool operator<(const node a) const{return f < a.f;}
};class Graph //(略)vector<node *> openList;
node *des;
bool visited[20];bool cmp(node *a, node *b) { return a->f < b->f; }
void A_star(int goal, node *src, Graph &graph)
{openList.push_back(src);sort(openList.begin(), openList.end(), cmp);while (!openList.empty()){node *now = new node;now = openList.front();openList.erase(openList.begin());visited[now->name] = 1;// cout << now->name << endl;// system("pause");if (now->name == goal){des = now;return;}for (int i = 0; i < 20; i++){if (graph.getEdge(now->name, i) != -1 && !visited[i]){node *expand = new node(i, now->g + graph.getEdge(now->name, i), h[i], now);openList.push_back(expand);// cout << "expand: " << expand->name << endl;}}sort(openList.begin(), openList.end(), cmp);}
}void print_result(Graph &graph)
{cout << "solution: ";stack<int> ans;node *now = des;while (now != NULL){ans.push(now->name);// cout << now->name << endl;now = now->parent;}while (!ans.empty()){cout << ans.top() << "-> ";ans.pop();}cout << "end" << endl;cout << "cost:" << des->g << endl;
}int main()
{Graph graph;graph.init();memset(visited, 0, sizeof(visited));node *src = new node(0, 0, h[0], NULL);A_star(1, src, graph);print_result(graph);
}3.7 改进代码2-<priority_queue>
只需要在上面代码的基础上更改部分即可,但考虑到这里使用的其实是结构体的指针,故重载运算符其实不太好操作。我采取使用比较函数的方法来完成大小的判断。
bool cmp(node *a, node *b) { return a->f > b->f; }
priority_queue<node *, vector<node *>, decltype(&cmp)> openList(&cmp);void A_star(int goal, node *src, Graph &graph)
{openList.push(src);while (!openList.empty()){node *now = new node;now = openList.top();openList.pop();visited[now->name] = 1;// cout << now->name << endl;// system("pause");if (now->name == goal){des = now;return;}for (int i = 0; i < 20; i++){if (graph.getEdge(now->name, i) != -1 && !visited[i]){node *expand = new node(i, now->g + graph.getEdge(now->name, i), h[i], now);openList.push(expand);// cout << "expand: " << expand->name << endl;}}}
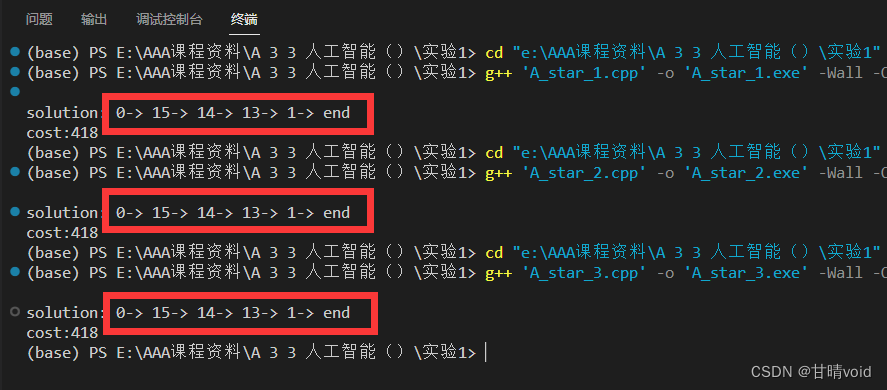
}3.8 运行截图
四、思考题
1:宽度优先搜索,深度优先搜索,一致代价搜索,迭代加深的深度优先搜索算法哪种方法最优?
首先分析这四种算法,
- 宽度优先搜索(BFS):通常在最短路径问题上表现优异,但是空间复杂度很高,因为需要保存所有已经访问的节点。
- 深度优先搜索(DFS):解空间较大,在解相对较浅的问题上可能更有效率,但是可能会陷入无限深度的分支。
- 迭代加深深度优先搜索(IDDFS):结合了DFS和BFS的优点,在不断增加的深度限制上调用深度受限搜索。对于深度搜索问题而言,是一种比较有效的方法。
- 一致代价搜索(UCS):保证在图中搜索的每一步都是最小代价的算法,通常在无启发式的情况下用于解决最短路径问题。
对于一般的问题而言,一致代价搜索是更优的。但对于不同问题要具体问题具体分析,如问题的时间或空间限制等。
2:贪婪最佳优先搜索和A*搜索哪种方法最优?
首先分析这两种算法,
- 贪婪最佳优先搜索:根据启发式函数h()所提供的信息,每次选择看起来最有希望的节点进行扩展,但是它不能保证找到最优解,因为它没有考虑到节点到目标的真实代价。
- A*搜索算法:通过综合考虑节点的实际代价g()和启发式函数h()的估计值,保证了在每一步都能选择到最优的节点进行扩展,从而保证找到最优解。
A*搜索算法通常在需要找到最优解的问题上更为优秀,因为它考虑了实际代价。
3:分析比较无信息搜索策略和有信息搜索策略。
无信息搜索策略和有信息搜索策略是指搜索算法是否利用额外的信息来指导搜索方向:
- 无信息搜索策略,如深度优先搜索(DFS)、宽度优先搜索(BFS)和一致代价搜索(UCS),只利用当前节点的信息进行搜索,不考虑节点到目标的距离或代价,因此可能需要更多的搜索步骤来找到解。
- 有信息搜索策略,如A*搜索算法和贪婪最佳优先搜索,利用启发式函数提供的额外信息(如节点到目标的估计距离)来指导搜索方向,从而更快地找到解。有信息搜索策略通常能更快地找到最优解,但是需要在空间和时间上付出更多的代价来计算和存储启发式函数的值。
这篇关于HNU-人工智能-实验1-A*算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








